
ہر enterprise automation program ایک ہی دیوار سے ٹکراتا ہے۔ ServiceNow ticket routing، Terraform drift remediation، certificate rotation، AD group provisioning، SCCM patch deployment، CI/CD pipeline orchestration۔ پہلے دس یا بیس workflows آسانی سے investment justify کرتے ہیں، اور ROI کا حساب ٹھیک رہتا ہے بالکل اس وقت تک جب workflows کی تعداد سینکڑوں میں نہیں جاتی اور IT team کے ہفتے کا ایک معنی خیز حصہ نئی automation بنانے سے موجودہ automation کو گرنے سے روکنے کی طرف shift نہ ہو جائے۔
ایک payer portal اپنا auth flow redesign کرتا ہے اور claims submission workflow authenticate کرنا بند کر دیتا ہے۔ Salesforce ایک metadata update push کرتا ہے اور lead-to-opportunity pipeline میں ایک field mapping nulls لکھنا شروع کر دیتی ہے۔ AWS ایک API version deprecate کرتا ہے اور ایک Terraform plan جو ایک سال تک clean چلا ہر apply پر 400s throw کرنا شروع کر دیتا ہے۔ کوئی ticket file کرتا ہے، کوئی اور یہ سمجھتا ہے کہ کیا بدلا، patch کرتا ہے، test کرتا ہے، fix deploy کرتا ہے، اور اس دوران جو process یہ automate کر رہا تھا وہ یا manually چلا یا چلا ہی نہیں۔
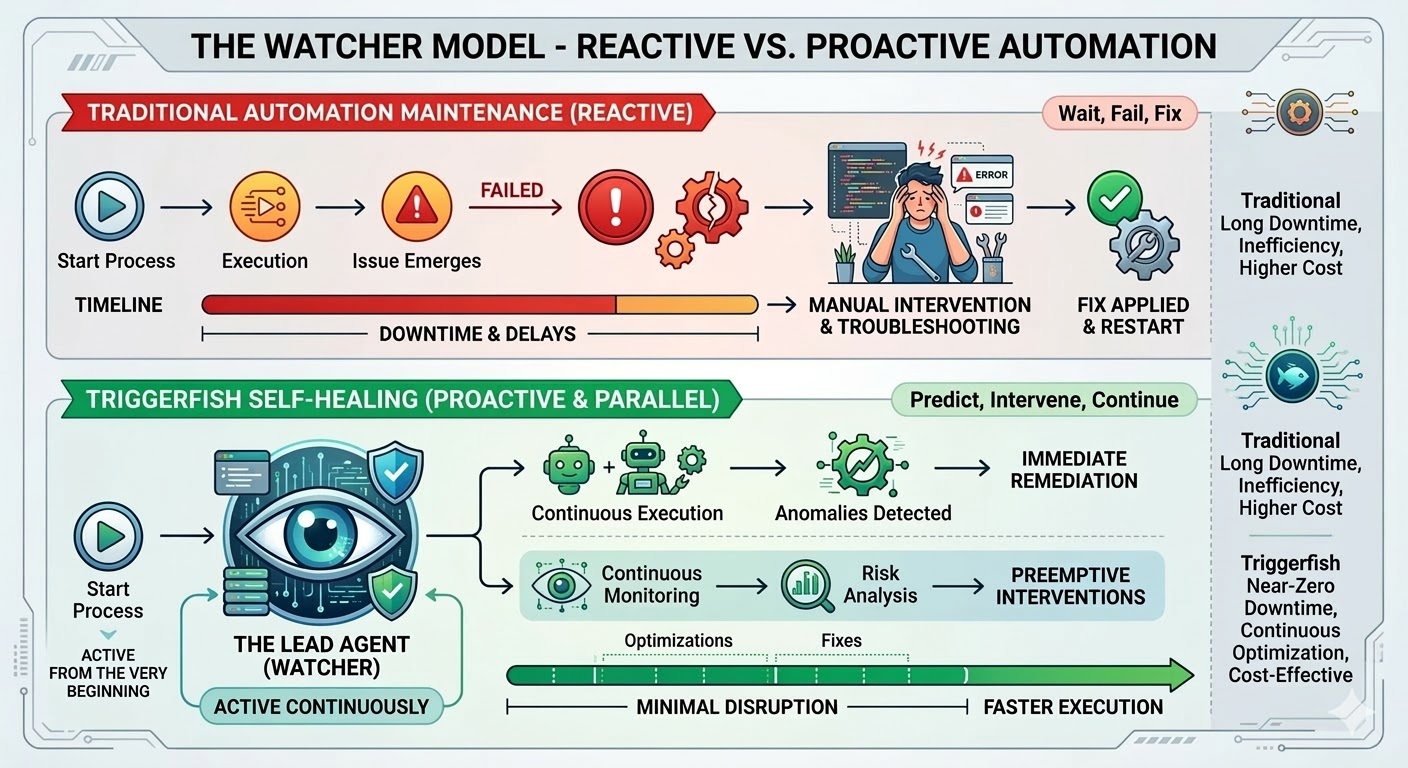
یہ maintenance trap ہے، اور یہ implementation کی ناکامی کی بجائے structural ہے۔ روایتی automation exact paths follow کرتی ہے، exact patterns match کرتی ہے، اور جیسے ہی reality اس سے deviation کرے جو workflow لکھتے وقت تھی ٹوٹ جاتی ہے۔ Research consistent ہے: organizations اپنے total automation program costs کا 70 سے 75 فیصد نئے workflows بنانے میں نہیں بلکہ پہلے سے موجود workflows maintain کرنے میں خرچ کرتی ہیں۔ بڑی deployments میں، 45 فیصد workflows ہر ہفتے break ہوتے ہیں۔
Triggerfish کا workflow engine اسے بدلنے کے لیے بنایا گیا تھا۔ Self-healing workflows آج ship ہو رہے ہیں، اور یہ اب تک platform کی سب سے اہم capability ہے۔
Self-Healing کا اصل مطلب
یہ phrase loosely استعمال ہوتی ہے، اس لیے سیدھا بتاتا ہوں کہ یہ کیا ہے۔
جب آپ Triggerfish workflow پر self-healing enable کرتے ہیں تو workflow شروع ہوتے ہی ایک lead agent spawn ہوتا ہے۔ یہ اس وقت launch نہیں ہوتا جب کچھ break ہو؛ یہ پہلے step سے watch کر رہا ہے، workflow progress کرتے ہوئے engine سے live event stream receive کر رہا ہے اور ہر step کو real time میں observe کر رہا ہے۔
Lead کو پوری workflow definition معلوم ہے ایک بھی step چلنے سے پہلے، بشمول ہر step کے پیچھے intent، ہر step کو پہلے والوں سے کیا توقع ہے، اور یہ بعد والوں کے لیے کیا produce کرتا ہے۔ اسے پچھلے runs کی history بھی معلوم ہے: کیا کامیاب ہوا، کیا fail ہوا، کون سے patches propose ہوئے اور کیا کسی human نے انہیں approve یا reject کیا۔ جب یہ کچھ act کرنے کے قابل identify کرے تو وہ سارا context پہلے سے memory میں ہے کیونکہ یہ پوری وقت watch کر رہا تھا بجائے اس کے کہ بعد میں reconstruct کرے۔
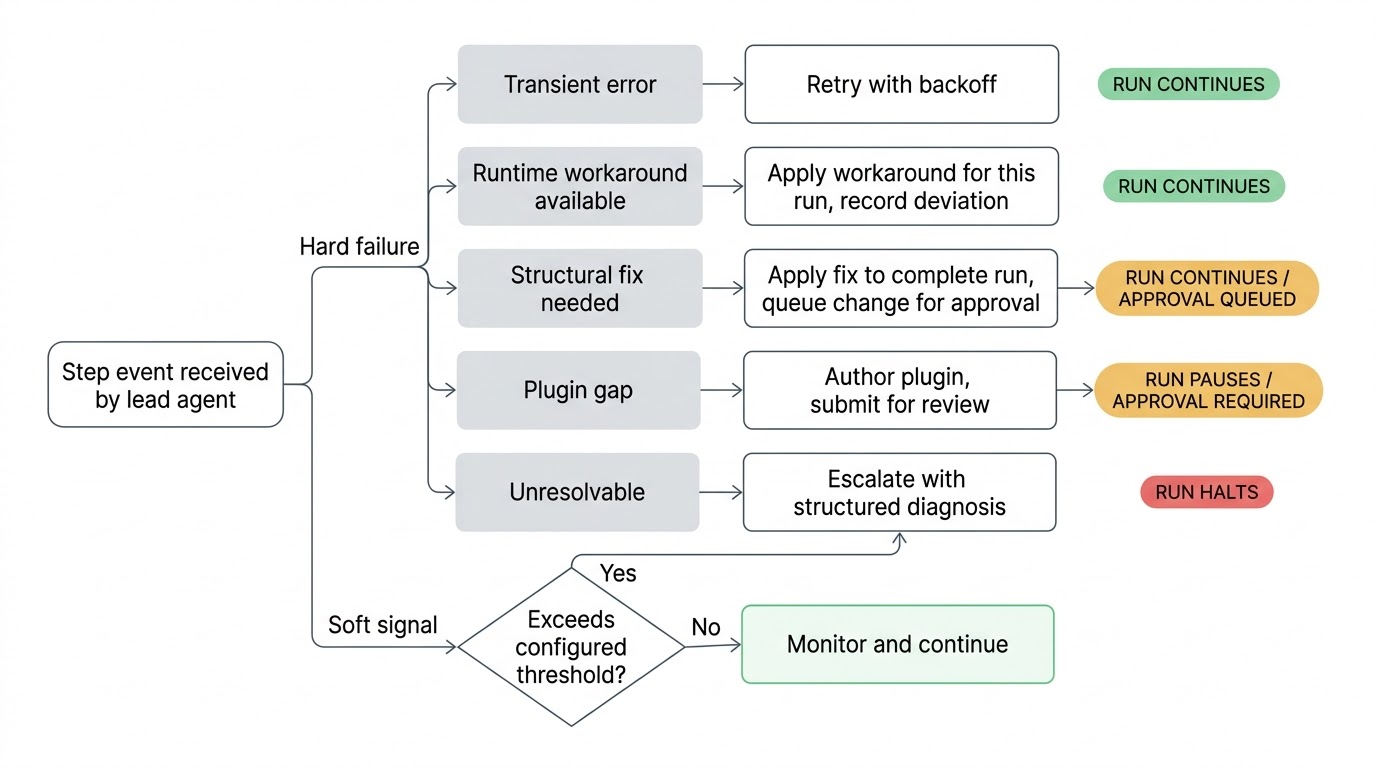
جب کچھ غلط ہو تو lead اسے triage کرتا ہے۔ ایک flaky network call کو backoff کے ساتھ retry ملتی ہے۔ ایک changed API endpoint جسے workaround کیا جا سکے اس run کے لیے work around ہو جاتا ہے۔ Workflow definition میں ایک structural problem کو run مکمل کرنے کے لیے proposed fix ملتی ہے، change permanent ہونے سے پہلے آپ کی approval کے لیے submit ہوتی ہے۔ ایک broken plugin integration کو ایک نیا یا updated plugin author ہو کر review کے لیے submit کیا جاتا ہے۔ اگر lead اپنی کوششیں exhaust کر لے اور issue resolve نہ کر سکے تو structured diagnosis کے ساتھ آپ تک escalate کرتا ہے کہ اس نے کیا try کیا اور root cause کیا سمجھتا ہے۔
Workflow جب بھی safely چل سکے چلتی رہتی ہے۔ اگر ایک step block ہو تو صرف وہ downstream steps جو اس پر depend کرتی ہیں pause ہوتی ہیں جبکہ parallel branches جاری رہتی ہیں۔ Lead dependency graph جانتا ہے اور صرف وہی pause کرتا ہے جو actually blocked ہے۔
Workflows میں آپ جو Context بناتے ہیں وہ کیوں اہم ہے
جو چیز self-healing کو عملاً کام کراتی ہے وہ یہ ہے کہ Triggerfish workflows کو لکھتے وقت سے ہی rich step-level metadata کی ضرورت ہوتی ہے۔ یہ optional نہیں اور اپنی خاطر documentation نہیں؛ یہ وہ ہے جس سے lead agent reasoning کرتا ہے۔
Workflow میں ہر step کے لیے task definition کے علاوہ چار required fields ہیں: ایک description جو بتاتی ہے step mechanically کیا کرتی ہے، ایک intent statement جو بتاتا ہے یہ step کیوں exist کرتی ہے اور کیا business purpose serve کرتی ہے، ایک expects field جو بتاتا ہے یہ کس data کی توقع رکھتا ہے اور prior steps کس state میں ہونے چاہئیں، اور ایک produces field جو بتاتا ہے یہ downstream steps کے consume کرنے کے لیے context میں کیا لکھتا ہے۔
عملی مثال یہ ہے۔ فرض کریں آپ employee access provisioning automate کر رہے ہیں۔ ایک نئے hire کا پیر سے کام شروع ہے اور workflow کو Active Directory میں accounts بنانے، GitHub org membership provision کرنے، Okta groups assign کرنے، اور completion confirm کرتے ہوئے Jira ticket کھولنے کی ضرورت ہے۔ ایک step HR system سے employee record fetch کرتی ہے۔ اس کا intent field صرف "employee record لاؤ" نہیں کہتا۔ یہ پڑھتا ہے: "یہ step ہر downstream provisioning decision کی truth کا source ہے۔ اس record سے role، department، اور start date یہ determine کرتے ہیں کہ کون سے AD groups assign ہوتے ہیں، کون سے GitHub teams provision ہوتی ہیں، اور کون سی Okta policies apply ہوتی ہیں۔ اگر یہ step stale یا incomplete data return کرے تو ہر downstream step غلط access provision کرے گی۔"

Lead وہ intent statement پڑھتا ہے جب step fail ہو اور سمجھتا ہے کیا داؤ پر ہے۔ یہ جانتا ہے کہ partial record کا مطلب ہے access provisioning steps غلط inputs کے ساتھ چلیں گی، ممکنہ طور پر دو دن میں شروع ہونے والے حقیقی شخص کو غلط permissions دیتی ہیں۔ یہ context شکل دیتا ہے کہ یہ recover کرنے کی کیسے کوشش کرتا ہے، کیا downstream steps pause کرتا ہے، اور escalate کرنے پر آپ کو کیا بتاتا ہے۔
ایک اور step اسی workflow میں HR fetch step کا produces field چیک کرتی ہے اور جانتی ہے کہ .employee.role اور .employee.department non-empty strings کی توقع ہے۔ اگر آپ کا HR system API update کرے اور وہ fields .employee.profile.role کے نیچے nested return کرنا شروع کر دے تو lead schema drift detect کرتا ہے، اس run کے لیے runtime mapping apply کرتا ہے تاکہ نیا hire صحیح provision ہو، اور step definition update کرنے کے لیے structural fix propose کرتا ہے۔ آپ نے اس specific case کے لیے schema migration rule یا exception handling نہیں لکھی۔ Lead نے پہلے سے موجود context سے اس تک reasoning کی۔
یہی وجہ ہے کہ workflow authoring quality اہم ہے۔ Metadata ceremony نہیں؛ یہ وہ fuel ہے جس پر self-healing system چلتا ہے۔ Shallow step descriptions والی workflow وہ workflow ہے جس کے بارے میں lead اس وقت reasoning نہیں کر سکتا جب اہم ہو۔
Live Watch کرنا مطلب Failures بننے سے پہلے Problems پکڑنا
چونکہ lead real time میں watch کر رہا ہے، یہ چیزیں actually break ہونے سے پہلے soft signals پر act کر سکتا ہے۔ ایک step جو historically دو سیکنڈ میں complete ہوتی تھی اب چالیس لے رہی ہے۔ ایک step جو ہر prior run میں data return کرتی تھی empty result return کرتی ہے۔ ایک conditional branch لی جاتی ہے جو پوری run history میں کبھی نہیں لی گئی۔ یہ hard errors نہیں اور workflow چلتی رہتی ہے، لیکن یہ signals ہیں کہ environment میں کچھ بدلا ہے۔ اگلا step bad data consume کرنے کی کوشش کرے اس سے پہلے انہیں پکڑنا بہتر ہے۔
ان checks کی sensitivity workflow کے حساب سے configurable ہے۔ ایک nightly report generation کے loose thresholds ہو سکتے ہیں جبکہ access provisioning pipeline قریب سے دیکھتا ہے۔ آپ set کریں کہ کس level کا deviation lead کی توجہ کا مستحق ہے۔
یہ ابھی بھی آپ کی Workflow ہے
Lead agent اور اس کی team آپ کی canonical workflow definition آپ کی approval کے بغیر نہیں بدل سکتی۔ جب lead ایک structural fix propose کرے تو وہ current run مکمل کرنے کے لیے fix apply کرتا ہے اور change ایک proposal کے طور پر submit کرتا ہے۔ آپ اسے اپنے queue میں دیکھتے ہیں، reasoning دیکھتے ہیں، approve یا reject کرتے ہیں۔ اگر آپ reject کریں تو وہ rejection record ہوتا ہے اور اس workflow پر کام کرنے والا ہر future lead جانتا ہے کہ وہی چیز دوبارہ propose نہ کرے۔
ایک چیز ہے جو lead configuration سے قطع نظر کبھی نہیں بدل سکتا: اپنا mandate۔ Workflow definition میں self-healing policy، pause کرنا ہے یا نہیں، کتنی دیر retry کرنا ہے، approval چاہیے یا نہیں، یہ owner-authored policy ہے۔ Lead task definitions patch کر سکتا ہے، API calls update کر سکتا ہے، parameters adjust کر سکتا ہے، اور نئے plugins author کر سکتا ہے۔ یہ اپنے behavior کو govern کرنے والے rules نہیں بدل سکتا۔ وہ boundary hard-coded ہے۔ ایک agent جو اپنی proposals کو govern کرنے والی approval requirement disable کر سکے پورے trust model کو بے معنی کر دے۔
Plugin changes اسی approval path کو follow کرتی ہیں جیسے Triggerfish میں کوئی بھی agent-authored plugin۔ یہ حقیقت کہ plugin ٹوٹی workflow ٹھیک کرنے کے لیے author ہوئی اسے کوئی special trust نہیں دیتی۔ یہ اسی review سے گزرتی ہے جیسے آپ نے agent سے کوئی نئی integration scratch سے بنانے کو کہا ہو۔
ہر Channel پر Management جو آپ پہلے سے استعمال کر رہے ہیں
آپ کو یہ جاننے کے لیے کسی الگ dashboard پر login نہیں کرنا چاہیے کہ آپ کے workflows کیا کر رہے ہیں۔ Self-healing notifications جہاں بھی آپ نے Triggerfish کو reach کرنے کے لیے configure کیا ہے وہاں آتی ہیں: Slack پر intervention summary، Telegram پر approval request، email پر escalation report۔ System urgency کے لحاظ سے مناسب channel پر آپ کے پاس آتا ہے بغیر آپ کے monitoring console refresh کیے۔
Workflow status model اسی کے لیے بنایا گیا ہے۔ Status ایک flat string نہیں بلکہ ایک structured object ہے جو ہر وہ چیز لے کر چلتا ہے جو notification کو meaningful بنانے کے لیے چاہیے: current state، health signal، کیا آپ کے approval queue میں patch ہے، last run کا outcome، اور lead اس وقت کیا کر رہا ہے۔ آپ کا Slack message کہہ سکتا ہے "access provisioning workflow paused ہے، lead ایک plugin fix author کر رہا ہے، approval required ہوگی" ایک ہی notification میں بغیر context ڈھونڈے۔
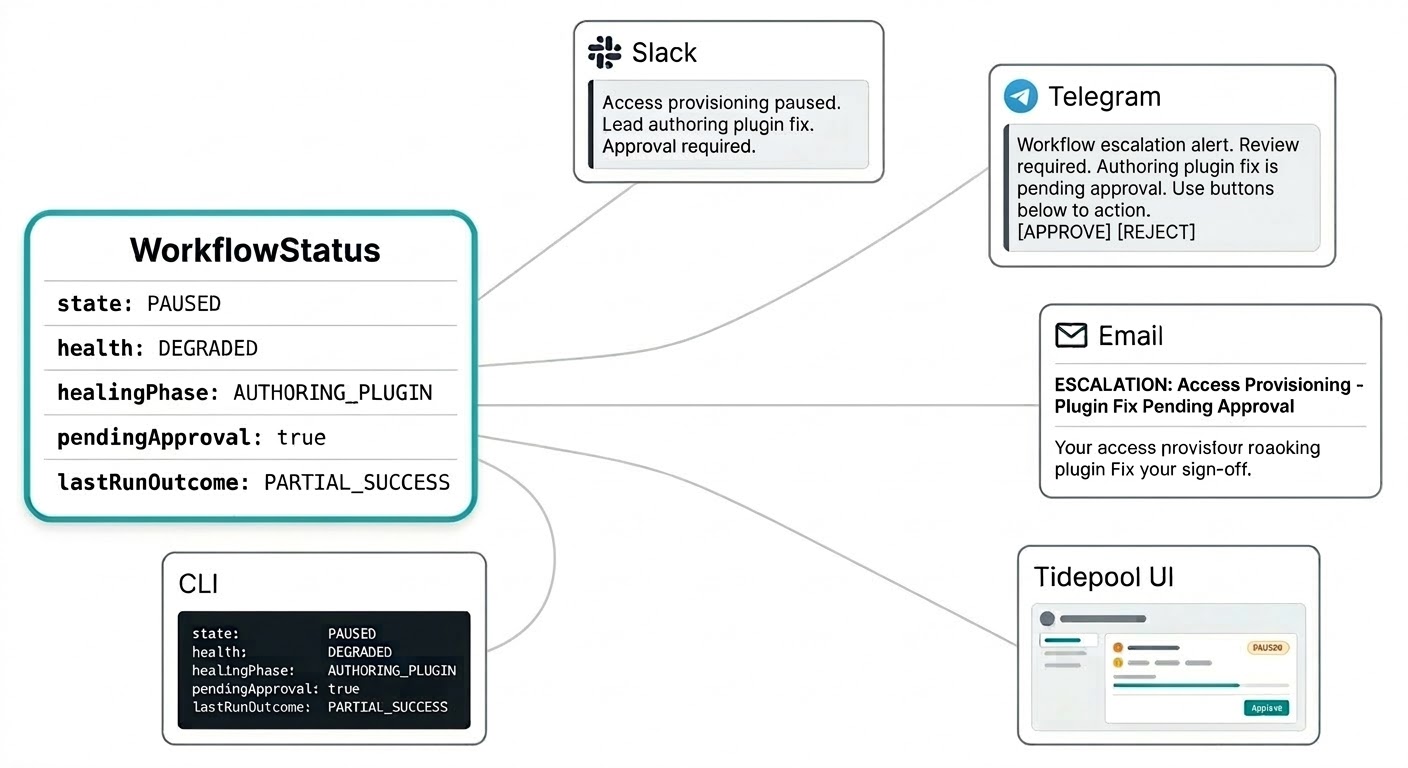
وہی structured status live Tidepool interface کو feed کرتا ہے جب آپ پوری تصویر چاہتے ہیں۔ ایک ہی data، مختلف surface۔
IT Teams کے لیے یہ کیا بدلتا ہے
آپ کی organization میں جو لوگ اپنا ہفتہ ٹوٹے workflows ٹھیک کرنے میں گزارتے ہیں وہ low-skill کام نہیں کر رہے۔ یہ distributed systems debug کر رہے ہیں، API changelogs پڑھ رہے ہیں، اور reverse-engineer کر رہے ہیں کہ ایک workflow جو کل ٹھیک چل رہی تھی آج کیوں fail ہو رہی ہے۔ یہ valuable judgment ہے، اور ابھی یہ تقریباً مکمل طور پر نئی automation بنانے یا مشکل مسائل حل کرنے کی بجائے موجودہ automation کو زندہ رکھنے میں consume ہو رہی ہے۔
Self-healing workflows اس judgment کو ختم نہیں کرتے، لیکن یہ shift کرتے ہیں کہ یہ کب apply ہوتی ہے۔ رات کو ٹوٹی workflow firefight کرنے کی بجائے، آپ صبح ایک proposed fix review کر رہے ہیں اور فیصلہ کر رہے ہیں کہ lead کی diagnosis درست ہے یا نہیں۔ آپ دباؤ میں patch کے author نہیں بلکہ proposed change کے approver ہیں۔
یہ وہ labor model ہے جس کے گرد Triggerfish بنایا گیا ہے: humans agent کے کام کو review اور approve کر رہے ہیں بجائے اس کام کو execute کرنے کے جو agents handle کر سکتے ہیں۔ Automation coverage بڑھتی ہے جبکہ maintenance burden کم ہوتا ہے، اور جو team 75 فیصد وقت upkeep پر گزار رہی تھی اس کا زیادہ تر وقت ان چیزوں کی طرف redirect ہو سکتا ہے جن کے لیے واقعی human judgment چاہیے۔
آج Shipping
Self-healing workflows آج Triggerfish workflow engine میں ایک optional feature کے طور پر ship ہو رہے ہیں۔ یہ workflow کے حساب سے opt-in ہے، workflow metadata block میں configure ہوتا ہے۔ اگر آپ اسے enable نہ کریں تو آپ کے workflows کے چلنے کے طریقے میں کچھ نہیں بدلتا۔
یہ اہم ہے نہ صرف اس لیے کہ یہ مشکل technical problem ہے (حالانکہ ہے)، بلکہ اس لیے کہ یہ سیدھے اس چیز کو address کرتا ہے جس نے enterprise automation کو ضرورت سے زیادہ مہنگا اور تکلیف دہ بنایا ہے۔ Workflow maintenance team وہ پہلی job ہونی چاہیے جو AI automation لے۔ Technology کا یہ صحیح استعمال ہے، اور یہی Triggerfish نے بنایا ہے۔
اگر آپ اس کے کام کرنے کے طریقے کا جائزہ لینا چاہتے ہیں تو پوری spec repository میں ہے۔ اگر آپ اسے آزمانا چاہتے ہیں تو workflow-builder skill آپ کو اپنی پہلی self-healing workflow لکھنے میں رہنمائی کرے گی۔