
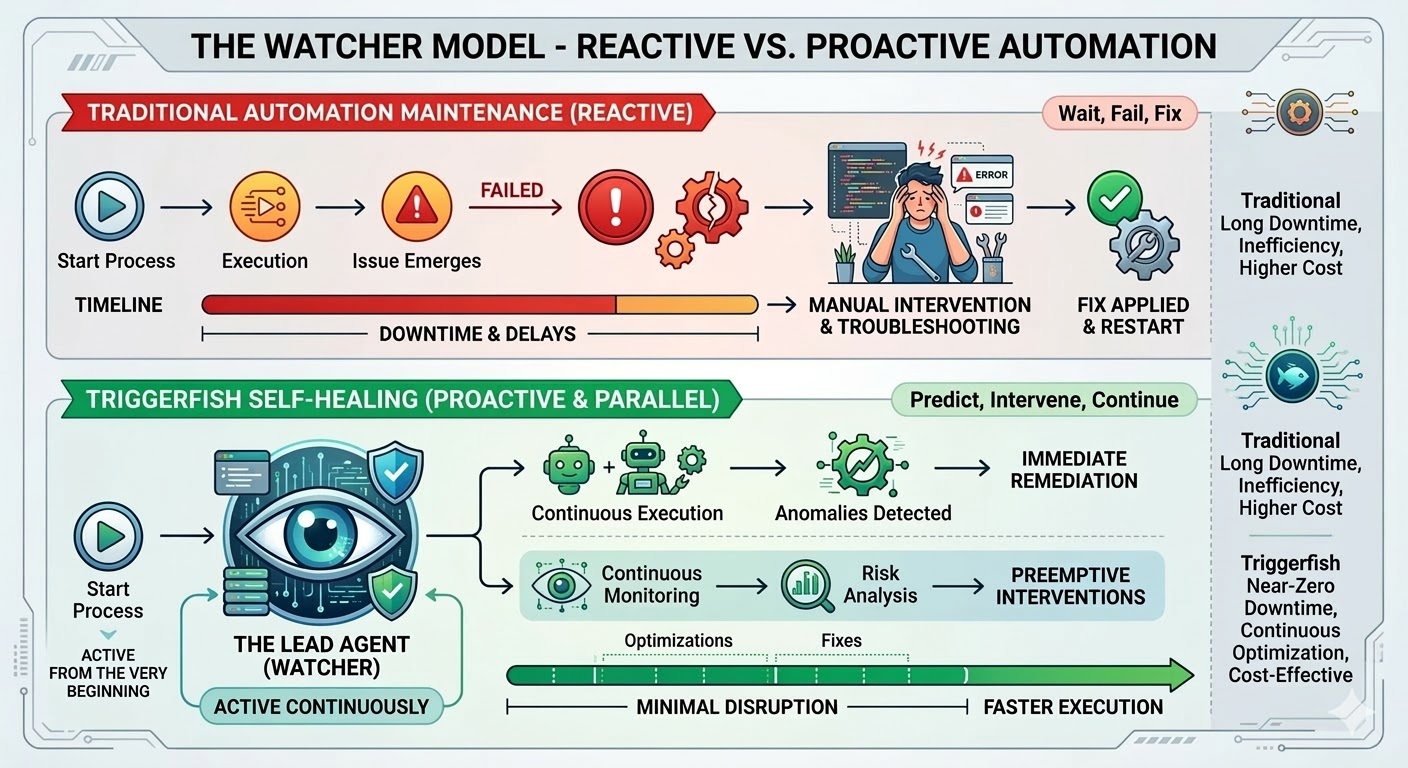
Todo programa de automação empresarial esbarra no mesmo muro. Roteamento de tickets no ServiceNow, remediação de drift no Terraform, rotação de certificados, provisionamento de grupos no Active Directory, implantação de patches via SCCM, orquestração de pipelines CI/CD. Os primeiros dez ou vinte workflows justificam o investimento facilmente, e a matemática do ROI se sustenta até o momento em que a contagem de workflows ultrapassa as centenas e uma parcela significativa da semana do time de TI passa de construir novas automações para impedir que as existentes parem de funcionar.
Um portal de pagamentos redesenha seu fluxo de autenticação e o workflow de submissão de sinistros para de autenticar. O Salesforce publica uma atualização de metadados e um mapeamento de campos no pipeline de lead-para-oportunidade começa a gravar nulos. A AWS deprecia uma versão de API e um Terraform plan que rodava limpo há um ano começa a retornar 400 em cada apply. Alguém abre um chamado, outra pessoa descobre o que mudou, aplica o patch, testa, faz o deploy da correção, e enquanto isso o processo que estava sendo automatizado ou rodou manualmente ou simplesmente não rodou.
Essa é a armadilha da manutenção, e ela é estrutural — não uma falha de implementação. Automação tradicional segue caminhos exatos, corresponde a padrões exatos e quebra no momento em que a realidade diverge do que existia quando o workflow foi criado. A pesquisa é consistente: organizações gastam de 70 a 75 por cento dos custos totais do programa de automação não construindo novos workflows, mas mantendo os que já existem. Em implantações de grande escala, 45 por cento dos workflows quebram toda semana.
O motor de workflows do Triggerfish foi construído para mudar isso. Workflows auto-reparáveis estão disponíveis a partir de hoje, e representam a capacidade mais significativa da plataforma até agora.
O Que Auto-Reparação Realmente Significa
O termo é usado de forma vaga, então vou ser direto sobre o que isso é.
Quando você habilita auto-reparação em um workflow do Triggerfish, um agente líder é criado no momento em que o workflow começa a rodar. Ele não é acionado quando algo quebra; ele está observando desde o primeiro passo, recebendo um stream de eventos ao vivo do motor conforme o workflow avança e observando cada etapa em tempo real.
O líder conhece a definição completa do workflow antes que um único passo seja executado, incluindo a intenção por trás de cada etapa, o que cada passo espera dos anteriores e o que produz para os seguintes. Ele também conhece o histórico de execuções anteriores: o que teve sucesso, o que falhou, quais patches foram propostos e se um humano os aprovou ou rejeitou. Quando identifica algo que merece ação, todo esse contexto já está em memória porque ele estava observando o tempo inteiro, em vez de reconstruir após o fato.
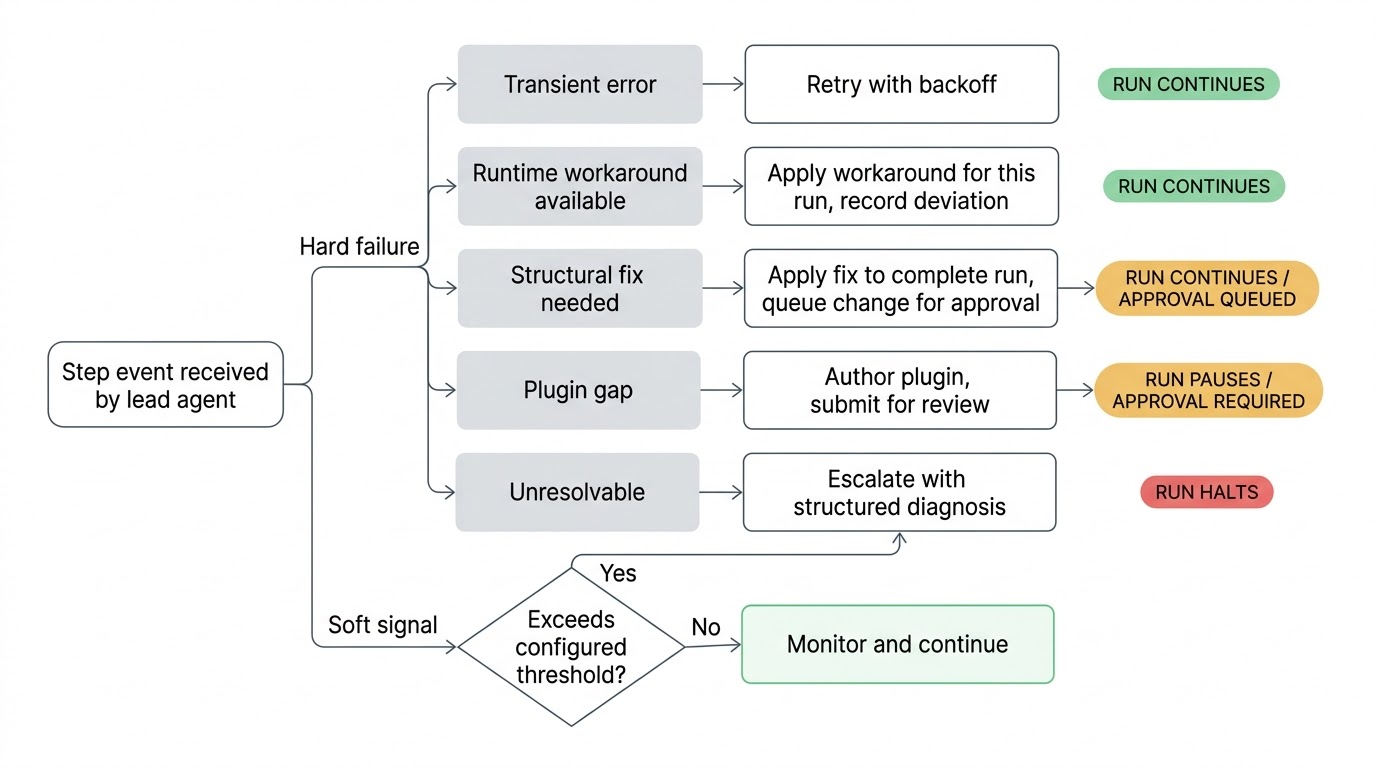
Quando algo dá errado, o líder faz a triagem. Uma chamada de rede instável recebe um retry com backoff. Um endpoint de API alterado que pode ser contornado é contornado para esta execução. Um problema estrutural na definição do workflow recebe uma correção proposta aplicada para completar a execução, com a mudança submetida para sua aprovação antes de se tornar permanente. Uma integração de plugin com defeito recebe um plugin novo ou atualizado, criado e submetido para revisão. Se o líder esgota suas tentativas e não consegue resolver o problema, ele escala para você com um diagnóstico estruturado do que tentou e qual ele acredita ser a causa raiz.
O workflow continua rodando sempre que for seguro fazê-lo. Se um passo está bloqueado, apenas os passos downstream que dependem dele pausam enquanto branches paralelas continuam. O líder conhece o grafo de dependências e pausa apenas o que está de fato bloqueado.
Por Que o Contexto Que Você Constrói nos Workflows Importa
O que faz a auto-reparação funcionar na prática é que os workflows do Triggerfish exigem metadados ricos no nível de cada passo desde o momento em que você os escreve. Isso não é opcional e não é documentação por si só; é a base a partir da qual o agente líder raciocina.
Cada passo em um workflow tem quatro campos obrigatórios além da própria definição da tarefa: uma descrição do que o passo faz mecanicamente, uma declaração de intenção explicando por que esse passo existe e qual propósito de negócio ele serve, um campo expects descrevendo quais dados ele assume estar recebendo e em que estado os passos anteriores devem estar, e um campo produces descrevendo o que ele escreve no contexto para os passos downstream consumirem.
Veja como isso funciona na prática. Digamos que você está automatizando o provisionamento de acesso de funcionários. Um novo contratado começa na segunda-feira e o workflow precisa criar contas no Active Directory, provisionar sua associação à organização no GitHub, atribuir seus grupos no Okta e abrir um ticket no Jira confirmando a conclusão. Um passo busca o registro do funcionário no seu sistema de RH. O campo de intenção não diz apenas "buscar o registro do funcionário." Ele diz: "Este passo é a fonte da verdade para toda decisão de provisionamento downstream. Cargo, departamento e data de início deste registro determinam quais grupos do AD serão atribuídos, quais times do GitHub serão provisionados e quais políticas do Okta se aplicam. Se este passo retornar dados desatualizados ou incompletos, todos os passos downstream provisionarão o acesso errado."

O líder lê essa declaração de intenção quando o passo falha e entende o que está em jogo. Ele sabe que um registro parcial significa que os passos de provisionamento de acesso vão rodar com inputs ruins, potencialmente concedendo permissões erradas a uma pessoa real que começa em dois dias. Esse contexto molda como ele tenta recuperar, se pausa os passos downstream e o que comunica a você se escalar.
Outro passo no mesmo workflow verifica o campo produces do passo de busca do RH e sabe que espera .employee.role e .employee.department como strings não-vazias. Se seu sistema de RH atualiza a API e começa a retornar esses campos aninhados em .employee.profile.role, o líder detecta o drift de schema, aplica um mapeamento em tempo de execução para esta rodada para que o novo contratado seja provisionado corretamente, e propõe uma correção estrutural para atualizar a definição do passo. Você não escreveu uma regra de migração de schema ou tratamento de exceção para esse caso específico. O líder raciocinou a partir do contexto que já estava lá.
É por isso que a qualidade da autoria do workflow importa. Os metadados não são cerimônia; são o combustível que alimenta o sistema de auto-reparação. Um workflow com descrições rasas nos passos é um workflow sobre o qual o líder não consegue raciocinar quando mais importa.
Observar ao Vivo Significa Capturar Problemas Antes Que Se Tornem Falhas
Como o líder está observando em tempo real, ele pode agir sobre sinais suaves antes que as coisas de fato quebrem. Um passo que historicamente completa em dois segundos agora está levando quarenta. Um passo que retornava dados em todas as execuções anteriores retorna um resultado vazio. Um branch condicional que nunca foi tomado em todo o histórico de execuções é acionado. Nenhum desses é um erro grave e o workflow continua rodando, mas são sinais de que algo mudou no ambiente. É melhor capturá-los antes que o próximo passo tente consumir dados ruins.
A sensibilidade dessas verificações é configurável por workflow. Uma geração de relatório noturno pode ter limiares flexíveis, enquanto um pipeline de provisionamento de acesso observa de perto. Você define qual nível de desvio merece a atenção do líder.
O Workflow Continua Sendo Seu
O agente líder e sua equipe não podem alterar a definição canônica do seu workflow sem sua aprovação. Quando o líder propõe uma correção estrutural, ele aplica a correção para completar a execução atual e submete a mudança como uma proposta. Você a vê na sua fila, vê o raciocínio, aprova ou rejeita. Se você rejeitar, essa rejeição é registrada e todo futuro líder trabalhando naquele workflow sabe que não deve propor a mesma coisa novamente.
Há uma coisa que o líder nunca pode alterar independentemente da configuração: seu próprio mandato. A política de auto-reparação na definição do workflow — se deve pausar, por quanto tempo tentar novamente, se deve exigir aprovação — é política definida pelo proprietário. O líder pode corrigir definições de tarefas, atualizar chamadas de API, ajustar parâmetros e criar novos plugins. Ele não pode mudar as regras que governam seu próprio comportamento. Esse limite é hard-coded. Um agente que pudesse desabilitar o requisito de aprovação que governa suas próprias propostas tornaria todo o modelo de confiança sem sentido.
Mudanças em plugins seguem o mesmo caminho de aprovação que qualquer plugin criado por um agente no Triggerfish. O fato de o plugin ter sido criado para corrigir um workflow com defeito não lhe dá nenhuma confiança especial. Ele passa pela mesma revisão que passaria se você tivesse pedido a um agente para construir uma nova integração do zero.
Gerenciando Isso em Todos os Canais Que Você Já Usa
Você não deveria precisar fazer login em um painel separado para saber o que seus workflows estão fazendo. Notificações de auto-reparação chegam por onde quer que você tenha configurado o Triggerfish para alcançá-lo: um resumo de intervenção no Slack, uma solicitação de aprovação no Telegram, um relatório de escalação por e-mail. O sistema vai até você no canal que faz sentido para a urgência, sem que você precise ficar atualizando um console de monitoramento.
O modelo de status do workflow foi construído para isso. O status não é uma string plana, mas um objeto estruturado que carrega tudo que uma notificação precisa para ser significativa: o estado atual, o sinal de saúde, se há um patch na sua fila de aprovação, o resultado da última execução e o que o líder está fazendo no momento. Sua mensagem no Slack pode dizer "o workflow de provisionamento de acesso está pausado, o líder está criando um plugin de correção, aprovação será necessária" em uma única notificação sem precisar caçar contexto.
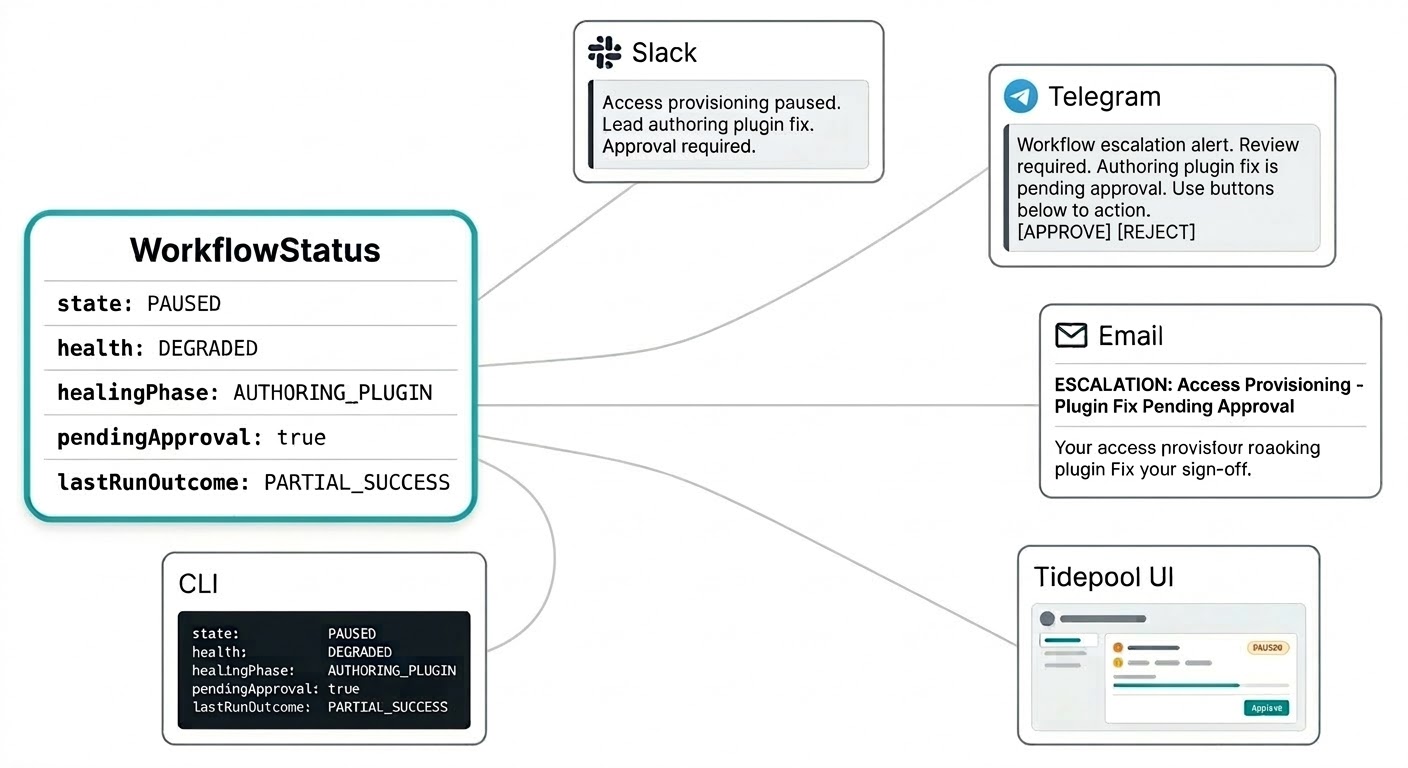
Esse mesmo status estruturado alimenta a interface ao vivo do Tidepool quando você quer o panorama completo. Mesmos dados, superfície diferente.
O Que Isso Realmente Muda para Times de TI
As pessoas na sua organização que passam a semana corrigindo workflows quebrados não estão fazendo trabalho de baixa qualificação. Elas estão debugando sistemas distribuídos, lendo changelogs de API e fazendo engenharia reversa de por que um workflow que rodava bem ontem está falhando hoje. Isso é julgamento valioso, e agora ele está quase inteiramente consumido mantendo automação existente viva em vez de construir novas automações ou resolver problemas mais difíceis.
Workflows auto-reparáveis não eliminam esse julgamento, mas mudam quando ele é aplicado. Em vez de apagar incêndio em um workflow quebrado à meia-noite, você está revisando uma correção proposta pela manhã e decidindo se o diagnóstico do líder está correto. Você é o aprovador de uma mudança proposta, não o autor de um patch sob pressão.
Esse é o modelo de trabalho em torno do qual o Triggerfish foi construído: humanos revisando e aprovando o trabalho de agentes em vez de executar o trabalho que agentes conseguem lidar. A cobertura de automação sobe enquanto a carga de manutenção desce, e o time que estava gastando 75 por cento do seu tempo em manutenção pode redirecionar a maior parte desse tempo para coisas que realmente exigem julgamento humano.
Disponível Hoje
Workflows auto-reparáveis estão disponíveis hoje como uma funcionalidade opcional no motor de workflows do Triggerfish. É opt-in por workflow, configurado no bloco de metadados do workflow. Se você não habilitar, nada muda na forma como seus workflows rodam.
Isso importa não porque é um problema técnico difícil (embora seja), mas porque endereça diretamente aquilo que tem tornado a automação empresarial mais cara e mais penosa do que precisa ser. O time de manutenção de workflows deveria ser o primeiro emprego que a automação com IA assume. Esse é o uso certo dessa tecnologia, e é o que o Triggerfish construiu.
Se você quer entender como funciona em detalhe, a especificação completa está no repositório. Se quer experimentar, a skill workflow-builder vai guiá-lo na criação do seu primeiro workflow auto-reparável.