
Hvert enterprise automasjonsprogram treffer den samme veggen. ServiceNow billetruting, Terraform driftretting, sertifikatrotasjon, AD-gruppeprovisjonering, SCCM patch-distribusjon, CI/CD-pipeline-orkestrering. De første ti eller tjue arbeidsflytene rettferdiggjør investeringen enkelt, og ROI-matematikken holder opp helt til antall arbeidsflyter krysser inn i hundrevis og en meningsfull del av IT-teamets uke skifter fra å bygge ny automasjon til å holde eksisterende automasjon fra å falle over.
En betalerportal redesigner auth-flyten og kravinnleveringsarbeidsflyten slutter å autentisere. Salesforce dytter en metadataoppdatering og en felttilordning i lead-til-mulighet-pipelinen begynner å skrive nuller. AWS avvikler en API-versjon og en Terraform-plan som kjørte rent i et år begynner å kaste 400-er på hvert apply. Noen sender inn en billett, noen andre finner ut hva som endret seg, patcher det, tester det, distribuerer rettingen, og i mellomtiden kjørte prosessen den automatiserte enten manuelt eller ikke i det hele tatt.
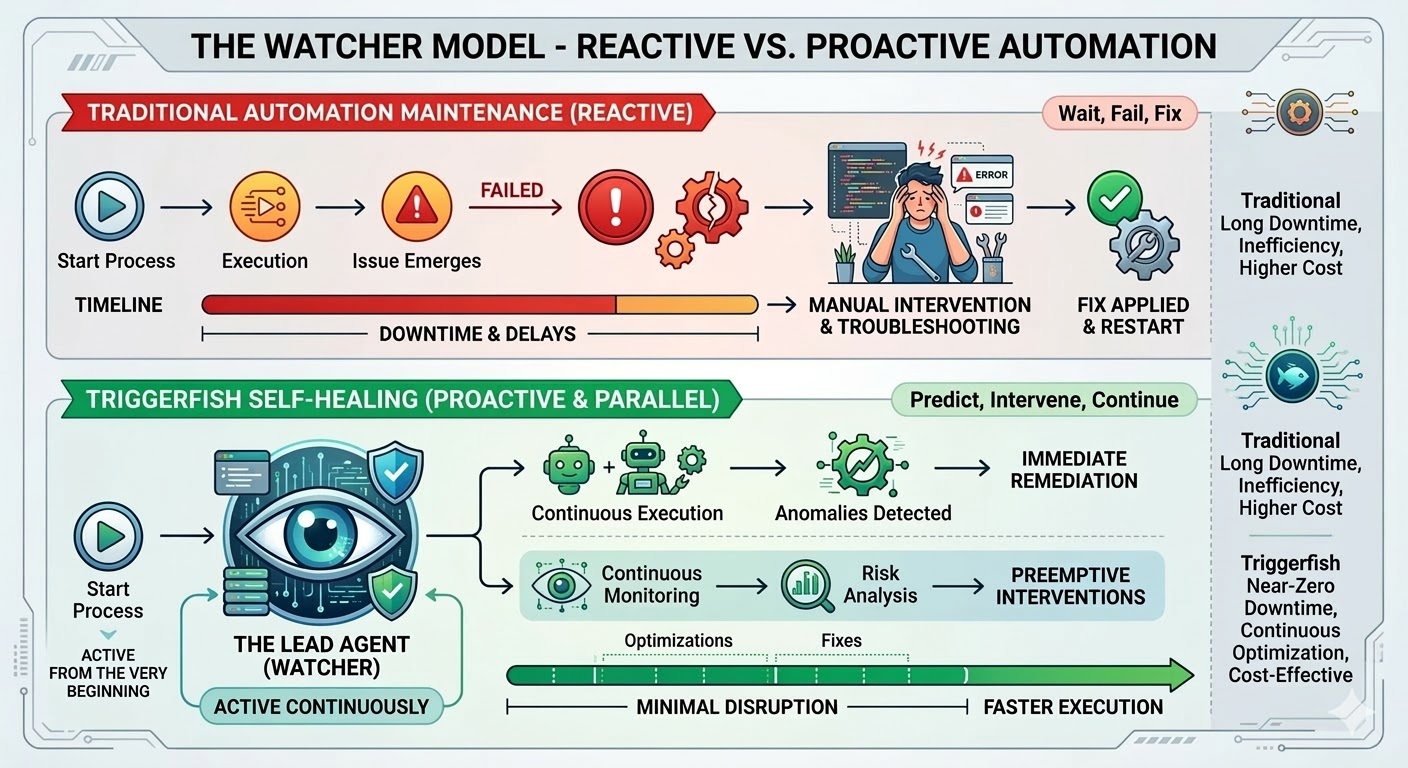
Dette er vedlikeholdsfellen, og den er strukturell snarere enn en implementeringsfeil. Tradisjonell automasjon følger eksakte baner, matcher eksakte mønstre og bryter i det øyeblikket virkeligheten avviker fra det som eksisterte da arbeidsflyten ble skrevet. Forskningen er konsistent: organisasjoner bruker 70 til 75 prosent av de totale kostnadene for automasjonsprogrammet ikke på å bygge nye arbeidsflyter, men på å vedlikeholde de de allerede har. I store distribusjoner bryter 45 prosent av arbeidsflytene hver eneste uke.
Triggerfish-arbeidsflytmotoren ble bygget for å endre dette. Selvhelbredende arbeidsflyter leveres i dag, og de representerer den mest betydningsfulle evnen i plattformen så langt.
Hva selvhelbredelse faktisk betyr
Frasen brukes løst, så la meg være direkte om hva dette er.
Når du aktiverer selvhelbredelse på en Triggerfish-arbeidsflyt, startes en lederagent i det øyeblikket den arbeidsflyten begynner å kjøre. Den starter ikke når noe bryter; den ser fra det første trinnet, mottar en live hendelsesstrøm fra motoren mens arbeidsflyten skrider frem og observerer hvert trinn i sanntid.
Lederen kjenner hele arbeidsflytdefinisjonen før et eneste trinn kjøres, inkludert intensjonen bak hvert trinn, hva hvert trinn forventer fra de før det, og hva det produserer for de etter det. Den kjenner også historien til tidligere kjøringer: hva som lyktes, hva som mislyktes, hvilke patcher som ble foreslått og om et menneske godkjente eller avviste dem. Når den identifiserer noe verdt å handle på, er all den konteksten allerede i minnet fordi den så hele tiden i stedet for å rekonstruere etter det faktum.
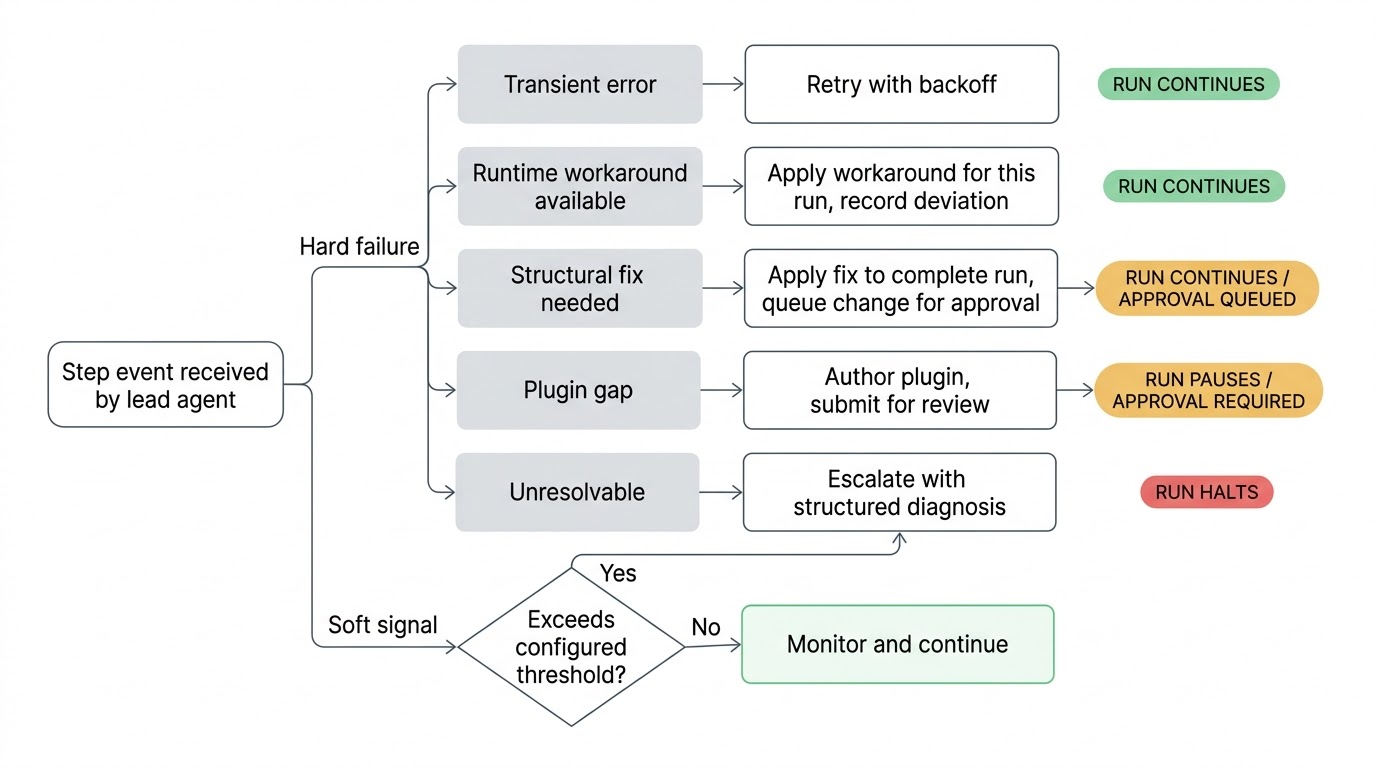
Når noe går galt, triagerer lederen det. Et ustabilt nettverkskall får et nytt forsøk med backoff. Et endret API-endepunkt som kan løses rundt, løses rundt for denne kjøringen. Et strukturelt problem i arbeidsflytdefinisjonen får en foreslått rettelse anvendt for å fullføre kjøringen, med endringen sendt inn for din godkjenning før den blir permanent. En ødelagt plugin-integrasjon får en ny eller oppdatert plugin forfattet og sendt inn for gjennomgang. Hvis lederen uttømmer forsøkene og ikke kan løse problemet, eskalerer den til deg med en strukturert diagnose av hva den prøvde og hva den tror rotårsaken er.
Arbeidsflyten fortsetter å kjøre så lenge den trygt kan. Hvis et trinn er blokkert, pauser bare de nedstrøms trinnene som er avhengige av det mens parallelle grener fortsetter. Lederen kjenner avhengighetsgrafet og pauser bare det som faktisk er blokkert.
Hvorfor konteksten du bygger inn i arbeidsflyter betyr noe
Det som gjør selvhelbredelse til å fungere i praksis er at Triggerfish-arbeidsflyter krever rike trinnivå-metadata fra det øyeblikket du skriver dem. Dette er ikke valgfritt og det er ikke dokumentasjon for sin egen skyld; det er det lederagenten resonnerer fra.
Hvert trinn i en arbeidsflyt har fire obligatoriske felt utover selve oppgavedefinisjonen: en beskrivelse av hva trinnet gjør mekanisk, en intensjonserklæring som forklarer hvorfor dette trinnet eksisterer og hvilket forretningsformål det tjener, et expects-felt som beskriver hvilke data det antar at det mottar og hvilken tilstand tidligere trinn må være i, og et produces-felt som beskriver hva det skriver til konteksten for nedstrøms trinn å konsumere.
Her er hva det ser ut som i praksis. Si at du automatiserer ansattes tilgangsprovisionering. En ny ansatt begynner mandag og arbeidsflyten trenger å opprette kontoer i Active Directory, provisionere GitHub org-medlemskapet deres, tildele Okta-gruppene deres og åpne en Jira-billett som bekrefter fullføring. Ett trinn henter ansattposten fra HR-systemet. Intensjonsfeltet sier ikke bare «hent ansattposten.» Det lyder: «Dette trinnet er sannhetskilden for alle nedstrøms provisioneringsbeslutninger. Rolle, avdeling og startdato fra denne posten bestemmer hvilke AD-grupper som tildeles, hvilke GitHub-team som provisioneres, og hvilke Okta-policyer som gjelder. Hvis dette trinnet returnerer foreldede eller ufullstendige data, vil hvert nedstrøms trinn provisionere feil tilgang.»

Lederen leser den intensjonserklæringen når trinnet mislykkes og forstår hva som står på spill. Den vet at en delvis post betyr at tilgangsprovisioneringstrinnene vil kjøre med dårlige inndata, potensielt gi feil tillatelser til en ekte person som starter om to dager. Den konteksten former hvordan den prøver å gjenopprette, om den pauser nedstrøms trinn, og hva den forteller deg hvis den eskalerer.
Et annet trinn i den samme arbeidsflyten sjekker produces-feltet til HR-hentesteget og vet at det forventer .employee.role og .employee.department som ikke-tomme strenger. Hvis HR-systemet oppdaterer API-et og begynner å returnere disse feltene nestet under .employee.profile.role i stedet, oppdager lederen skjemadriften, anvender en kjøretidstilordning for denne kjøringen slik at den nye ansatte provisioneres riktig, og foreslår en strukturell rettelse for å oppdatere trinnsdefinisjonen. Du skrev ikke en skjemamigrasjonsregel eller unntaksbehandling for dette spesifikke tilfellet. Lederen resonnerte til det fra konteksten som allerede var der.
Dette er grunnen til at arbeidsflytkvaliteten betyr noe. Metadataene er ikke seremoni; det er drivstoffet selvhelbredelsessystemet kjører på. En arbeidsflyt med grunne trinsbeskrivelser er en arbeidsflyt lederen ikke kan resonnere om når det teller.
Å se live betyr å fange problemer før de blir feil
Fordi lederen ser i sanntid, kan den handle på myke signaler før ting faktisk bryter. Et trinn som historisk fullfører på to sekunder tar nå førti. Et trinn som returnerte data i alle tidligere kjøringer returnerer et tomt resultat. En betinget gren tas som aldri har blitt tatt i hele kjørehistorien. Ingen av disse er harde feil og arbeidsflyten fortsetter å kjøre, men de er signaler om at noe har endret seg i miljøet. Det er bedre å fange dem før det neste trinnet prøver å konsumere dårlige data.
Sensitiviteten til disse sjekkene er konfigurerbar per arbeidsflyt. En nattlig rapportgenerering kan ha løse terskler mens en tilgangsprovisioneringsrørledning ser tett på. Du setter hvilket avviksnivå som berettiger lederens oppmerksomhet.
Det er fortsatt arbeidsflyten din
Lederagenten og teamet dens kan ikke endre den kanoniske arbeidsflytdefinisjonen din uten din godkjenning. Når lederen foreslår en strukturell rettelse, anvender den rettingen for å fullføre den gjeldende kjøringen og sender endringen som et forslag. Du ser det i køen din, du ser begrunnelsen, du godkjenner eller avviser den. Hvis du avviser den, registreres den avvisningen og hver fremtidig leder som jobber med den arbeidsflyten, vet ikke å foreslå det samme igjen.
Det er én ting lederen aldri kan endre uavhengig av konfigurasjon: sitt eget mandat. Selvhelbredelsespolicyen i arbeidsflytdefinisjonen — om å pause, hvor lenge å prøve på nytt, om å kreve godkjenning — er eier-forfattet policy. Lederen kan patche oppgavedefinisjoner, oppdatere API-kall, justere parametere og forfattere nye plugins. Den kan ikke endre reglene som styrer sin egen atferd. Den grensen er hardkodet. En agent som kunne deaktivere godkjenningskravet som styrer dens egne forslag, ville gjøre hele tillitsmodellen meningsløs.
Plugin-endringer følger den samme godkjenningsstien som alle plugins forfattet av en agent i Triggerfish. Det faktum at pluginen ble forfattet for å fikse en ødelagt arbeidsflyt, gir den ingen spesiell tillit. Den går gjennom den samme gjennomgangen som om du hadde bedt en agent om å bygge en ny integrasjon fra bunnen av.
Administrere dette på tvers av alle kanalene du allerede bruker
Du burde ikke måtte logge inn på et separat dashbord for å vite hva arbeidsflytene dine gjør. Selvhelbredelsevarsler kommer gjennom uansett hvor du har konfigurert Triggerfish til å nå deg: et intervensjonsssammendrag på Slack, en godkjenningsforespørsel på Telegram, en eskaleringsrapport per e-post. Systemet kommer til deg på kanalen som gir mening for hastigheten uten at du oppdaterer en overvåkingskonsoll.
Arbeidsflytstatusmodellen er bygget for dette. Status er ikke en flat streng, men et strukturert objekt som bærer alt en varsling trenger for å være meningsfull: gjeldende tilstand, helsesignal, om en patch er i godkjenningskøen din, resultatet av den siste kjøringen, og hva lederen gjør for øyeblikket. Slack-meldingen din kan si «tilgangsprovisioneringsarbeidsflyten er pauset, lederen forfatter en plugin-rettelse, godkjenning vil være nødvendig» i en enkelt varsling uten å lete etter kontekst.
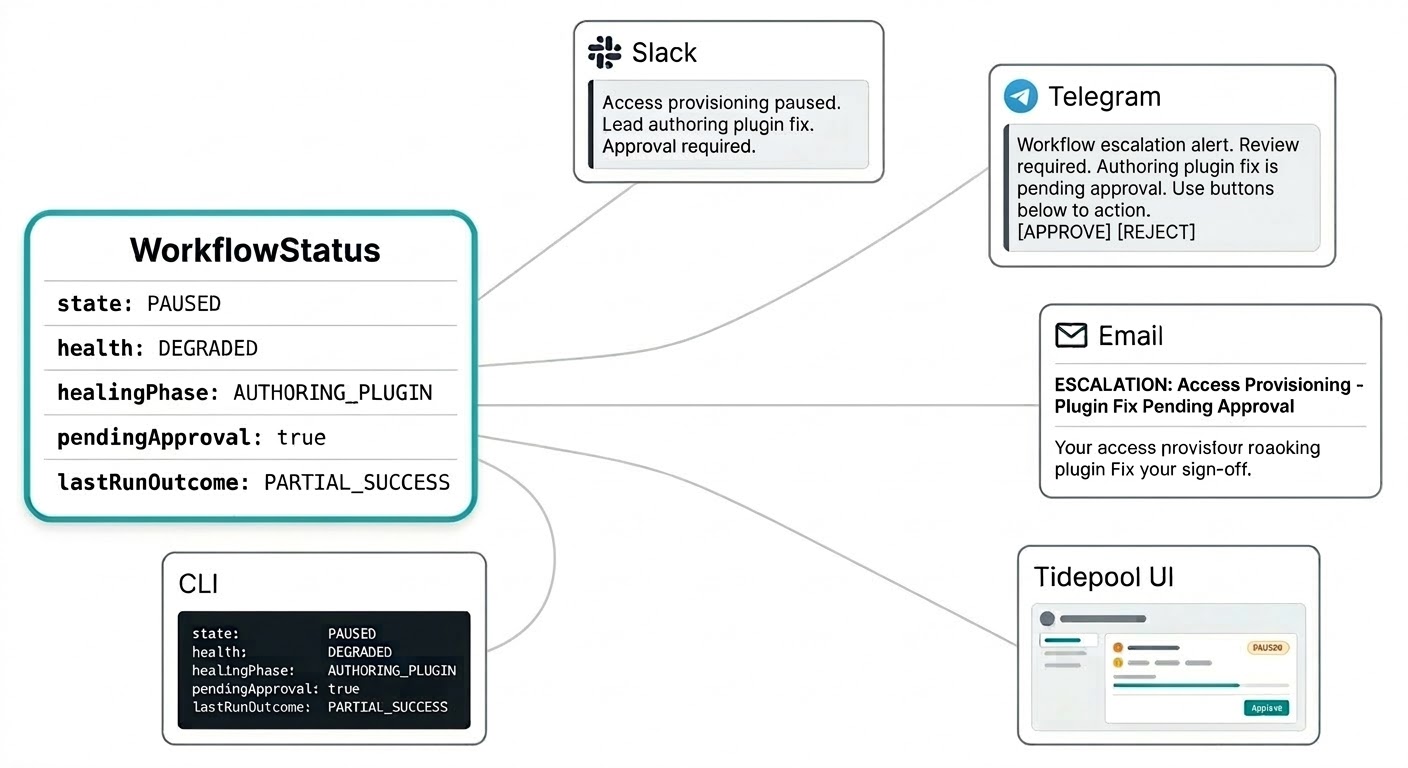
Den samme strukturerte statusen mater Tidepool-grensesnittet live når du vil ha hele bildet. Samme data, annet overflate.
Hva dette faktisk endrer for IT-team
Menneskene i organisasjonen din som bruker uken på å fikse ødelagte arbeidsflyter, gjør ikke lavkvalitets arbeid. De feilsøker distribuerte systemer, leser API-endringslogger og baklengs konstruerer hvorfor en arbeidsflyt som fungerte fint i går, mislykkes i dag. Det er verdifull vurdering, og akkurat nå forbrukes den nesten helt av å holde eksisterende automasjon i live snarere enn å bygge ny automasjon eller løse vanskeligere problemer.
Selvhelbredende arbeidsflyter eliminerer ikke den vurderingen, men de skifter når den anvendes. I stedet for å brannslukke en ødelagt arbeidsflyt ved midnatt, gjennomgår du et foreslått fix om morgenen og bestemmer om lederens diagnose er riktig. Du er godkjenner av en foreslått endring, ikke forfatteren av en patch under press.
Det er arbeidsmodellen Triggerfish er bygget rundt: mennesker som gjennomgår og godkjenner agentarbeid snarere enn å utføre arbeidet agenter kan håndtere. Automasjondekning går opp mens vedlikeholdsbyrden går ned, og teamet som brukte 75 prosent av tiden på vedlikehold kan omdirigere det meste av den tiden mot ting som faktisk krever menneskelig vurdering.
Leveres i dag
Selvhelbredende arbeidsflyter leveres i dag som en valgfri funksjon i Triggerfish-arbeidsflytmotoren. Det er valgfritt per arbeidsflyt, konfigurert i arbeidsflyt-metadatablokken. Hvis du ikke aktiverer det, endrer ingenting seg i måten arbeidsflytene kjøres på.
Dette betyr noe ikke fordi det er et vanskelig teknisk problem (selv om det er det), men fordi det direkte adresserer det som har gjort enterprise-automasjon dyrere og mer smertefullt enn det trenger å være. Arbeidsflyt-vedlikeholdsteamet bør være den første jobben som AI-automasjon tar. Det er den rette bruken av denne teknologien, og det er det Triggerfish bygde.
Hvis du vil grave inn i hvordan det fungerer, er hele spesifikasjonen i repositoriet. Hvis du vil prøve det, vil arbeidsflyt-builder-ferdigheten lede deg gjennom å skrive din første selvhelbredende arbeidsflyt.