
Every enterprise automation program hits the same wall. ServiceNow ticket routing, Terraform drift remediation, certificate rotation, AD group provisioning, SCCM patch deployment, CI/CD pipeline orchestration. The first ten or twenty workflows justify the investment easily, and the ROI math holds up right until the workflow count crosses into the hundreds and a meaningful share of the IT team's week shifts from building new automation to keeping existing automation from falling over.
A payer portal redesigns its auth flow and the claims submission workflow stops authenticating. Salesforce pushes a metadata update and a field mapping in the lead-to-opportunity pipeline starts writing nulls. AWS deprecates an API version and a Terraform plan that ran clean for a year starts throwing 400s on every apply. Someone files a ticket, someone else figures out what changed, patches it, tests it, deploys the fix, and meanwhile the process it was automating either ran manually or didn't run at all.
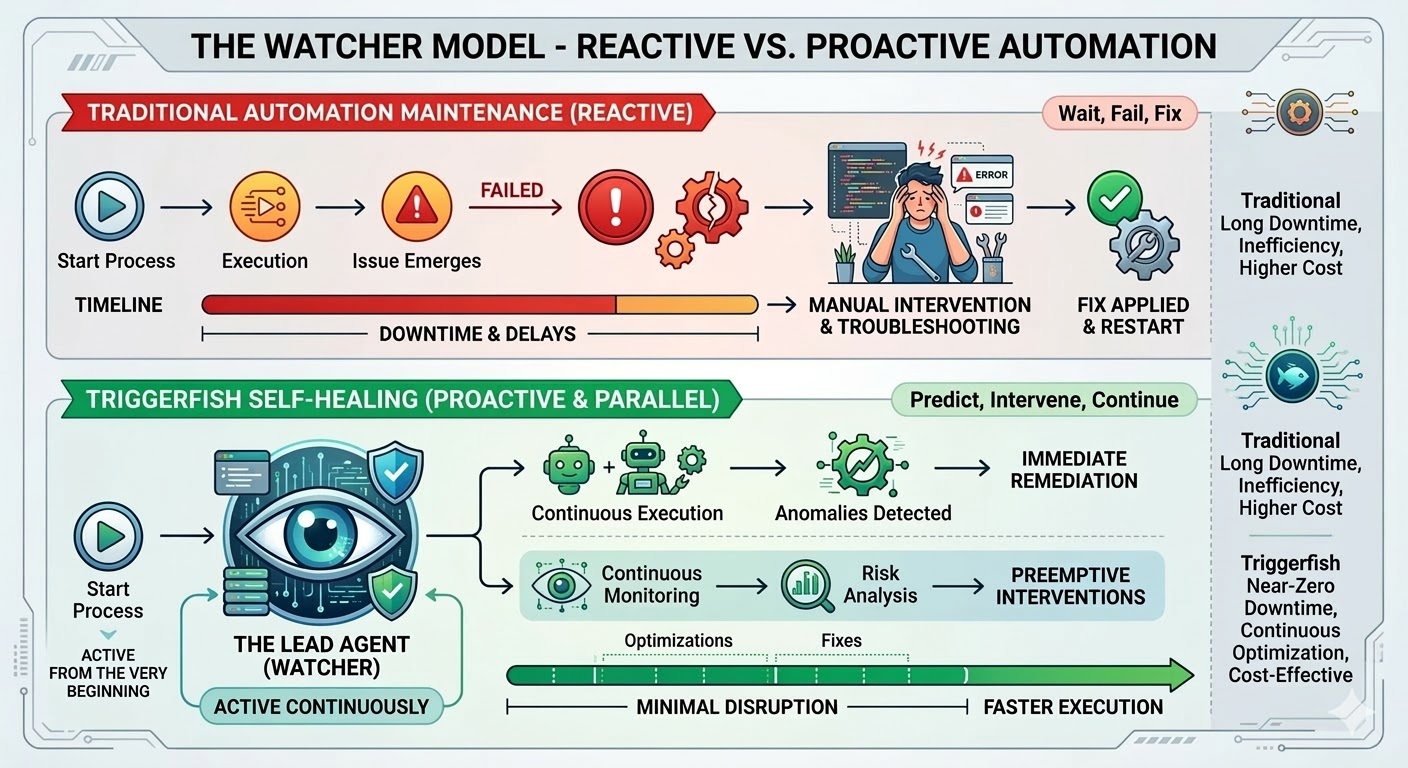
This is the maintenance trap, and it's structural rather than a failure of implementation. Traditional automation follows exact paths, matches exact patterns, and breaks the moment reality deviates from what existed when the workflow was authored. The research is consistent: organizations spend 70 to 75 percent of their total automation program costs not building new workflows but maintaining the ones they already have. In large deployments, 45 percent of workflows break every single week.
Triggerfish's workflow engine was built to change this. Self-healing workflows ship today, and they represent the most significant capability in the platform so far.
What Self-Healing Actually Means
The phrase gets used loosely, so let me be direct about what this is.
When you enable self-healing on a Triggerfish workflow, a lead agent is spawned the moment that workflow starts running. It doesn't launch when something breaks; it's watching from the first step, receiving a live event stream from the engine as the workflow progresses and observing every step in real time.
The lead knows the full workflow definition before a single step runs, including the intent behind every step, what each step expects from the ones before it, and what it produces for the ones after it. It also knows the history of prior runs: what succeeded, what failed, what patches were proposed and whether a human approved or rejected them. When it identifies something worth acting on, all of that context is already in memory because it was watching the whole time rather than reconstructing after the fact.
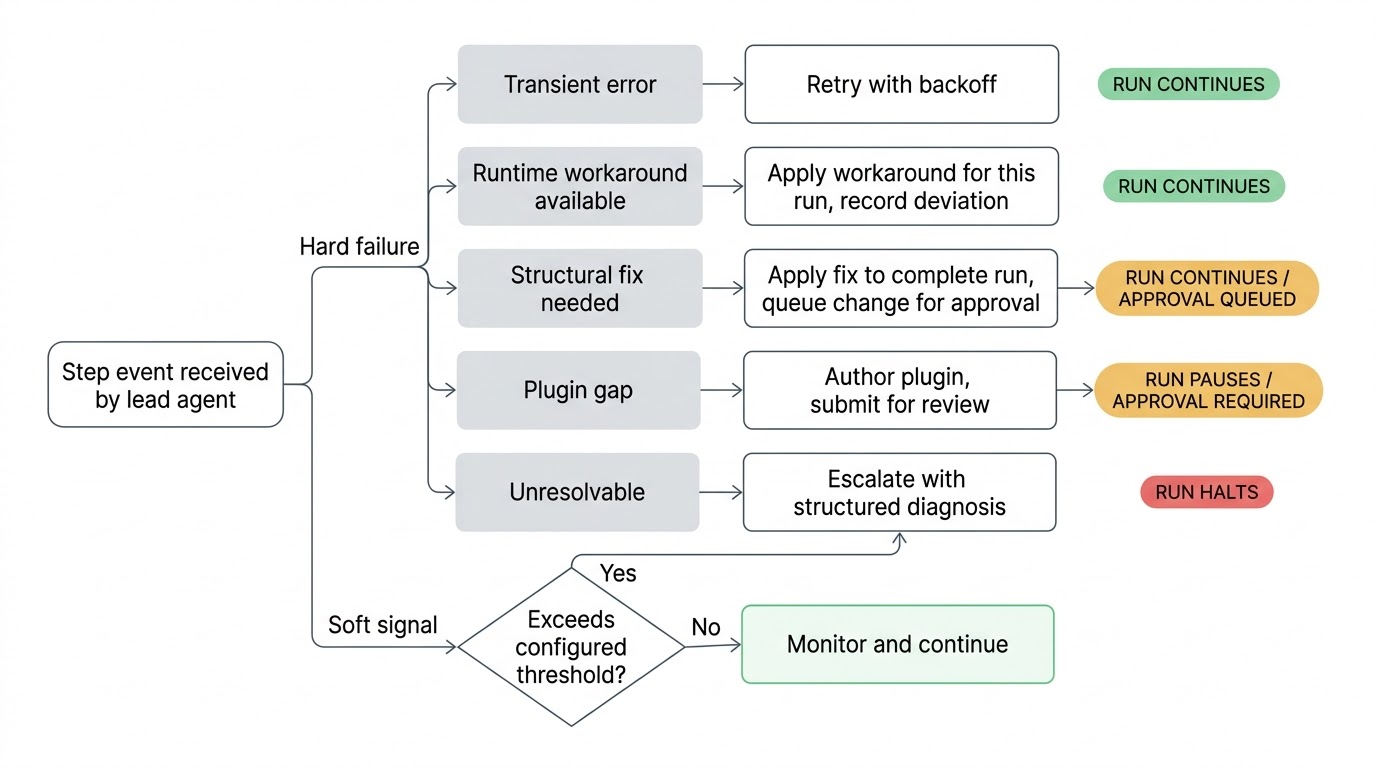
When something goes wrong, the lead triages it. A flaky network call gets a retry with backoff. A changed API endpoint that can be worked around gets worked around for this run. A structural problem in the workflow definition gets a proposed fix applied to complete the run, with the change submitted for your approval before it becomes permanent. A broken plugin integration gets a new or updated plugin authored and submitted for review. If the lead exhausts its attempts and can't resolve the issue, it escalates to you with a structured diagnosis of what it tried and what it thinks the root cause is.
The workflow keeps running whenever it safely can. If a step is blocked, only the downstream steps that depend on it pause while parallel branches continue. The lead knows the dependency graph and only pauses what's actually blocked.
Why the Context You Build Into Workflows Matters
The thing that makes self-healing work in practice is that Triggerfish workflows require rich step-level metadata from the moment you write them. This isn't optional and it isn't documentation for its own sake; it's what the lead agent reasons from.
Every step in a workflow has four required fields beyond the task definition itself: a description of what the step does mechanically, an intent statement explaining why this step exists and what business purpose it serves, an expects field describing what data it assumes it's receiving and what state prior steps must be in, and a produces field describing what it writes to context for downstream steps to consume.
Here's what that looks like in practice. Say you're automating employee access provisioning. A new hire starts Monday and the workflow needs to create accounts in Active Directory, provision their GitHub org membership, assign their Okta groups, and open a Jira ticket confirming completion. One step fetches the employee record from your HR system. Its intent field doesn't just say "get the employee record." It reads: "This step is the source of truth for every downstream provisioning decision. Role, department, and start date from this record determine which AD groups get assigned, which GitHub teams get provisioned, and which Okta policies apply. If this step returns stale or incomplete data, every downstream step will provision the wrong access."

The lead reads that intent statement when the step fails and understands what's at stake. It knows that a partial record means the access provisioning steps will run with bad inputs, potentially granting wrong permissions to a real person starting in two days. That context shapes how it tries to recover, whether it pauses downstream steps, and what it tells you if it escalates.
Another step in the same workflow checks the produces field of the HR fetch step and knows it's expecting .employee.role and .employee.department as non-empty strings. If your HR system updates its API and starts returning those fields nested under .employee.profile.role instead, the lead detects the schema drift, applies a runtime mapping for this run so the new hire gets provisioned correctly, and proposes a structural fix to update the step definition. You didn't write a schema migration rule or exception handling for this specific case. The lead reasoned to it from the context that was already there.
This is why workflow authoring quality matters. The metadata isn't ceremony; it's the fuel the self-healing system runs on. A workflow with shallow step descriptions is a workflow the lead can't reason about when it counts.
Watching Live Means Catching Problems Before They Become Failures
Because the lead is watching in real time, it can act on soft signals before things actually break. A step that historically completes in two seconds is now taking forty. A step that returned data in every prior run returns an empty result. A conditional branch is taken that has never been taken in the full run history. None of these are hard errors and the workflow keeps running, but they're signals that something has changed in the environment. It's better to catch them before the next step tries to consume bad data.
The sensitivity of these checks is configurable per workflow. A nightly report generation might have loose thresholds while an access provisioning pipeline watches closely. You set what level of deviation warrants the lead's attention.
It's Still Your Workflow
The lead agent and its team cannot change your canonical workflow definition without your approval. When the lead proposes a structural fix, it applies the fix to complete the current run and submits the change as a proposal. You see it in your queue, you see the reasoning, you approve or reject it. If you reject it, that rejection is recorded and every future lead working on that workflow knows not to propose the same thing again.
There's one thing the lead can never change regardless of configuration: its own mandate. The self-healing policy in the workflow definition, whether to pause, how long to retry, whether to require approval, is owner-authored policy. The lead can patch task definitions, update API calls, adjust parameters, and author new plugins. It cannot change the rules governing its own behavior. That boundary is hard-coded. An agent that could disable the approval requirement governing its own proposals would make the whole trust model meaningless.
Plugin changes follow the same approval path as any plugin authored by an agent in Triggerfish. The fact that the plugin was authored to fix a broken workflow doesn't give it any special trust. It goes through the same review as if you'd asked an agent to build you a new integration from scratch.
Managing This Across Every Channel You're Already Using
You shouldn't have to log into a separate dashboard to know what your workflows are doing. Self-healing notifications come through wherever you've configured Triggerfish to reach you: an intervention summary on Slack, an approval request on Telegram, an escalation report by email. The system comes to you on the channel that makes sense for the urgency without you refreshing a monitoring console.
The workflow status model is built for this. Status isn't a flat string but a structured object that carries everything a notification needs to be meaningful: the current state, the health signal, whether a patch is in your approval queue, the outcome of the last run, and what the lead is currently doing. Your Slack message can say "the access provisioning workflow is paused, the lead is authoring a plugin fix, approval will be required" in a single notification with no hunting for context.
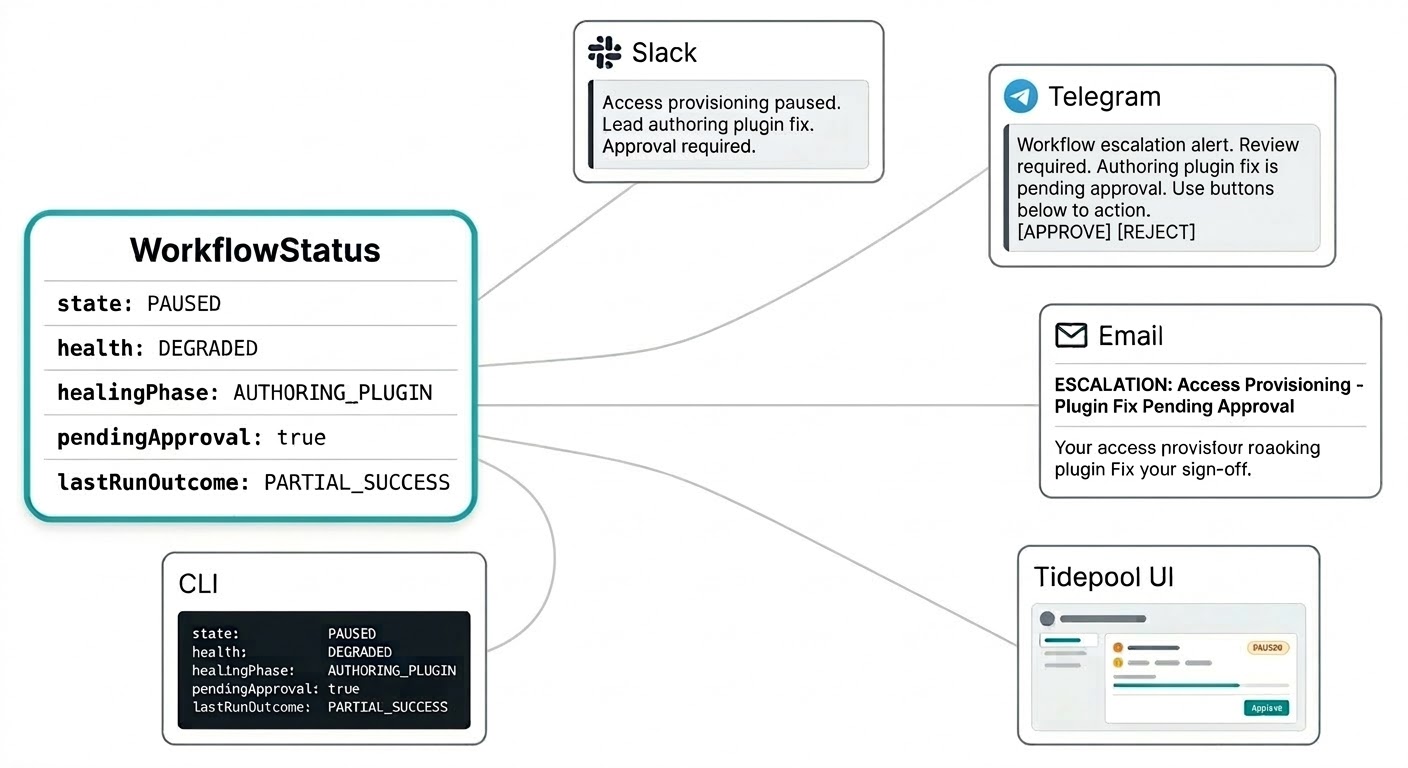
That same structured status feeds the live Tidepool interface when you want the full picture. Same data, different surface.
What This Actually Changes for IT Teams
The people in your organization who spend their week fixing broken workflows are not doing low-skill work. They're debugging distributed systems, reading API changelogs, and reverse-engineering why a workflow that ran fine yesterday is failing today. That's valuable judgment, and right now it's almost entirely consumed by keeping existing automation alive rather than building new automation or solving harder problems.
Self-healing workflows don't eliminate that judgment, but they shift when it gets applied. Instead of firefighting a broken workflow at midnight, you're reviewing a proposed fix in the morning and deciding whether the lead's diagnosis is right. You're the approver of a proposed change, not the author of a patch under pressure.
That's the labor model Triggerfish is built around: humans reviewing and approving agent work rather than executing the work that agents can handle. Automation coverage goes up while maintenance burden goes down, and the team that was spending 75 percent of its time on upkeep can redirect most of that time toward things that actually require human judgment.
Shipping Today
Self-healing workflows ship today as an optional feature in the Triggerfish workflow engine. It's opt-in per workflow, configured in the workflow metadata block. If you don't enable it, nothing changes about how your workflows run.
This matters not because it's a hard technical problem (though it is), but because it directly addresses the thing that has made enterprise automation more expensive and more painful than it needs to be. The workflow maintenance team should be the first job that AI automation takes. That's the right use of this technology, and that's what Triggerfish built.
If you want to dig into how it works, the full spec is in the repository. If you want to try it, the workflow-builder skill will walk you through writing your first self-healing workflow.