
Ogni programma di automazione enterprise si scontra con lo stesso muro. Routing dei ticket in ServiceNow, remediation del drift Terraform, rotazione dei certificati, provisioning dei gruppi AD, deployment delle patch SCCM, orchestrazione delle pipeline CI/CD. I primi dieci o venti workflow giustificano facilmente l'investimento, e la matematica del ROI regge fino a quando il numero di workflow non supera le centinaia e una parte significativa della settimana del team IT passa dal costruire nuova automazione al tenere in piedi quella esistente.
Un portale pagamenti ridisegna il flusso di autenticazione e il workflow di invio delle richieste smette di autenticarsi. Salesforce rilascia un aggiornamento dei metadati e un field mapping nella pipeline lead-to-opportunity inizia a scrivere valori nulli. AWS depreca una versione API e un Terraform plan che ha funzionato perfettamente per un anno inizia a generare errori 400 a ogni apply. Qualcuno apre un ticket, qualcun altro capisce cosa e' cambiato, applica la patch, la testa, fa il deploy della correzione, e nel frattempo il processo che doveva essere automatizzato e' stato eseguito manualmente oppure non e' stato eseguito affatto.
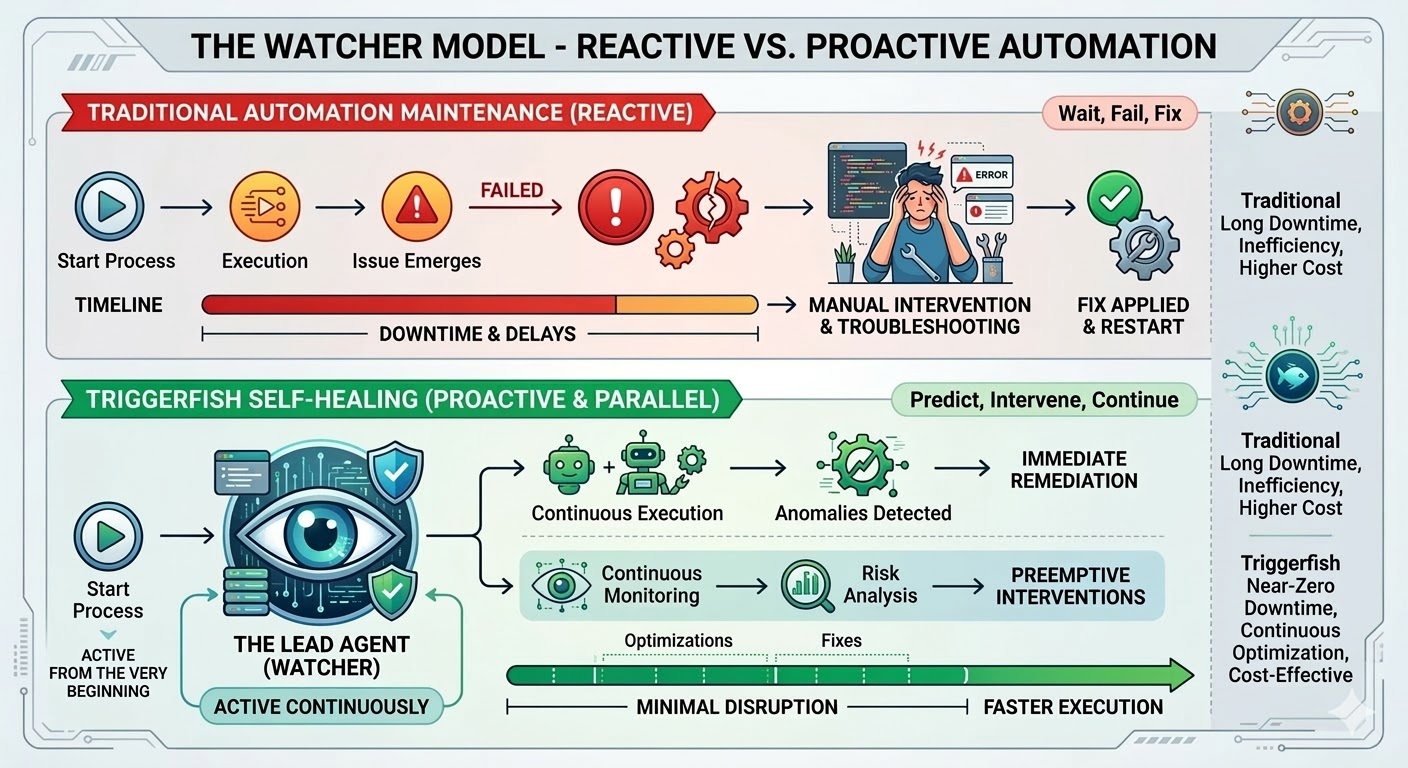
Questa e' la trappola della manutenzione, ed e' strutturale, non un difetto di implementazione. L'automazione tradizionale segue percorsi esatti, cerca corrispondenze esatte e si rompe nel momento in cui la realta' devia da cio' che esisteva quando il workflow e' stato scritto. La ricerca e' coerente: le organizzazioni spendono dal 70 al 75 percento dei costi totali del programma di automazione non per costruire nuovi workflow, ma per mantenere quelli che hanno gia'. Nei deployment di grandi dimensioni, il 45 percento dei workflow si rompe ogni singola settimana.
Il motore di workflow di Triggerfish e' stato costruito per cambiare questo. I workflow self-healing sono disponibili da oggi e rappresentano la funzionalita' piu' significativa della piattaforma finora.
Cosa Significa Davvero Self-Healing
L'espressione viene usata con leggerezza, quindi voglio essere diretto su cosa sia effettivamente.
Quando abiliti il self-healing su un workflow Triggerfish, un agente leader viene creato nel momento in cui il workflow inizia l'esecuzione. Non si attiva quando qualcosa si rompe: sta osservando fin dal primo step, ricevendo un flusso di eventi in tempo reale dal motore mentre il workflow procede e monitorando ogni step in tempo reale.
Il leader conosce l'intera definizione del workflow prima che venga eseguito un singolo step, incluso l'intento dietro ogni step, cosa ogni step si aspetta da quelli precedenti, e cosa produce per quelli successivi. Conosce anche la cronologia delle esecuzioni precedenti: cosa ha avuto successo, cosa ha fallito, quali patch sono state proposte e se un umano le ha approvate o rifiutate. Quando identifica qualcosa su cui vale la pena intervenire, tutto quel contesto e' gia' in memoria perche' stava osservando dall'inizio invece di ricostruire i fatti a posteriori.
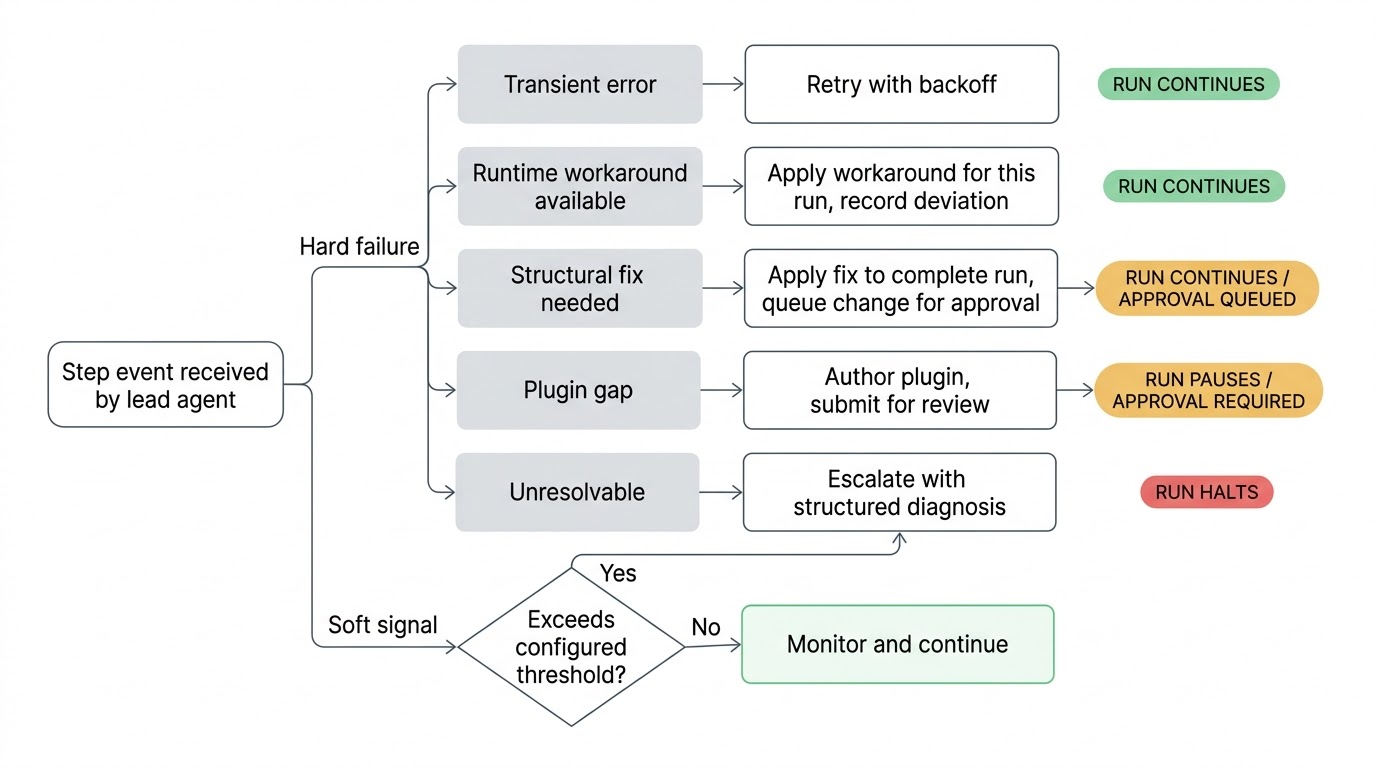
Quando qualcosa va storto, il leader effettua il triage. Una chiamata di rete instabile riceve un retry con backoff. Un endpoint API cambiato che puo' essere aggirato viene aggirato per questa esecuzione. Un problema strutturale nella definizione del workflow riceve una proposta di correzione applicata per completare l'esecuzione, con la modifica sottoposta alla tua approvazione prima che diventi permanente. Un'integrazione con un plugin rotta viene corretta con un plugin nuovo o aggiornato, sottoposto a revisione. Se il leader esaurisce i tentativi e non riesce a risolvere il problema, lo escala a te con una diagnosi strutturata di cosa ha provato e quale ritiene essere la causa principale.
Il workflow continua a essere eseguito ogni volta che e' possibile farlo in sicurezza. Se uno step e' bloccato, solo gli step a valle che dipendono da esso si mettono in pausa mentre i rami paralleli continuano. Il leader conosce il grafo delle dipendenze e mette in pausa solo cio' che e' effettivamente bloccato.
Perche' il Contesto che Inserisci nei Workflow e' Importante
Cio' che fa funzionare il self-healing nella pratica e' che i workflow Triggerfish richiedono metadati ricchi a livello di step fin dal momento in cui li scrivi. Questo non e' opzionale e non e' documentazione fine a se stessa: e' la base su cui l'agente leader ragiona.
Ogni step in un workflow ha quattro campi obbligatori oltre alla definizione del task stesso: una descrizione di cosa fa lo step meccanicamente, una dichiarazione di intento che spiega perche' questo step esiste e quale scopo aziendale serve, un campo expects che descrive quali dati si aspetta di ricevere e in quale stato devono essere gli step precedenti, e un campo produces che descrive cosa scrive nel contesto per gli step a valle.
Ecco come appare nella pratica. Supponiamo che tu stia automatizzando il provisioning degli accessi dei dipendenti. Un nuovo assunto inizia lunedi' e il workflow deve creare account in Active Directory, effettuare il provisioning della membership nell'organizzazione GitHub, assegnare i gruppi Okta e aprire un ticket Jira che confermi il completamento. Uno step recupera il record del dipendente dal sistema HR. Il suo campo intent non dice semplicemente "ottieni il record del dipendente". Dice: "Questo step e' la fonte di verita' per ogni decisione di provisioning a valle. Ruolo, dipartimento e data di inizio da questo record determinano quali gruppi AD vengono assegnati, quali team GitHub vengono forniti e quali policy Okta si applicano. Se questo step restituisce dati obsoleti o incompleti, ogni step a valle effettuera' il provisioning degli accessi sbagliati."

Il leader legge quella dichiarazione di intento quando lo step fallisce e comprende cosa e' in gioco. Sa che un record parziale significa che gli step di provisioning degli accessi verranno eseguiti con input errati, potenzialmente assegnando permessi sbagliati a una persona reale che inizia fra due giorni. Quel contesto determina come tenta il recupero, se mette in pausa gli step a valle, e cosa ti comunica se deve escalare.
Un altro step nello stesso workflow controlla il campo produces dello step di fetch HR e sa che si aspetta .employee.role e .employee.department come stringhe non vuote. Se il tuo sistema HR aggiorna la sua API e inizia a restituire quei campi annidati sotto .employee.profile.role, il leader rileva la deriva dello schema, applica una mappatura a runtime per questa esecuzione in modo che il nuovo assunto venga fornito correttamente, e propone una correzione strutturale per aggiornare la definizione dello step. Non hai scritto una regola di migrazione dello schema o una gestione delle eccezioni per questo caso specifico. Il leader ci e' arrivato ragionando dal contesto che era gia' presente.
Ecco perche' la qualita' della scrittura dei workflow e' importante. I metadati non sono cerimonia: sono il carburante su cui il sistema self-healing funziona. Un workflow con descrizioni superficiali degli step e' un workflow su cui il leader non riesce a ragionare quando conta.
Osservare in Tempo Reale Significa Intercettare i Problemi Prima che Diventino Guasti
Poiche' il leader sta osservando in tempo reale, puo' agire su segnali deboli prima che le cose si rompano effettivamente. Uno step che storicamente si completa in due secondi ora ne impiega quaranta. Uno step che ha restituito dati in ogni esecuzione precedente restituisce un risultato vuoto. Viene preso un ramo condizionale che non e' mai stato preso nell'intera cronologia delle esecuzioni. Nessuno di questi e' un errore critico e il workflow continua a essere eseguito, ma sono segnali che qualcosa e' cambiato nell'ambiente. E' meglio intercettarli prima che lo step successivo tenti di consumare dati errati.
La sensibilita' di questi controlli e' configurabile per workflow. Una generazione di report notturna potrebbe avere soglie larghe, mentre una pipeline di provisioning degli accessi osserva da vicino. Tu stabilisci quale livello di deviazione merita l'attenzione del leader.
Resta Sempre il Tuo Workflow
L'agente leader e il suo team non possono modificare la definizione canonica del tuo workflow senza la tua approvazione. Quando il leader propone una correzione strutturale, applica la correzione per completare l'esecuzione corrente e invia la modifica come proposta. La vedi nella tua coda, ne vedi il ragionamento, la approvi o la rifiuti. Se la rifiuti, quel rifiuto viene registrato e ogni futuro leader che lavora su quel workflow sa di non proporre la stessa cosa.
C'e' una cosa che il leader non puo' mai cambiare indipendentemente dalla configurazione: il proprio mandato. La policy di self-healing nella definizione del workflow, se mettere in pausa, per quanto ritentare, se richiedere approvazione, e' una policy stabilita dal proprietario. Il leader puo' applicare patch alle definizioni dei task, aggiornare le chiamate API, regolare i parametri e scrivere nuovi plugin. Non puo' cambiare le regole che governano il proprio comportamento. Quel confine e' hardcoded. Un agente che potesse disabilitare il requisito di approvazione che governa le proprie proposte renderebbe l'intero modello di fiducia privo di significato.
Le modifiche ai plugin seguono lo stesso percorso di approvazione di qualsiasi plugin scritto da un agente in Triggerfish. Il fatto che il plugin sia stato scritto per correggere un workflow rotto non gli conferisce alcuna fiducia speciale. Passa attraverso la stessa revisione che avrebbe se avessi chiesto a un agente di costruirti una nuova integrazione da zero.
Gestire Tutto Questo su Ogni Canale che Gia' Usi
Non dovresti dover accedere a una dashboard separata per sapere cosa stanno facendo i tuoi workflow. Le notifiche di self-healing arrivano ovunque tu abbia configurato Triggerfish per raggiungerti: un riepilogo dell'intervento su Slack, una richiesta di approvazione su Telegram, un report di escalation via email. Il sistema ti raggiunge sul canale appropriato per l'urgenza senza che tu debba aggiornare una console di monitoraggio.
Il modello di stato del workflow e' costruito per questo. Lo stato non e' una stringa piatta ma un oggetto strutturato che trasporta tutto cio' di cui una notifica ha bisogno per essere significativa: lo stato corrente, il segnale di salute, se c'e' una patch nella tua coda di approvazione, l'esito dell'ultima esecuzione e cosa sta facendo il leader in questo momento. Il tuo messaggio su Slack puo' dire "il workflow di provisioning degli accessi e' in pausa, il leader sta scrivendo una correzione tramite plugin, sara' necessaria l'approvazione" in una singola notifica senza dover cercare contesto.
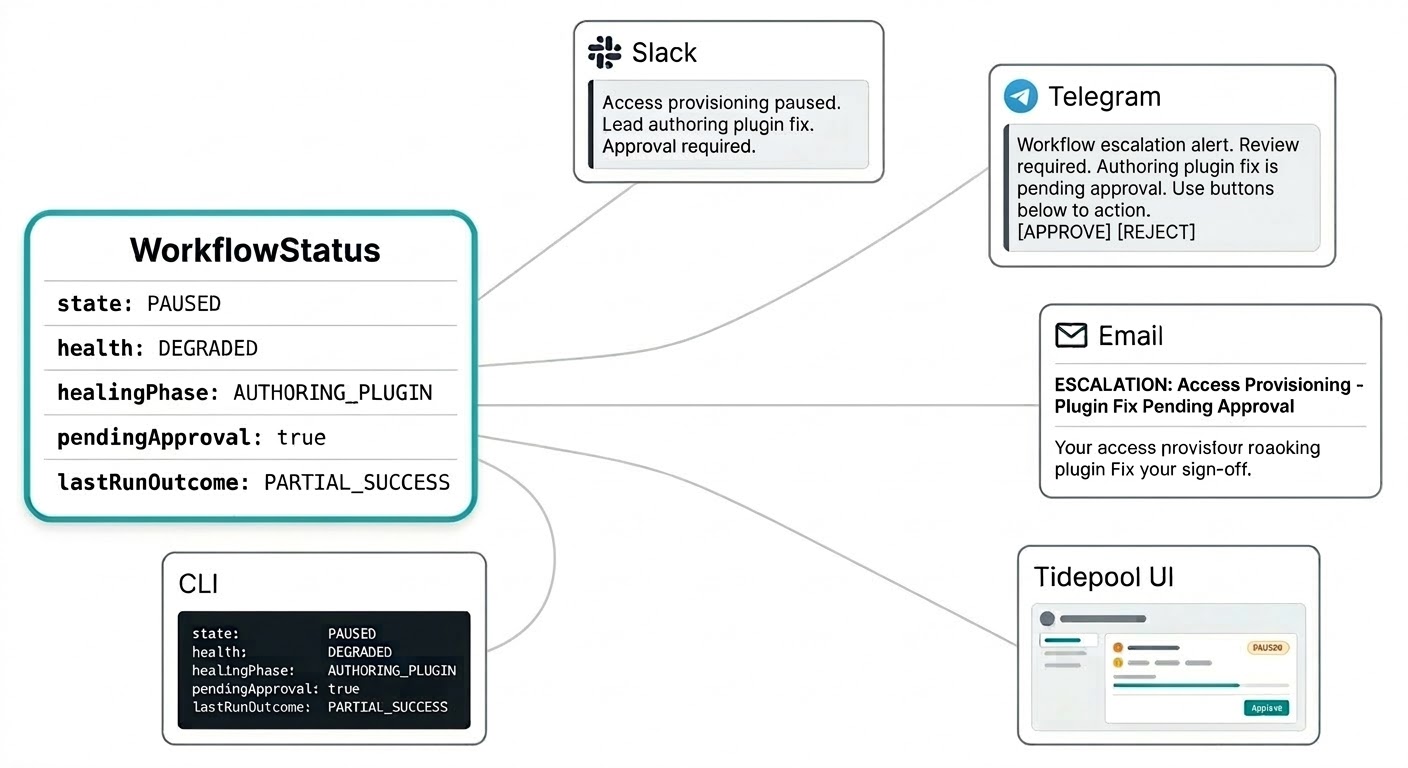
Lo stesso stato strutturato alimenta l'interfaccia live Tidepool quando vuoi il quadro completo. Stessi dati, superficie diversa.
Cosa Cambia Concretamente per i Team IT
Le persone nella tua organizzazione che passano la settimana a riparare workflow rotti non stanno facendo un lavoro a bassa competenza. Stanno facendo debug di sistemi distribuiti, leggendo changelog di API e cercando di capire perche' un workflow che ieri funzionava oggi fallisce. E' un giudizio prezioso, e in questo momento viene quasi interamente consumato dal tenere in vita l'automazione esistente piuttosto che costruire nuova automazione o risolvere problemi piu' complessi.
I workflow self-healing non eliminano quel giudizio, ma spostano il momento in cui viene applicato. Invece di combattere un incendio su un workflow rotto a mezzanotte, stai revisionando una correzione proposta al mattino e decidendo se la diagnosi del leader e' corretta. Sei chi approva una modifica proposta, non chi scrive una patch sotto pressione.
Questo e' il modello di lavoro su cui Triggerfish e' costruito: gli umani revisionano e approvano il lavoro degli agenti invece di eseguire il lavoro che gli agenti possono gestire. La copertura dell'automazione cresce mentre il carico di manutenzione diminuisce, e il team che spendeva il 75 percento del proprio tempo nella manutenzione puo' reindirizzare la maggior parte di quel tempo verso cose che richiedono davvero giudizio umano.
Disponibile da Oggi
I workflow self-healing sono disponibili da oggi come funzionalita' opzionale nel motore di workflow di Triggerfish. E' opt-in per singolo workflow, configurato nel blocco di metadati del workflow. Se non lo abiliti, nulla cambia nel modo in cui i tuoi workflow vengono eseguiti.
Questo e' importante non perche' sia un problema tecnico difficile (anche se lo e'), ma perche' affronta direttamente cio' che ha reso l'automazione enterprise piu' costosa e piu' faticosa di quanto debba essere. Il team di manutenzione dei workflow dovrebbe essere il primo lavoro che l'automazione AI prende. Questo e' l'uso corretto di questa tecnologia, e questo e' cio' che Triggerfish ha costruito.
Se vuoi approfondire come funziona, la specifica completa e' nel repository. Se vuoi provarlo, la skill workflow-builder ti guidera' nella scrittura del tuo primo workflow self-healing.