
Todo programa de automatización empresarial se topa con la misma pared. Enrutamiento de tickets en ServiceNow, remediación de drift en Terraform, rotación de certificados, aprovisionamiento de grupos en Active Directory, despliegue de parches con SCCM, orquestación de pipelines de CI/CD. Los primeros diez o veinte workflows justifican la inversión fácilmente, y las cuentas del ROI cuadran bien hasta que la cantidad de workflows cruza los cientos y una parte significativa de la semana del equipo de TI pasa de construir nueva automatización a evitar que la automatización existente se caiga.
Un portal de pagos rediseña su flujo de autenticación y el workflow de envío de reclamaciones deja de autenticarse. Salesforce empuja una actualización de metadatos y un mapeo de campos en el pipeline de lead-a-oportunidad empieza a escribir nulos. AWS depreca una versión de API y un plan de Terraform que corrió limpio durante un año empieza a lanzar errores 400 en cada apply. Alguien abre un ticket, alguien más averigua qué cambió, lo parcha, lo prueba, despliega la corrección, y mientras tanto el proceso que se estaba automatizando se ejecutó manualmente o simplemente no se ejecutó.
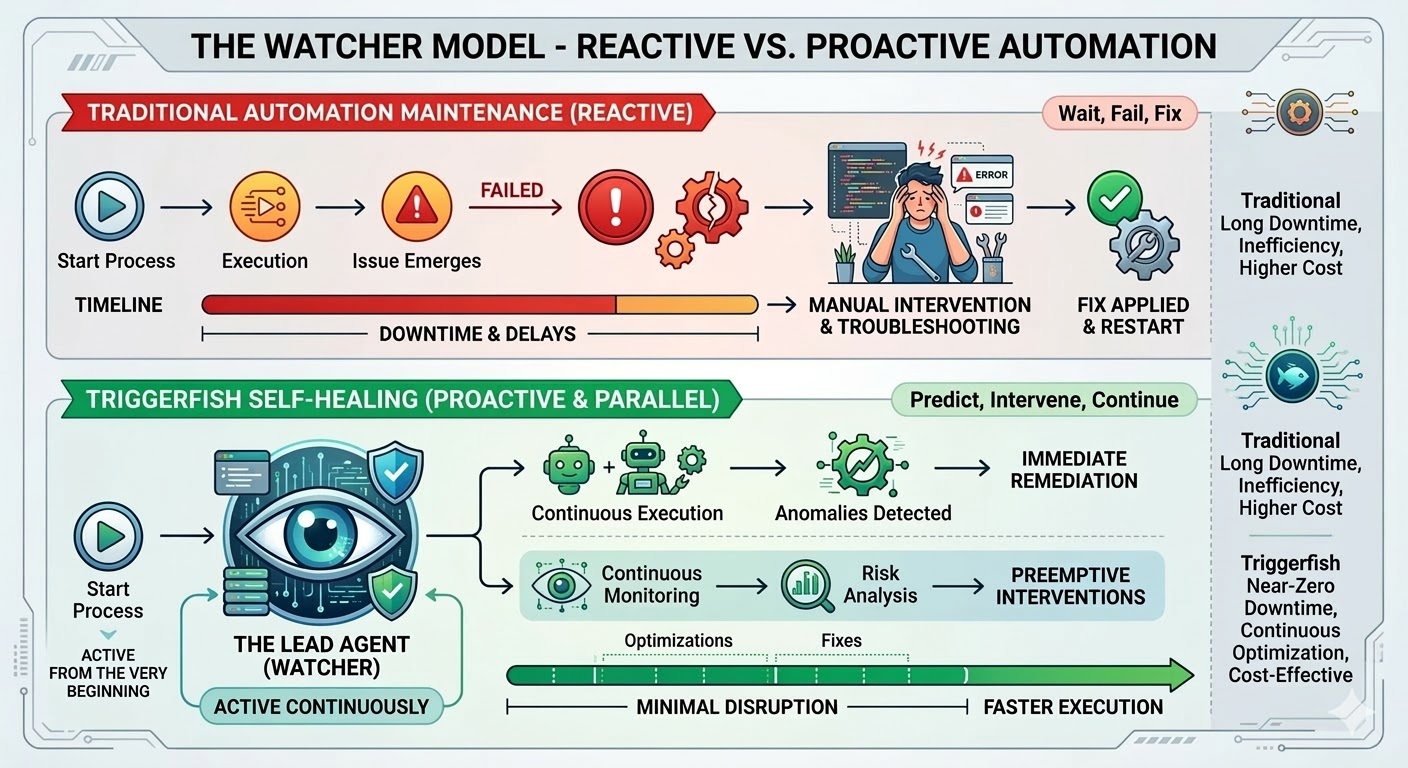
Esta es la trampa del mantenimiento, y es estructural, no una falla de implementación. La automatización tradicional sigue rutas exactas, coincide con patrones exactos y se rompe en el momento en que la realidad se desvía de lo que existía cuando se creó el workflow. La investigación es consistente: las organizaciones gastan entre el 70 y el 75 por ciento de los costos totales de su programa de automatización no en construir nuevos workflows, sino en mantener los que ya tienen. En despliegues grandes, el 45 por ciento de los workflows se rompen cada semana.
El motor de workflows de Triggerfish se construyó para cambiar esto. Los workflows de autorreparación se lanzan hoy, y representan la capacidad más significativa de la plataforma hasta ahora.
Qué significa realmente la autorreparación
La frase se usa con ligereza, así que voy a ser directo sobre lo que esto es.
Cuando activan la autorreparación en un workflow de Triggerfish, se genera un agente líder en el momento en que ese workflow comienza a ejecutarse. No se lanza cuando algo falla; está observando desde el primer paso, recibiendo un flujo de eventos en vivo del motor mientras el workflow avanza y observando cada paso en tiempo real.
El agente líder conoce la definición completa del workflow antes de que se ejecute un solo paso, incluyendo la intención detrás de cada paso, qué espera cada paso de los anteriores y qué produce para los siguientes. También conoce el historial de ejecuciones previas: qué tuvo éxito, qué falló, qué parches se propusieron y si un humano los aprobó o rechazó. Cuando identifica algo que amerita acción, todo ese contexto ya está en memoria porque estuvo observando todo el tiempo en lugar de reconstruir después del hecho.
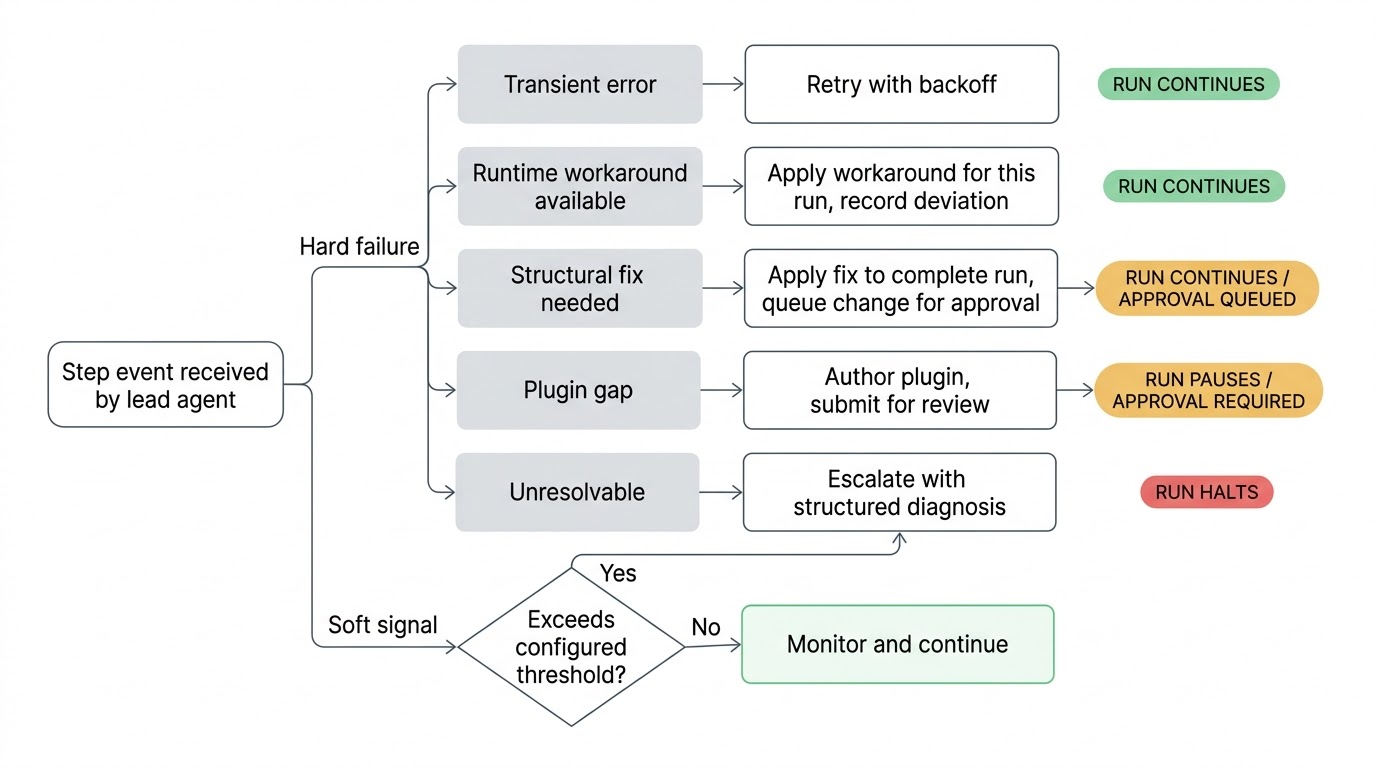
Cuando algo sale mal, el agente líder hace el triaje. Una llamada de red inestable recibe un reintento con backoff. Un endpoint de API que cambió y se puede sortear, se sortea para esta ejecución. Un problema estructural en la definición del workflow recibe una corrección propuesta que se aplica para completar la ejecución, y el cambio se envía para su aprobación antes de que se vuelva permanente. Una integración de plugin rota recibe un plugin nuevo o actualizado, escrito y enviado para revisión. Si el agente líder agota sus intentos y no puede resolver el problema, lo escala hacia ustedes con un diagnóstico estructurado de lo que intentó y lo que cree que es la causa raíz.
El workflow sigue ejecutándose siempre que sea seguro hacerlo. Si un paso está bloqueado, solo los pasos dependientes se pausan mientras las ramas paralelas continúan. El agente líder conoce el grafo de dependencias y solo pausa lo que realmente está bloqueado.
Por qué importa el contexto que incluyen en los workflows
Lo que hace que la autorreparación funcione en la práctica es que los workflows de Triggerfish requieren metadatos ricos a nivel de paso desde el momento en que los escriben. Esto no es opcional y no es documentación por documentar; es de donde el agente líder razona.
Cada paso en un workflow tiene cuatro campos requeridos más allá de la definición de la tarea en sí: una descripción de lo que el paso hace mecánicamente, una declaración de intención que explica por qué existe este paso y qué propósito de negocio cumple, un campo expects que describe qué datos asume que está recibiendo y en qué estado deben estar los pasos previos, y un campo produces que describe qué escribe en el contexto para que los pasos siguientes lo consuman.
Así se ve en la práctica. Digamos que están automatizando el aprovisionamiento de acceso para empleados. Un nuevo empleado empieza el lunes y el workflow necesita crear cuentas en Active Directory, aprovisionar su membresía en la organización de GitHub, asignar sus grupos de Okta y abrir un ticket en Jira confirmando la finalización. Un paso obtiene el registro del empleado del sistema de recursos humanos. Su campo de intención no dice simplemente "obtener el registro del empleado". Dice: "Este paso es la fuente de verdad para todas las decisiones de aprovisionamiento posteriores. El rol, departamento y fecha de inicio de este registro determinan qué grupos de Active Directory se asignan, qué equipos de GitHub se aprovisionan y qué políticas de Okta aplican. Si este paso devuelve datos obsoletos o incompletos, todos los pasos posteriores aprovisionarán los accesos incorrectos."

El agente líder lee esa declaración de intención cuando el paso falla y entiende lo que está en juego. Sabe que un registro parcial significa que los pasos de aprovisionamiento de acceso se ejecutarán con datos incorrectos, potencialmente otorgando permisos equivocados a una persona real que empieza en dos días. Ese contexto determina cómo intenta recuperarse, si pausa los pasos dependientes y qué les dice si lo escala.
Otro paso en el mismo workflow revisa el campo produces del paso de obtención de recursos humanos y sabe que espera .employee.role y .employee.department como cadenas de texto no vacías. Si su sistema de recursos humanos actualiza su API y empieza a devolver esos campos anidados bajo .employee.profile.role, el agente líder detecta el desfase de esquema, aplica un mapeo en tiempo de ejecución para esta ejecución de modo que el nuevo empleado se aprovisione correctamente, y propone una corrección estructural para actualizar la definición del paso. Ustedes no escribieron una regla de migración de esquema ni un manejo de excepciones para este caso específico. El agente líder lo razonó a partir del contexto que ya estaba ahí.
Por eso importa la calidad en la creación de workflows. Los metadatos no son ceremonia; son el combustible con el que funciona el sistema de autorreparación. Un workflow con descripciones de pasos superficiales es un workflow sobre el que el agente líder no puede razonar cuando importa.
Observar en vivo significa detectar problemas antes de que se conviertan en fallas
Dado que el agente líder está observando en tiempo real, puede actuar sobre señales débiles antes de que las cosas realmente se rompan. Un paso que históricamente se completa en dos segundos ahora tarda cuarenta. Un paso que devolvió datos en cada ejecución anterior devuelve un resultado vacío. Se toma una rama condicional que nunca se había tomado en todo el historial de ejecuciones. Nada de esto son errores duros y el workflow sigue ejecutándose, pero son señales de que algo cambió en el entorno. Es mejor detectarlas antes de que el siguiente paso intente consumir datos incorrectos.
La sensibilidad de estas verificaciones es configurable por workflow. Una generación de reportes nocturnos puede tener umbrales amplios mientras que un pipeline de aprovisionamiento de acceso vigila de cerca. Ustedes definen qué nivel de desviación amerita la atención del agente líder.
Sigue siendo su workflow
El agente líder y su equipo no pueden cambiar la definición canónica de su workflow sin su aprobación. Cuando el agente líder propone una corrección estructural, aplica la corrección para completar la ejecución actual y envía el cambio como una propuesta. La ven en su cola, ven el razonamiento, la aprueban o la rechazan. Si la rechazan, ese rechazo queda registrado y cada futuro agente líder que trabaje en ese workflow sabe que no debe proponer lo mismo otra vez.
Hay una cosa que el agente líder nunca puede cambiar sin importar la configuración: su propio mandato. La política de autorreparación en la definición del workflow, si pausar, cuánto tiempo reintentar, si requerir aprobación, es política definida por el dueño. El agente líder puede parchar definiciones de tareas, actualizar llamadas de API, ajustar parámetros y crear nuevos plugins. No puede cambiar las reglas que gobiernan su propio comportamiento. Ese límite está codificado de forma fija. Un agente que pudiera desactivar el requisito de aprobación que gobierna sus propias propuestas haría que todo el modelo de confianza careciera de sentido.
Los cambios de plugins siguen la misma ruta de aprobación que cualquier plugin creado por un agente en Triggerfish. El hecho de que el plugin se haya creado para corregir un workflow roto no le otorga ninguna confianza especial. Pasa por la misma revisión que si le hubieran pedido a un agente que les construyera una nueva integración desde cero.
Gestionar esto en cada canal que ya están usando
No deberían tener que iniciar sesión en un panel separado para saber qué están haciendo sus workflows. Las notificaciones de autorreparación llegan por donde hayan configurado que Triggerfish los contacte: un resumen de intervención en Slack, una solicitud de aprobación en Telegram, un reporte de escalamiento por correo electrónico. El sistema llega a ustedes por el canal que tiene sentido según la urgencia, sin que estén refrescando una consola de monitoreo.
El modelo de estado del workflow está construido para esto. El estado no es una cadena de texto plana sino un objeto estructurado que lleva todo lo que una notificación necesita para ser significativa: el estado actual, la señal de salud, si hay un parche en su cola de aprobación, el resultado de la última ejecución y qué está haciendo el agente líder en este momento. Su mensaje de Slack puede decir "el workflow de aprovisionamiento de acceso está pausado, el agente líder está creando un plugin de corrección, se requerirá aprobación" en una sola notificación sin buscar contexto.
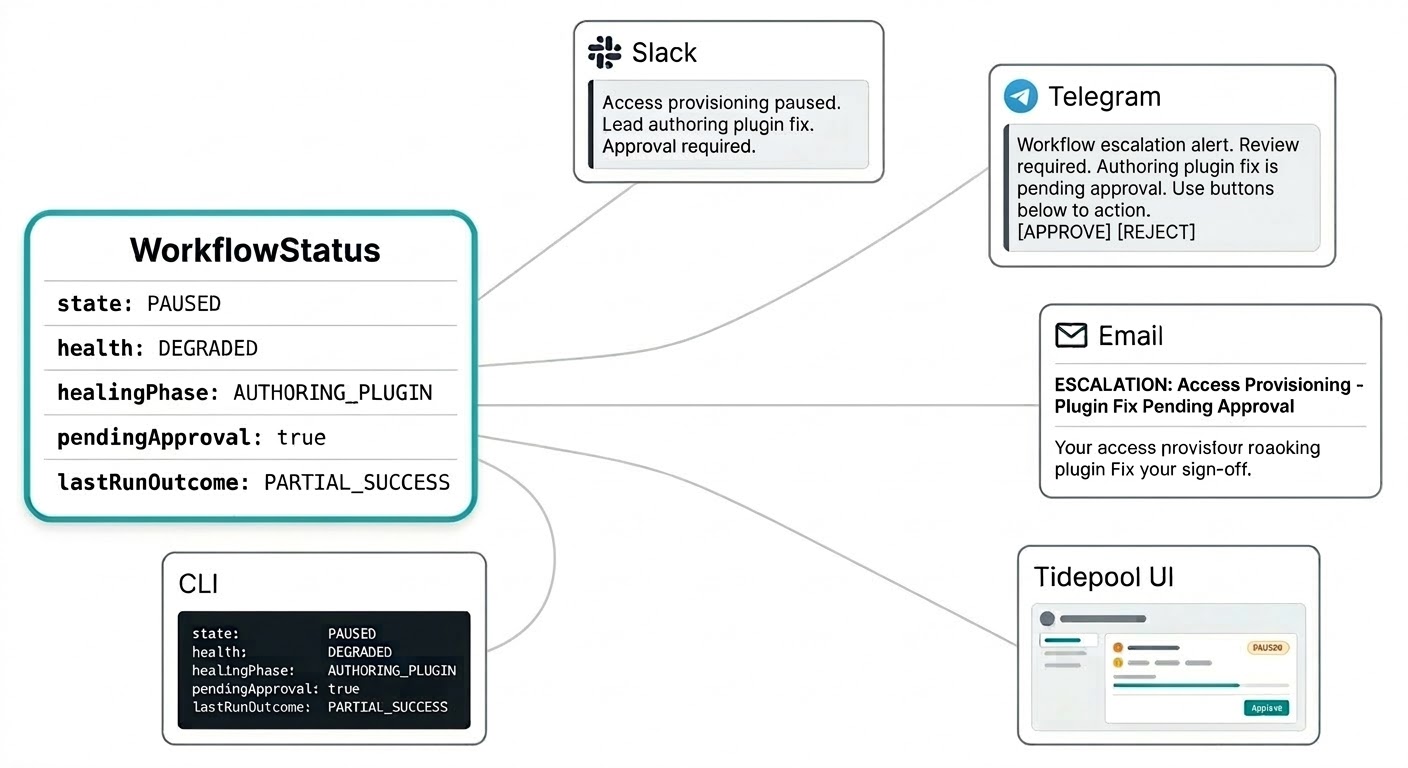
Ese mismo estado estructurado alimenta la interfaz en vivo de Tidepool cuando quieren ver el panorama completo. Mismos datos, diferente superficie.
Qué cambia esto realmente para los equipos de TI
Las personas en su organización que pasan la semana arreglando workflows rotos no están haciendo trabajo de bajo nivel. Están depurando sistemas distribuidos, leyendo changelogs de API y haciendo ingeniería inversa de por qué un workflow que funcionaba ayer hoy está fallando. Es criterio valioso, y ahora mismo se consume casi en su totalidad en mantener viva la automatización existente en lugar de construir nueva automatización o resolver problemas más difíciles.
Los workflows de autorreparación no eliminan ese criterio, pero cambian cuándo se aplica. En lugar de apagar incendios con un workflow roto a medianoche, están revisando una corrección propuesta en la mañana y decidiendo si el diagnóstico del agente líder es correcto. Son quienes aprueban un cambio propuesto, no quienes escriben un parche bajo presión.
Ese es el modelo laboral sobre el que Triggerfish está construido: humanos revisando y aprobando el trabajo de los agentes en lugar de ejecutar el trabajo que los agentes pueden manejar. La cobertura de automatización sube mientras la carga de mantenimiento baja, y el equipo que estaba gastando el 75 por ciento de su tiempo en mantenimiento puede redirigir la mayor parte de ese tiempo hacia cosas que realmente requieren criterio humano.
Disponible hoy
Los workflows de autorreparación se lanzan hoy como una funcionalidad opcional en el motor de workflows de Triggerfish. Se activa por workflow, configurado en el bloque de metadatos del workflow. Si no lo activan, nada cambia en cómo se ejecutan sus workflows.
Esto importa no porque sea un problema técnico difícil (aunque lo es), sino porque aborda directamente lo que ha hecho que la automatización empresarial sea más costosa y más dolorosa de lo que necesita ser. El equipo de mantenimiento de workflows debería ser el primer trabajo que la automatización con IA reemplace. Ese es el uso correcto de esta tecnología, y eso es lo que Triggerfish construyó.
Si quieren profundizar en cómo funciona, la especificación completa está en el repositorio. Si quieren probarlo, el skill workflow-builder los guiará para escribir su primer workflow de autorreparación.