
每个企业自动化项目都会撞上同一堵墙。ServiceNow 工单路由、Terraform 漂移修复、证书轮换、Active Directory 组配置、SCCM 补丁部署、CI/CD 流水线编排——最初的十到二十个工作流轻松证明了投资的价值,ROI 的账算得也很漂亮,直到工作流数量突破数百个,IT 团队每周的大量时间从构建新自动化转向了维护现有自动化、防止它们崩溃。
某支付门户重新设计了认证流程,理赔提交工作流就无法认证了。Salesforce 推送了一次元数据更新,线索转商机流水线中的字段映射开始写入空值。AWS 废弃了一个 API 版本,运行了一整年的 Terraform plan 开始在每次 apply 时抛出 400 错误。有人提了工单,另一个人搞清楚了变更内容,打补丁、测试、部署修复,而与此同时,那个被自动化的流程要么靠人工跑,要么根本没跑。
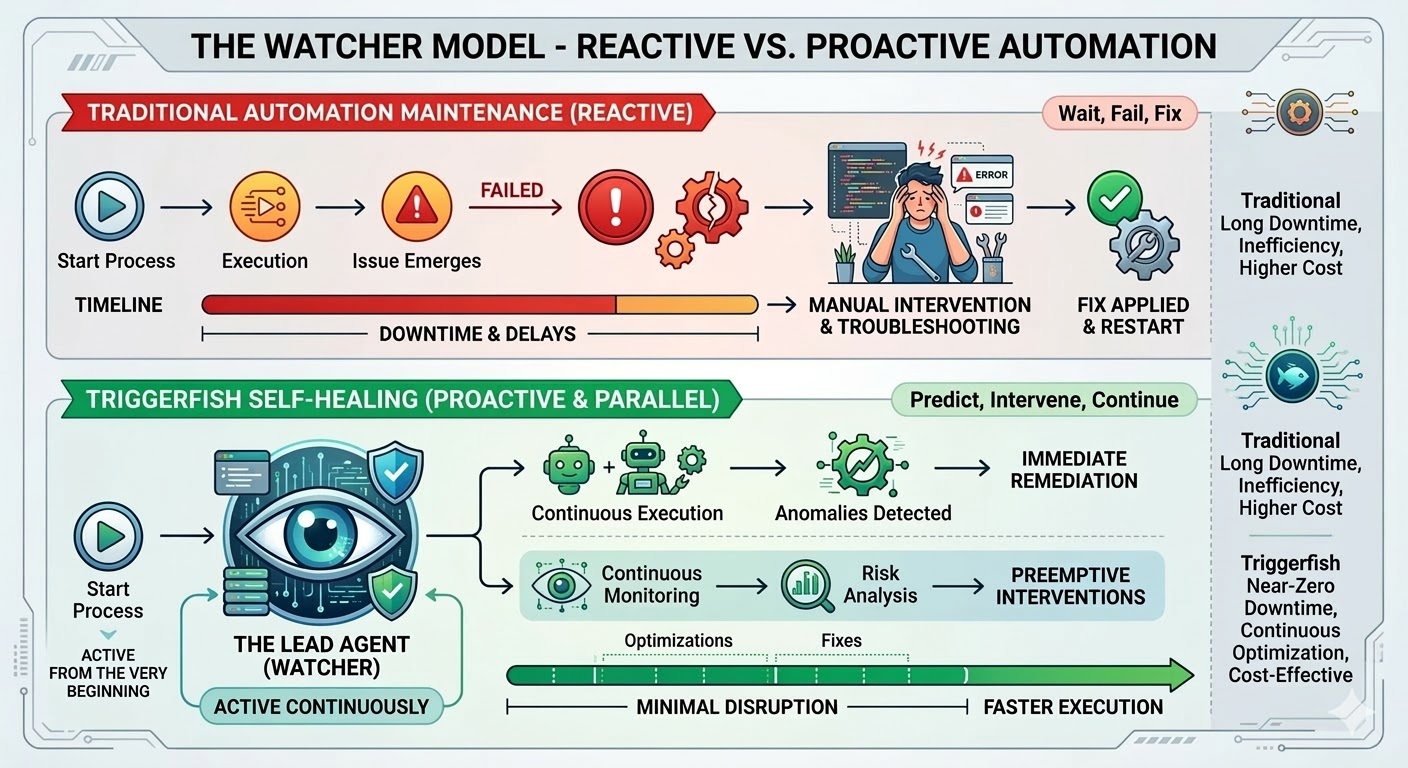
这就是维护陷阱,它是结构性的,而非实施上的失败。传统自动化遵循精确路径、匹配精确模式,一旦现实偏离编写工作流时的状态就会崩溃。研究数据一致表明:组织在自动化项目总成本中有 70% 到 75% 花在了维护现有工作流上,而非构建新的。在大规模部署中,每周有 45% 的工作流会出故障。
Triggerfish 的工作流引擎就是为改变这一现状而生的。自愈工作流今天正式发布,这是平台迄今为止最重要的能力。
自愈到底意味着什么
这个词用得很泛滥,所以我直说这里的含义。
当你在 Triggerfish 工作流上启用自愈功能时,工作流开始运行的那一刻就会生成一个主导代理。它不是在出问题时才启动的——它从第一步就开始监视,接收引擎发出的实时事件流,实时观察每一个步骤。
主导代理在第一步运行之前就了解完整的工作流定义,包括每个步骤的意图、每个步骤对前置步骤的期望、以及它为后续步骤产出什么。它还了解历史运行记录:哪些成功了、哪些失败了、提出了哪些补丁、人工是批准还是拒绝了它们。当它发现值得处理的情况时,所有这些上下文都已经在内存中了,因为它一直在实时监视,而非事后重建。
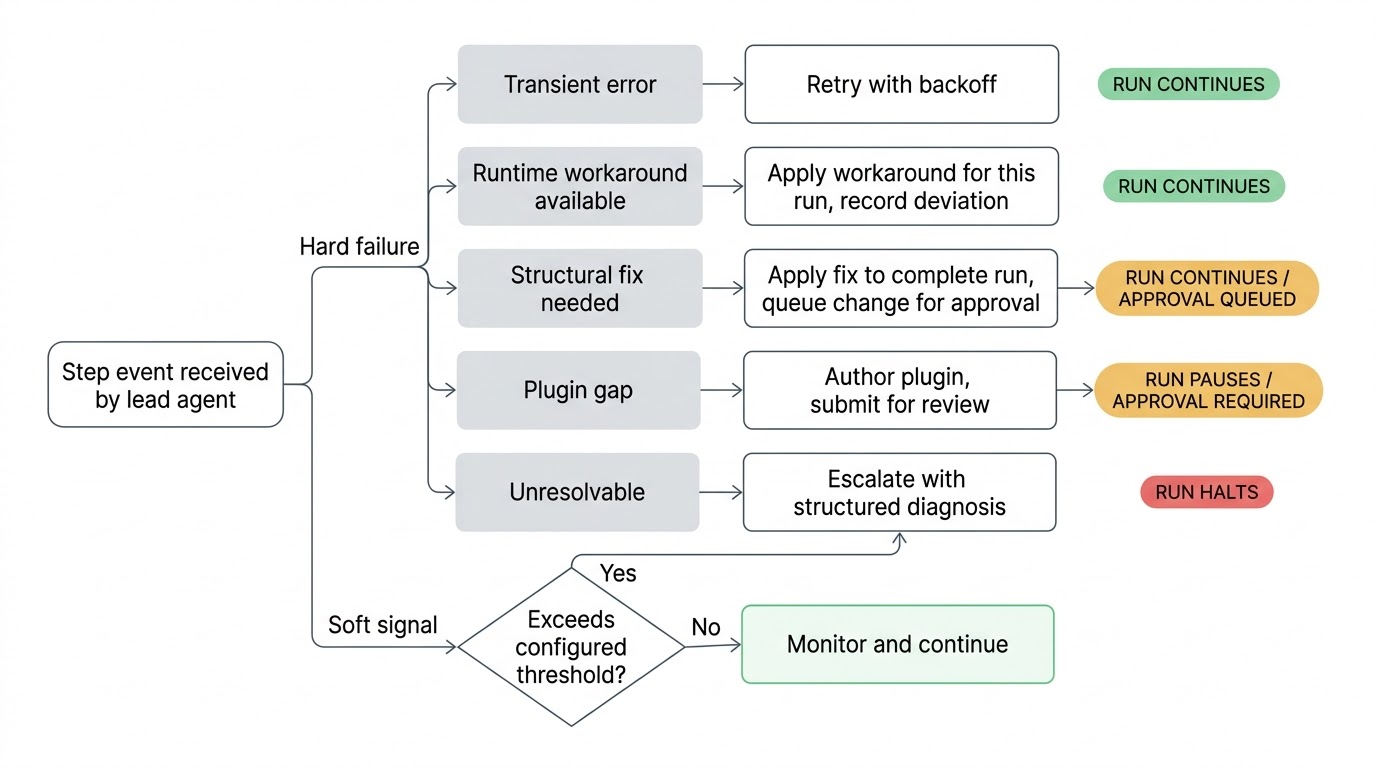
当出现问题时,主导代理会进行分诊。不稳定的网络调用会以退避策略重试。已变更但可以绕过的 API 端点会在本次运行中被绕过。工作流定义中的结构性问题会先应用一个临时修复以完成本次运行,同时将变更提交给你审批后才能成为永久修改。损坏的插件集成会生成一个新的或更新的插件并提交审查。如果主导代理用尽了所有尝试仍无法解决问题,它会向你上报,附带结构化的诊断报告,说明它尝试了什么以及它认为的根本原因。
工作流在安全的情况下会继续运行。如果某个步骤被阻塞,只有依赖它的下游步骤会暂停,而并行分支继续执行。主导代理了解依赖图,只暂停真正被阻塞的部分。
为什么你在工作流中构建的上下文很重要
自愈在实践中能发挥作用的关键在于:Triggerfish 工作流从编写之初就要求丰富的步骤级元数据。这不是可选项,也不是为了写文档而写文档——这是主导代理推理的依据。
工作流中每个步骤在任务定义之外有四个必填字段:描述步骤机械操作的说明、解释该步骤存在原因及其业务目的的意图声明、描述它预期接收什么数据及前置步骤必须处于什么状态的期望字段、以及描述它向上下文写入什么数据供下游步骤消费的产出字段。
来看一个实际例子。假设你在自动化员工权限配置。一位新员工下周一入职,工作流需要在 Active Directory 中创建账户、配置其 GitHub 组织成员身份、分配 Okta 组、并创建一个 Jira 工单确认完成。其中一个步骤从你的 HR 系统获取员工记录。它的意图字段不只是写"获取员工记录",而是这样写的:"此步骤是所有下游配置决策的唯一数据源。来自此记录的角色、部门和入职日期决定了分配哪些 Active Directory 组、配置哪些 GitHub 团队、以及应用哪些 Okta 策略。如果此步骤返回过时或不完整的数据,所有下游步骤将配置错误的权限。"

主导代理在该步骤失败时读取这段意图声明,就能理解问题的严重性。它知道不完整的记录意味着权限配置步骤将使用错误输入运行,可能会给一个两天后入职的真实员工授予错误权限。这些上下文决定了它如何尝试恢复、是否暂停下游步骤、以及上报时告诉你什么。
同一工作流中的另一个步骤检查 HR 获取步骤的产出字段,知道它期望 .employee.role 和 .employee.department 为非空字符串。如果你的 HR 系统更新了 API,开始将这些字段嵌套在 .employee.profile.role 下返回,主导代理会检测到模式漂移,为本次运行应用运行时映射以确保新员工正确配置,并提出结构性修复来更新步骤定义。你不需要为这种特定情况编写模式迁移规则或异常处理。主导代理从已有的上下文中推理得出了解决方案。
这就是工作流编写质量重要的原因。元数据不是形式主义,它是自愈系统运行的燃料。步骤描述写得浅的工作流,就是主导代理在关键时刻无法推理的工作流。
实时监视意味着在问题变成故障之前就能捕获
因为主导代理在实时监视,它能在问题真正发生之前就对软信号采取行动。一个历史上两秒完成的步骤现在用了四十秒。一个在之前每次运行中都返回数据的步骤现在返回了空结果。一个在完整运行历史中从未被执行的条件分支被触发了。这些都不是硬错误,工作流继续运行,但它们是环境发生变化的信号。在下一个步骤尝试消费坏数据之前捕获这些信号总是更好的。
这些检查的灵敏度可以按工作流配置。夜间报表生成可能设置宽松的阈值,而权限配置流水线则严密监视。你来设定什么程度的偏差值得主导代理关注。
工作流仍然是你的
主导代理及其团队在未经你批准的情况下无法更改你的规范工作流定义。当主导代理提出结构性修复时,它会先应用修复以完成当前运行,然后将变更作为提案提交。你在队列中看到它、看到推理过程,然后批准或拒绝。如果你拒绝了,该拒绝会被记录,未来处理该工作流的每个主导代理都知道不要再提出同样的建议。
有一件事主导代理无论配置如何都绝对不能更改:它自己的职责范围。工作流定义中的自愈策略——是否暂停、重试多久、是否需要审批——是所有者编写的策略。主导代理可以修补任务定义、更新 API 调用、调整参数、编写新插件,但它不能更改管控其自身行为的规则。这个边界是硬编码的。一个能禁用管控自身提案审批要求的代理,会让整个信任模型毫无意义。
插件变更遵循与 Triggerfish 中代理编写的任何插件相同的审批流程。插件是为修复损坏的工作流而编写的这一事实不会给予它任何特殊信任。它走的审查流程与你从头要求代理构建一个新集成完全相同。
在你已经使用的每个渠道上管理这一切
你不应该需要登录另一个仪表盘来了解工作流的运行状况。自愈通知会通过你配置 Triggerfish 的任何渠道发送给你:Slack 上的干预摘要、Telegram 上的审批请求、电子邮件中的上报报告。系统根据紧急程度通过合适的渠道找到你,无需你不断刷新监控控制台。
工作流状态模型就是为此而建的。状态不是一个简单的字符串,而是一个结构化对象,携带通知所需的一切信息:当前状态、健康信号、是否有补丁在你的审批队列中、上次运行的结果、以及主导代理当前正在做什么。你的 Slack 消息可以在一条通知中说"权限配置工作流已暂停,主导代理正在编写插件修复,需要审批",无需四处查找上下文。
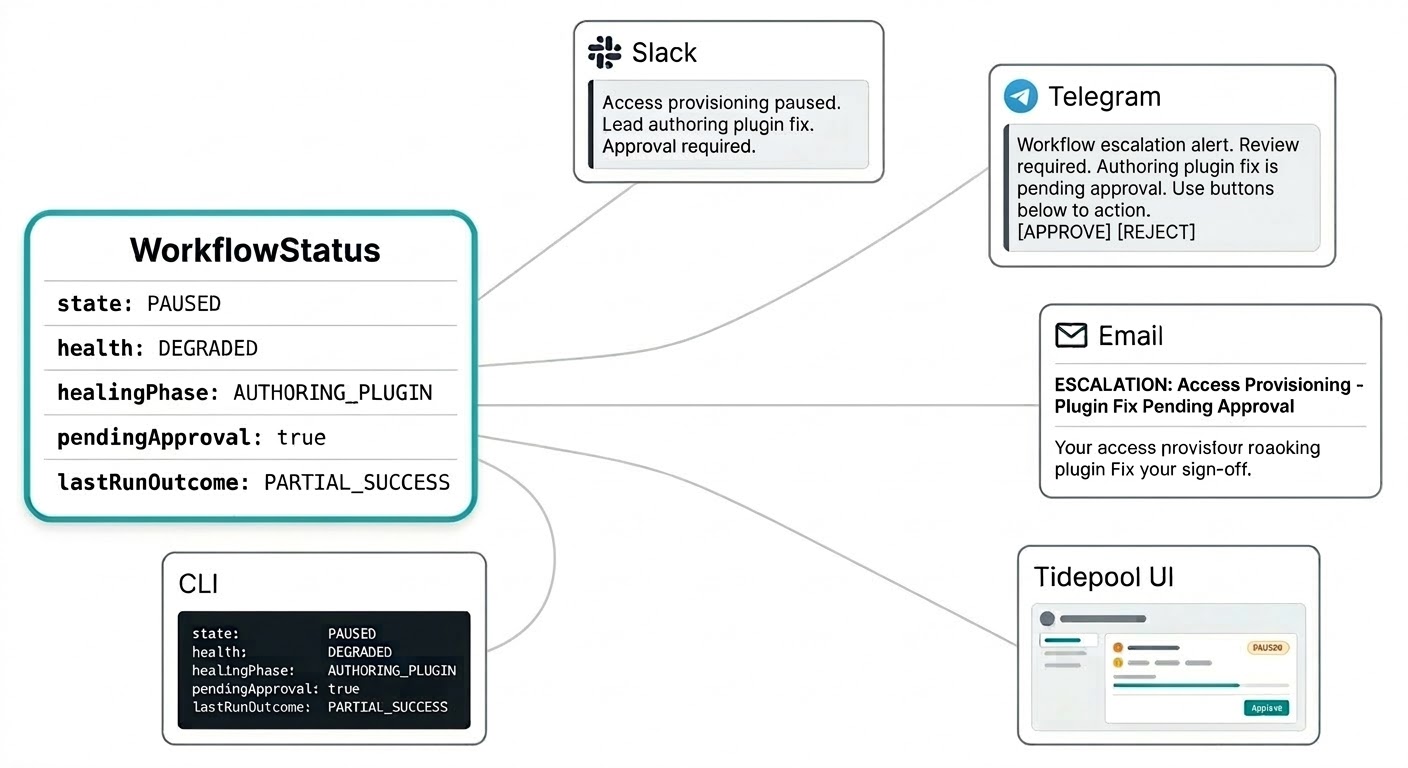
同样的结构化状态也会呈现在 Tidepool 实时界面中,当你需要完整视图时使用。同样的数据,不同的展现形式。
这对 IT 团队意味着什么实质性变化
你组织中那些每周花时间修复损坏工作流的人并不是在做低技能工作。他们在调试分布式系统、阅读 API 变更日志、逆向工程昨天还正常运行今天却失败的工作流原因。这是有价值的判断力,而目前它几乎全部消耗在维护现有自动化上,而非构建新自动化或解决更难的问题。
自愈工作流不会消除这种判断力,但会改变它被应用的时机。你不再是在半夜紧急修复崩溃的工作流,而是在早上审查一个修复提案并判断主导代理的诊断是否正确。你是变更提案的审批者,而非压力下的补丁编写者。
这就是 Triggerfish 构建的人力模型:人类审查和批准代理的工作,而不是执行代理能处理的工作。自动化覆盖率上升,维护负担下降,原来把 75% 时间花在维护上的团队可以将大部分时间重新投入到真正需要人类判断力的事情上。
今天发布
自愈工作流今天作为 Triggerfish 工作流引擎的可选功能正式发布。每个工作流可单独启用,在工作流元数据块中配置。如果你不启用它,工作流的运行方式不会有任何变化。
这件事之所以重要,不是因为它是一个困难的技术问题(虽然确实如此),而是因为它直接解决了让企业自动化比应有的更昂贵、更痛苦的根本问题。工作流维护团队应该是 AI 自动化取代的第一个岗位。这才是这项技术的正确用途,也正是 Triggerfish 所构建的。
如果你想深入了解它的工作原理,完整规格在代码仓库中。如果你想试用,workflow-builder 技能会指导你编写你的第一个自愈工作流。