
每個企業自動化方案最終都會撞上同一道牆。ServiceNow 工單路由、Terraform 漂移修復、憑證輪換、AD 群組配置、SCCM 修補部署、CI/CD 流水線編排。前十到二十個工作流程很容易就能證明投資的價值,投資報酬率的計算也完全站得住腳——直到工作流程數量突破數百個,IT 團隊每週有相當比例的時間從建構新自動化轉移到維護現有的自動化不讓它們崩潰。
某個支付入口網站重新設計了認證流程,理賠提交工作流程就無法通過驗證了。Salesforce 推送了一個中繼資料更新,潛在客戶轉商機管線中的某個欄位映射開始寫入空值。AWS 棄用了一個 API 版本,一個穩定運行了一年的 Terraform 計畫在每次 apply 時都開始報 400 錯誤。有人提交工單,另一個人找出是什麼變了,修補它,測試它,部署修復程式——而在這段期間,它所自動化的流程不是被手動執行,就是根本沒有執行。
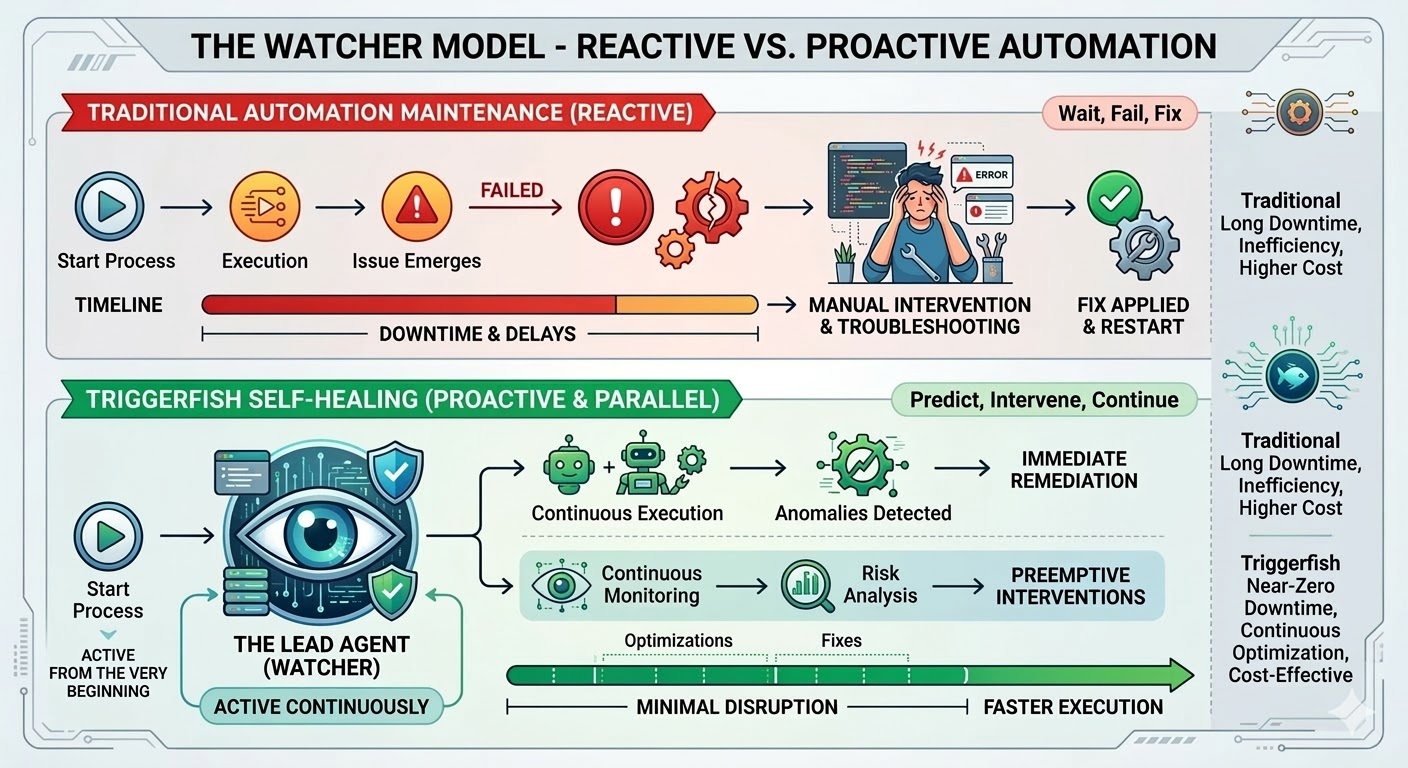
這就是維護陷阱,而且它是結構性的問題,不是實作失敗。傳統的自動化走的是精確路徑、比對精確模式,一旦現實偏離了工作流程編寫時的狀態就會出錯。相關研究的結論非常一致:組織將總自動化方案成本的 70% 到 75% 花在維護既有工作流程上,而不是建構新的工作流程。在大型部署中,每週有 45% 的工作流程會崩潰。
Triggerfish 的工作流程引擎就是為了改變這個局面而打造的。自我修復工作流程今天正式發布,這是平台迄今為止最重要的功能。
自我修復的真正含義
這個詞經常被隨意使用,所以讓我直接說明這到底是什麼。
當你在 Triggerfish 工作流程上啟用自我修復時,一個領導代理會在該工作流程開始執行的那一刻被生成。它不是在出問題時才啟動;它從第一步就在監控,接收引擎的即時事件流,在工作流程推進的同時即時觀察每一個步驟。
這個領導代理在任何步驟執行之前就知道完整的工作流程定義,包括每個步驟背後的意圖、每個步驟對前序步驟的期望,以及它為後續步驟產生什麼輸出。它也知道歷次執行的記錄:哪些成功了、哪些失敗了、提出了哪些修補方案、人類是批准還是駁回了它們。當它識別到值得處理的情況時,所有這些上下文都已經在記憶體中了,因為它一直在監控而不是事後重建。
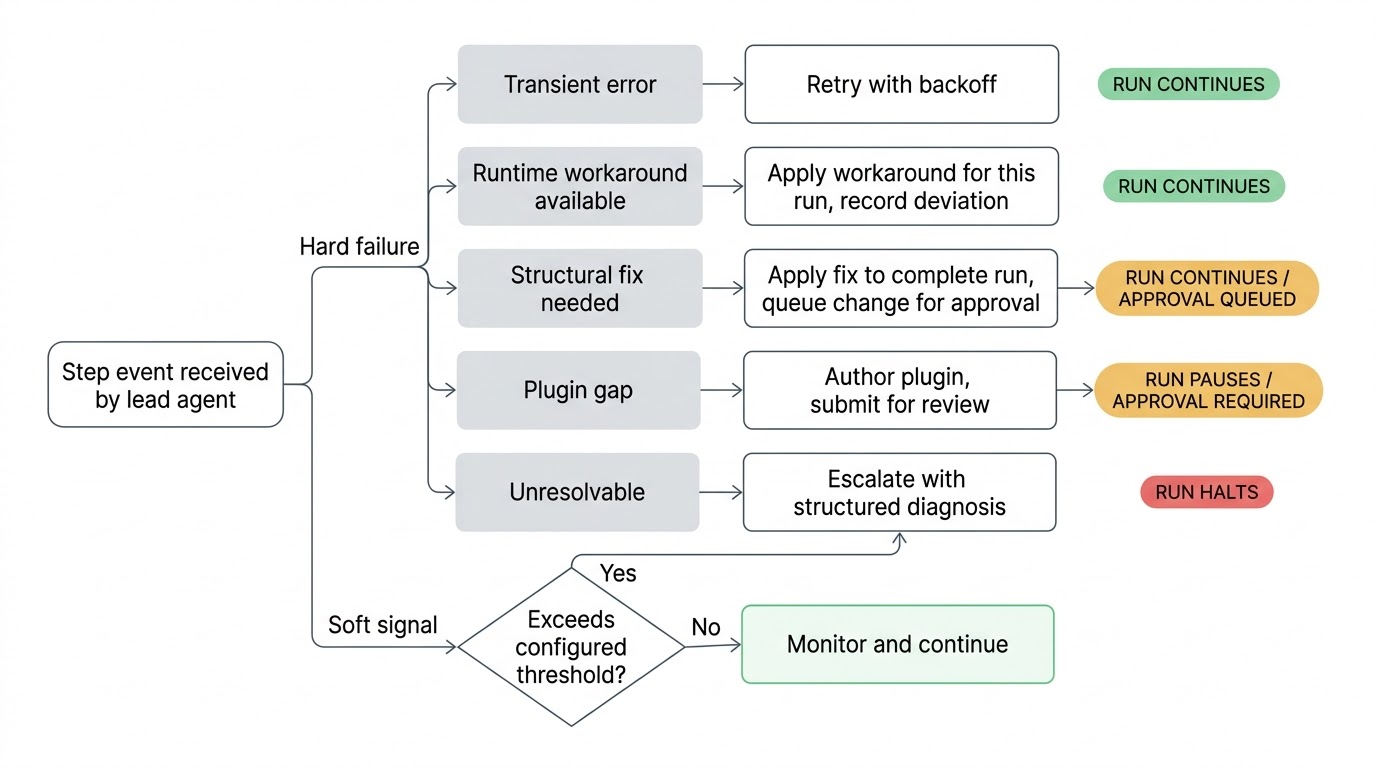
當出現問題時,領導代理會進行分類處理。不穩定的網路呼叫會以指數退避重試。一個變更過的 API 端點如果可以繞過去,就在這次執行中繞過。工作流程定義中的結構性問題會被提出修復方案,套用以完成本次執行,但該變更會提交給你審核才會成為永久性的修改。損壞的外掛整合會由代理撰寫新的或更新的外掛並提交審查。如果領導代理用盡所有嘗試仍無法解決問題,它會向你升級通報,附上一份結構化的診斷報告,說明它嘗試了什麼以及它認為的根本原因是什麼。
工作流程在安全可行的情況下會繼續執行。如果某個步驟被阻塞,只有依賴它的下游步驟會暫停,而並行分支繼續運行。領導代理了解依賴關係圖,只會暫停真正被阻塞的部分。
為什麼你建入工作流程的上下文很重要
讓自我修復在實務中真正發揮作用的關鍵在於:Triggerfish 工作流程從你編寫的那一刻起就要求豐富的步驟級中繼資料。這不是可選的,也不是為了寫文件而寫;這是領導代理進行推理的依據。
工作流程中的每個步驟除了任務定義本身,還有四個必填欄位:一個描述步驟在機制上做了什麼的說明、一個解釋這個步驟為什麼存在以及它服務什麼業務目的的意圖聲明、一個描述它預期接收什麼資料以及前序步驟必須處於什麼狀態的 expects 欄位,以及一個描述它為下游步驟寫入上下文什麼內容的 produces 欄位。
以下是實際的樣子。假設你在自動化員工存取權限配置。一位新員工週一入職,工作流程需要在 Active Directory 中建立帳號、配置他們的 GitHub 組織成員資格、指派他們的 Okta 群組,以及開一張 Jira 工單確認完成。其中一個步驟從你的 HR 系統取得員工記錄。它的 intent 欄位不只是寫「取得員工記錄」。它的內容是:「這個步驟是所有下游配置決策的唯一事實來源。此記錄中的角色、部門和入職日期決定了要指派哪些 AD 群組、配置哪些 GitHub 團隊,以及套用哪些 Okta 政策。如果這個步驟回傳過時或不完整的資料,每個下游步驟都會配置錯誤的存取權限。」

領導代理在步驟失敗時讀取那份意圖聲明,並理解問題的嚴重性。它知道不完整的記錄意味著存取權限配置步驟會使用錯誤的輸入來執行,可能對一個兩天後就要入職的真實員工授予錯誤的權限。這個上下文影響了它如何嘗試恢復、是否暫停下游步驟,以及如果需要升級通報時它會告訴你什麼。
同一個工作流程中的另一個步驟檢查 HR 取得步驟的 produces 欄位,知道它期望 .employee.role 和 .employee.department 是非空字串。如果你的 HR 系統更新了 API,開始把這些欄位巢狀在 .employee.profile.role 底下回傳,領導代理會偵測到結構漂移,在本次執行中套用一個即時映射,確保新員工被正確配置,然後提出一個結構性修復建議來更新步驟定義。你並沒有為這個特定情況撰寫結構遷移規則或例外處理。領導代理是從既有的上下文中推理出來的。
這就是為什麼工作流程的編寫品質很重要。中繼資料不是形式主義;它是自我修復系統運行的燃料。一個步驟描述膚淺的工作流程,就是一個在關鍵時刻領導代理無法進行推理的工作流程。
即時監控意味著在問題變成故障之前就捕捉到
因為領導代理是即時監控的,它可以在事情真正崩潰之前就對微弱訊號採取行動。一個歷來兩秒完成的步驟現在花了四十秒。一個在以往每次執行都回傳資料的步驟回傳了空結果。一個在完整執行歷史中從未進入過的條件分支被觸發了。這些都不是硬錯誤,工作流程繼續執行——但它們是環境發生了變化的訊號。在下一個步驟嘗試消費壞資料之前捕捉到它們會更好。
這些檢查的靈敏度可以按工作流程配置。每夜的報表生成可能有寬鬆的閾值,而存取權限配置的管線則會嚴密監控。你可以設定什麼程度的偏差值得引起領導代理的注意。
這仍然是你的工作流程
領導代理及其團隊未經你的批准不能更改你的標準工作流程定義。當領導代理提出結構性修復時,它會套用修復以完成當前執行,並將變更作為提案提交。你會在你的待審佇列中看到它,看到推理過程,然後批准或駁回。如果你駁回了,該駁回會被記錄,未來每個處理該工作流程的領導代理都知道不要再提出同樣的建議。
有一件事是領導代理無論在什麼配置下都絕不能更改的:它自己的職責範圍。工作流程定義中的自我修復政策——是否暫停、重試多久、是否需要審批——這些都是擁有者制定的政策。領導代理可以修補任務定義、更新 API 呼叫、調整參數、撰寫新的外掛。它不能更改管控自身行為的規則。這個邊界是硬編碼的。一個能夠停用管控其自身提案審批要求的代理,會讓整個信任模型失去意義。
外掛變更遵循與 Triggerfish 中代理撰寫的任何外掛相同的審批路徑。外掛是為了修復損壞的工作流程而撰寫的這一事實,不會賦予它任何特殊信任。它的審查流程與你從頭要求代理建構一個新整合時完全相同。
透過你已經在使用的每個頻道來管理
你不應該需要登入一個獨立的儀表板來了解你的工作流程正在做什麼。自我修復通知會透過你已配置 Triggerfish 聯繫你的任何管道送達:Slack 上的介入摘要、Telegram 上的審批請求、電子郵件的升級報告。系統會根據緊急程度在合適的頻道找到你,不需要你不斷重新整理監控控制台。
工作流程狀態模型就是為此而設計的。狀態不是一個簡單的字串,而是一個結構化物件,攜帶通知所需的所有有意義的資訊:當前狀態、健康訊號、是否有修補方案在你的審批佇列中、上次執行的結果,以及領導代理目前正在做什麼。你的 Slack 訊息可以在一則通知中說「存取權限配置工作流程已暫停,領導代理正在撰寫外掛修復,需要審批」,不需要到處翻找上下文。
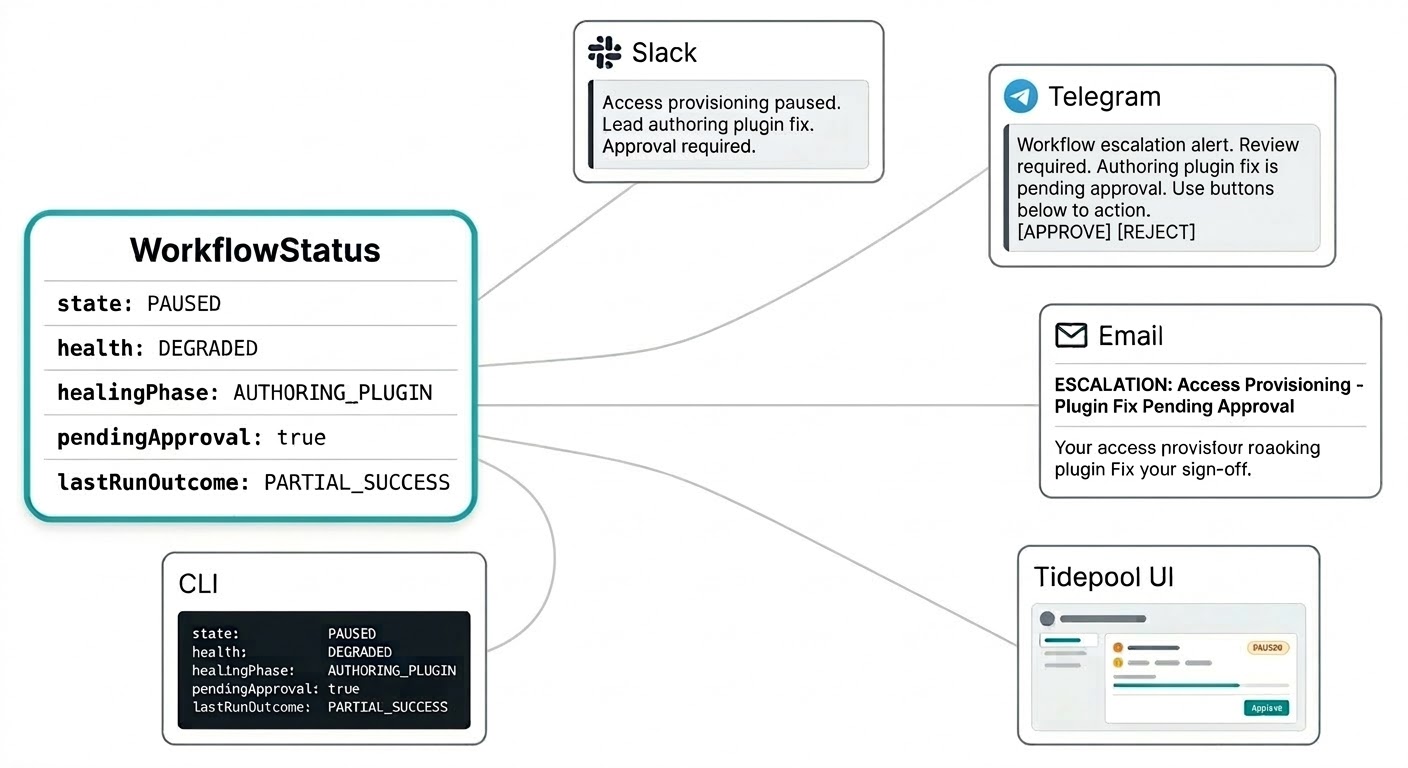
當你需要完整全貌時,同樣的結構化狀態也會呈現在 Tidepool 即時介面上。相同的資料,不同的呈現方式。
這對 IT 團隊的實際改變
在你的組織中花費一整週修復損壞工作流程的人並不是在做低技術含量的工作。他們在除錯分散式系統、閱讀 API 變更日誌、逆向工程為什麼昨天還正常運行的工作流程今天就失敗了。那是寶貴的判斷力,而目前它幾乎完全被消耗在維護既有自動化的運作上,而不是建構新的自動化或解決更困難的問題。
自我修復工作流程不會消除那種判斷力,但它改變了判斷力被運用的時機。你不再是在半夜搶修一個崩潰的工作流程,而是在早上審查一個提出的修復方案,判斷領導代理的診斷是否正確。你是一個變更提案的審批者,而不是在壓力下趕工修補的作者。
這就是 Triggerfish 所圍繞的勞動模式:人類審查和批准代理的工作,而不是執行代理能夠處理的工作。自動化覆蓋率上升而維護負擔下降,原本花費 75% 時間在維運的團隊可以將大部分時間重新導向真正需要人類判斷的事務。
今天正式發布
自我修復工作流程今天作為 Triggerfish 工作流程引擎的可選功能正式發布。它是按工作流程自行選擇啟用的,在工作流程的中繼資料區塊中配置。如果你不啟用它,你的工作流程的執行方式不會有任何改變。
這件事之所以重要,不是因為它是一個困難的技術問題(雖然確實是),而是因為它直接解決了讓企業自動化變得比應有水準更昂貴、更痛苦的根本原因。工作流程維護團隊應該是 AI 自動化取代的第一個職位。這是這項技術的正確用途,也是 Triggerfish 所打造的。
如果你想深入了解它的運作方式,完整規格在程式碼儲存庫中。如果你想試用,workflow-builder 技能會引導你編寫你的第一個自我修復工作流程。