
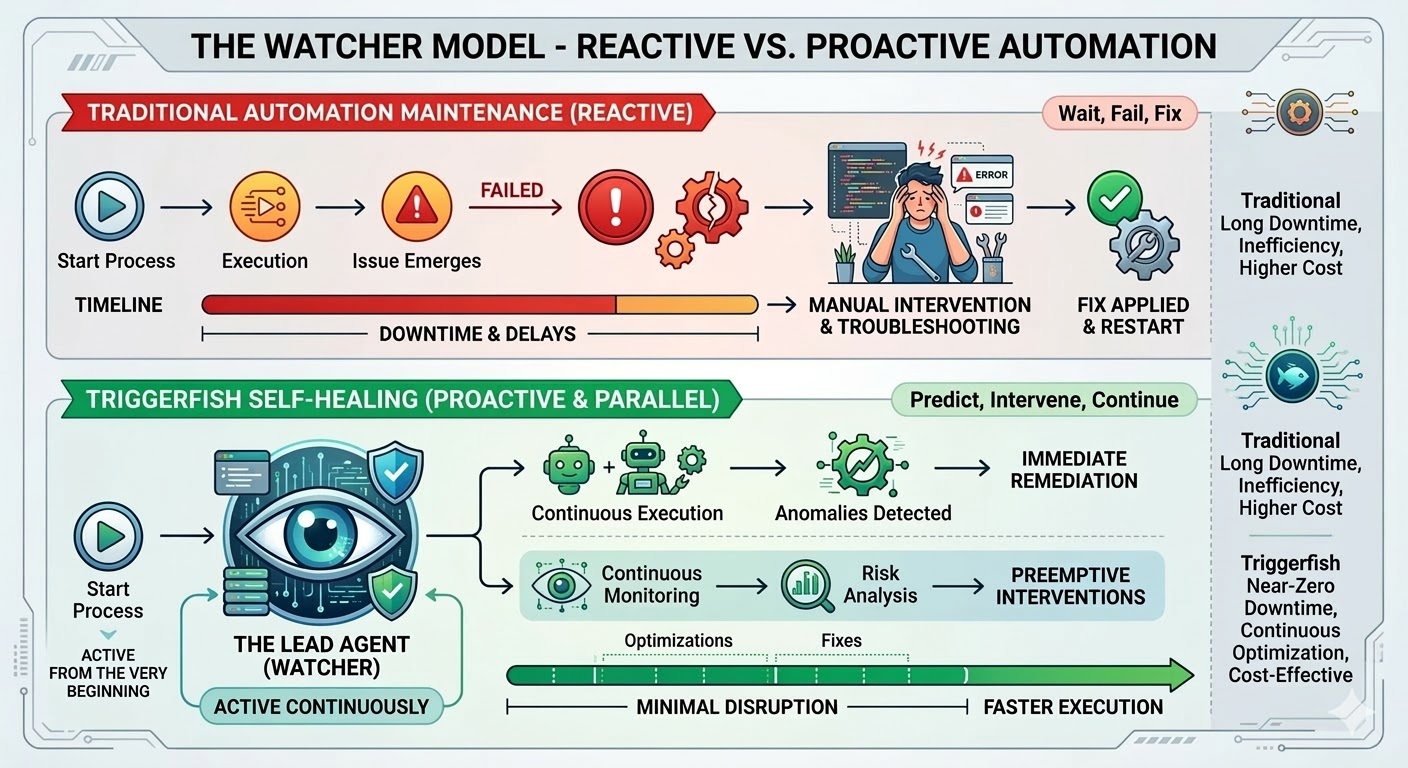
प्रत्येक enterprise automation program त्याच wall ला hits करतो. ServiceNow ticket routing, Terraform drift remediation, certificate rotation, AD group provisioning, SCCM patch deployment, CI/CD pipeline orchestration. पहिले दहा किंवा वीस workflows investment easily justify करतात, आणि ROI math तोपर्यंत hold up होतो जोपर्यंत workflow count शेकड्यांमध्ये cross होत नाही आणि IT team च्या week चा meaningful share नवीन automation build करण्यापासून existing automation fall over होण्यापासून keep करण्याकडे shift होत नाही.
Payer portal त्याचे auth flow redesign करतो आणि claims submission workflow authentication बंद करतो. Salesforce metadata update push करतो आणि lead-to-opportunity pipeline मधील field mapping nulls लिहू लागतो. AWS API version deprecate करतो आणि एका वर्षासाठी clean run होणारी Terraform plan प्रत्येक apply वर 400s throw करू लागते. कोणी ticket file करते, कोणी काय changed ते figure out करते, patches करते, tests करते, fix deploy करते, आणि दरम्यान जे process ते automate करत होते ते एकतर manually run झाले किंवा अजिबात नाही.
हे maintenance trap आहे, आणि ते structural आहे, implementation failure नाही. Traditional automation exact paths follow करतो, exact patterns match करतो, आणि workflow authored होताना जे exist होते त्यापासून reality deviate होताच break होतो. Research consistent आहे: organizations त्यांच्या total automation program costs चे 70 ते 75 percent नवीन workflows build करण्यात नाही तर आधीच असलेल्या maintain करण्यात spend करतात. Large deployments मध्ये, 45 percent workflows प्रत्येक single week break होतात.
Triggerfish चे workflow engine हे बदलण्यासाठी built केले होते. Self-healing workflows आज ship होत आहेत, आणि ते platform मध्ये आतापर्यंतची सर्वात significant capability represent करतात.
Self-Healing म्हणजे खरोखर काय
Phrase loosely वापरला जातो, त्यामुळे हे काय आहे ते directly सांगतो.
Triggerfish workflow वर self-healing enable केल्यावर, lead agent त्या workflow सुरू होताच spawned होतो. जेव्हा काहीतरी break होते तेव्हा नाही; ते पहिल्या step पासून watch करत आहे, workflow progress होताना engine मधून live event stream receive करतो आणि real time मध्ये प्रत्येक step observe करतो.
Lead ला single step run होण्यापूर्वी full workflow definition माहीत असतो, प्रत्येक step मागील intent सह, प्रत्येक step त्याच्या आधीच्यांकडून काय expect करतो, आणि ते नंतरच्यांसाठी काय produce करते. Prior runs चा history देखील माहीत आहे: काय succeed झाले, काय failed, कोणते patches proposed झाले आणि human ने approve किंवा reject केले का. Act करण्यायोग्य काहीतरी identify केल्यावर, तो सर्व context already memory मध्ये आहे कारण ते whole time watch करत होते rather than after the fact reconstruct करण्याऐवजी.
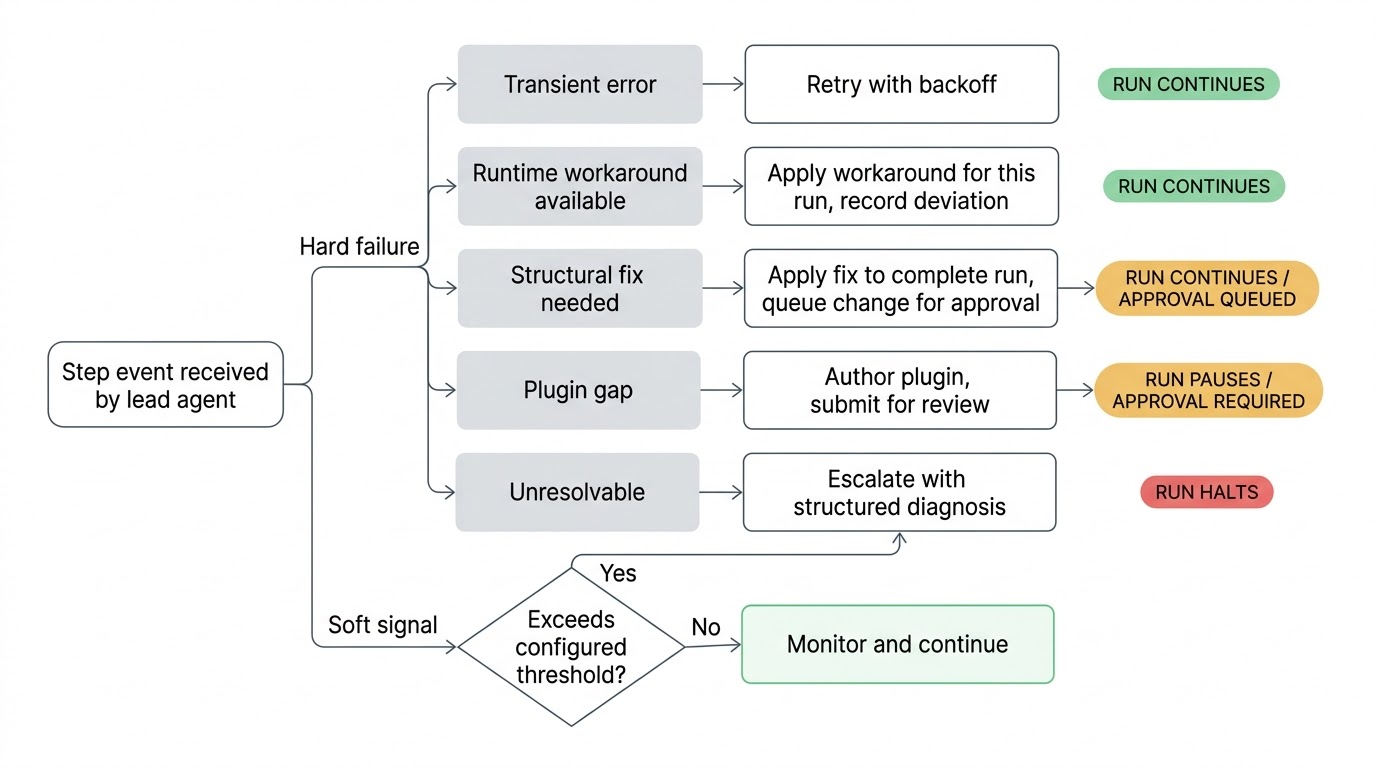
काहीतरी चुकीचे झाल्यावर, lead triage करतो. Flaky network call ला backoff सह retry मिळतो. Changed API endpoint जे worked around होऊ शकतो ते या run साठी worked around होतो. Workflow definition मधील structural problem ला run complete करण्यासाठी proposed fix apply होतो, permanent होण्यापूर्वी तुमच्या approval साठी change submitted होतो. Broken plugin integration साठी नवीन किंवा updated plugin authored आणि review साठी submitted होतो. Lead त्याचे attempts exhausted करतो आणि issue resolve करू शकत नसल्यास, ते काय try केले आणि root cause काय आहे याचे structured diagnosis सह तुम्हाला escalate करतो.
Workflow जेव्हा safely शक्य असेल तेव्हा running ठेवतो. Step blocked असल्यास, फक्त त्यावर depend असलेले downstream steps pause होतात while parallel branches continue होतात. Lead dependency graph जाणतो आणि फक्त actually blocked असलेले pause करतो.
Workflows मध्ये Build करता येणारा Context का महत्त्वाचा आहे
Self-healing practice मध्ये काम करणारी गोष्ट म्हणजे Triggerfish workflows ला तुम्ही त्या लिहितानाच rich step-level metadata आवश्यक आहे. हे optional नाही आणि हे स्वतःसाठी documentation नाही; lead agent हेच reason करतो.
Workflow मधील प्रत्येक step ला task definition च्या पलीकडे चार required fields आहेत: step mechanically काय करतो याचे description, हे step का exist करतो आणि कोणता business purpose serve करतो याचे intent statement, ते कोणता data receive करत असल्याचे assume करतो आणि prior steps कोणत्या state मध्ये असणे आवश्यक आहे याचे expects field, आणि downstream steps consume करण्यासाठी context ला काय writes करतो याचे produces field.
Practice मध्ये हे कसे दिसते ते पाहूया. तुम्ही employee access provisioning automate करत आहात असे म्हणूया. नवीन hire Monday ला सुरू होतो आणि workflow ला Active Directory मध्ये accounts create करणे, त्यांचे GitHub org membership provision करणे, त्यांचे Okta groups assign करणे, आणि completion confirm करणारे Jira ticket उघडणे आवश्यक आहे. एक step तुमच्या HR system मधून employee record fetch करतो. त्याचे intent field फक्त "employee record मिळवा" असे म्हणत नाही. ते असे reads: "हे step प्रत्येक downstream provisioning decision साठी truth चा source आहे. या record मधील Role, department, आणि start date कोणते AD groups assign होतात, कोणते GitHub teams provision होतात, आणि कोणते Okta policies apply होतात ते determine करतात. हे step stale किंवा incomplete data return केल्यास, प्रत्येक downstream step wrong access provision करेल."

Step fail झाल्यावर lead ते intent statement वाचतो आणि काय stake आहे ते समजतो. Partial record म्हणजे access provisioning steps bad inputs सह run होतील, शक्यतः दोन दिवसांत सुरू होणाऱ्या real person ला wrong permissions देणे. तो context recovery कसे करायचे, downstream steps pause करायचे का, आणि escalate केल्यास काय सांगायचे ते shape करतो.
त्याच workflow मधील आणखी एक step HR fetch step चे produces field check करतो आणि .employee.role आणि .employee.department non-empty strings म्हणून expect करतो. तुमचे HR system API update करते आणि ते fields employee.profile.role खाली nest करण्यास सुरू करते, lead schema drift detect करतो, या run साठी runtime mapping apply करतो जेणेकरून नवीन hire correctly provision होईल, आणि step definition update करण्यासाठी structural fix propose करतो. तुम्ही या specific case साठी schema migration rule किंवा exception handling लिहिले नव्हते. Lead ने already तेथे असलेल्या context मधून ते reason केले.
Workflow authoring quality का महत्त्वाचे आहे हेच कारण आहे. Metadata ceremony नाही; हे self-healing system run होण्याचे fuel आहे. Shallow step descriptions असलेला workflow म्हणजे lead महत्त्वाच्या वेळी reason करू शकत नसलेला workflow आहे.
Live Watch करणे म्हणजे Failures होण्यापूर्वी Problems Catch करणे
Lead real time मध्ये watch करत असल्यामुळे, गोष्टी actually break होण्यापूर्वी soft signals वर act करू शकतो. Step जे historically दोन seconds मध्ये complete होते ते आता चाळीस घेत आहे. प्रत्येक prior run मध्ये data return करणारा step empty result return करतो. Conditional branch घेतला जात आहे जो full run history मध्ये कधीच घेतला गेला नव्हता. या हार्ड errors नाहीत आणि workflow running ठेवतो, पण ते environment मध्ये काहीतरी changed आहे असे signals आहेत. पुढील step bad data consume करण्याचा प्रयत्न करण्यापूर्वी ते catch करणे बरे आहे.
या checks ची sensitivity per workflow configurable आहे. Nightly report generation ला loose thresholds असू शकतात while access provisioning pipeline closely watch करतो. Lead च्या attention warranting deviation level तुम्ही set करा.
हे अजूनही तुमचे Workflow आहे
Lead agent आणि त्याची team तुमच्या canonical workflow definition तुमच्या approval शिवाय बदलू शकत नाहीत. Lead structural fix propose केल्यावर, current run complete करण्यासाठी fix apply करतो आणि change proposal म्हणून submit करतो. तुम्ही ते queue मध्ये पाहता, reasoning पाहता, approve किंवा reject करता. Reject केल्यास, ते rejection recorded होते आणि त्या workflow वर काम करणारा प्रत्येक future lead same thing पुन्हा propose करू नये हे जाणतो.
Configuration काहीही असो, lead कधीही बदलू शकत नाही ती एक गोष्ट: त्याची स्वतःची mandate. Workflow definition मधील self-healing policy, pause करायचे की नाही, किती retry करायचे, approval आवश्यक आहे की नाही, owner-authored policy आहे. Lead task definitions patch करू शकतो, API calls update करू शकतो, parameters adjust करू शकतो, आणि नवीन plugins author करू शकतो. स्वतःच्या behavior governing rules बदलू शकत नाही. ती boundary hard-coded आहे. स्वतःच्या proposals governing approval requirement disable करू शकणारा agent whole trust model meaningless करेल.
Plugin changes Triggerfish मध्ये agent authored कोणत्याही plugin प्रमाणे same approval path follow करतात. Plugin broken workflow fix करण्यासाठी authored केले हे त्याला कोणताही special trust देत नाही. तुम्ही agent ला नवीन integration scratch मधून build करण्यास सांगितल्यासारखे same review मधून जाते.
तुम्ही आधीच वापरत असलेल्या प्रत्येक Channel वर हे Manage करणे
तुमचे workflows काय करत आहेत ते जाणण्यासाठी separate dashboard मध्ये log in करायला नको. Self-healing notifications जेथे Triggerfish तुम्हाला reach करण्यासाठी configured केले आहे तेथे येतात: Slack वर intervention summary, Telegram वर approval request, email द्वारे escalation report. System monitoring console refresh न करता urgency साठी sense करणाऱ्या channel वर तुम्हाला येतो.
Workflow status model याच्यासाठी built आहे. Status flat string नाही तर structured object आहे जे notification ला meaningful असण्यासाठी सर्वकाही carries करतो: current state, health signal, patch approval queue मध्ये आहे का, last run चे outcome, आणि lead currently काय करत आहे. तुमचा Slack message single notification मध्ये "access provisioning workflow paused आहे, lead plugin fix authoring करत आहे, approval required असेल" असे म्हणू शकतो, context शोधण्याची आवश्यकता नाही.
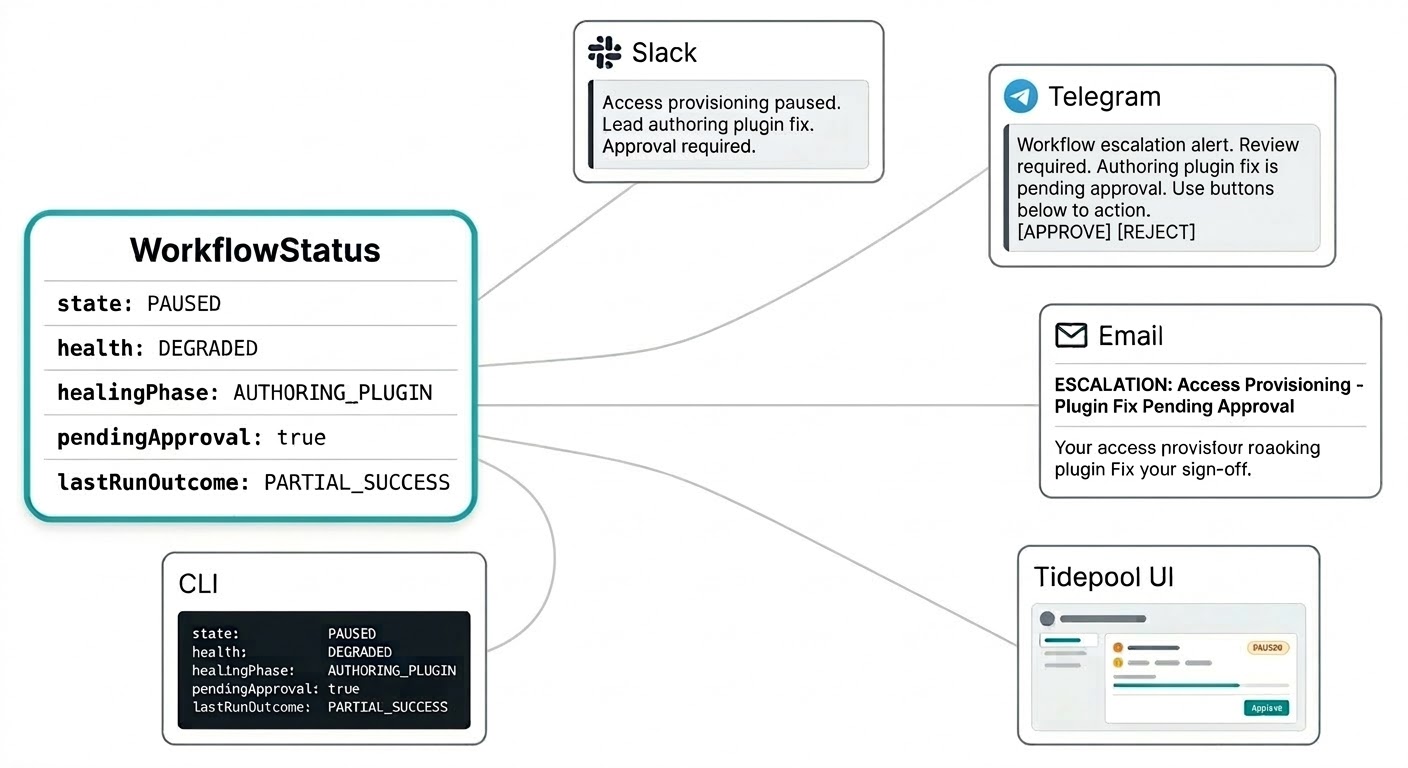
तोच structured status पूर्ण picture हवे असल्यावर live Tidepool interface feed करतो. Same data, different surface.
IT Teams साठी हे खरोखर काय बदलते
तुमच्या organization मधील broken workflows fix करण्यात त्यांचा week spend करणारे लोक low-skill काम करत नाहीत. ते distributed systems debug करत आहेत, API changelogs वाचत आहेत, आणि काल fine run झालेला workflow आज का failing आहे ते reverse-engineer करत आहेत. ते valuable judgment आहे, आणि सध्या ते जवळजवळ पूर्णपणे नवीन automation build करण्यापेक्षा किंवा harder problems solve करण्यापेक्षा existing automation alive ठेवण्याने consumed आहे.
Self-healing workflows ते judgment eliminate करत नाहीत, पण ते apply होण्याची वेळ shift करतात. Midnight ला broken workflow firefighting करण्याऐवजी, तुम्ही सकाळी proposed fix review करत आहात आणि lead चे diagnosis right आहे का ते decide करत आहात. तुम्ही proposed change चे approver आहात, pressure खाली patch चे author नाही.
हाच labor model आहे ज्याभोवती Triggerfish built आहे: agents handle करू शकत असलेले काम execute करण्याऐवजी agent काम review आणि approve करणारे humans. Automation coverage वाढते while maintenance burden कमी होतो, आणि upkeep वर 75 percent वेळ spend करणारी team त्या वेळातील बहुतेक human judgment खरोखर आवश्यक असलेल्या गोष्टींकडे redirect करू शकते.
आज Shipping होत आहे
Self-healing workflows आज Triggerfish workflow engine मध्ये optional feature म्हणून ship होत आहेत. हे workflow metadata block मध्ये configured, per workflow opt-in आहे. Enable नाही केल्यास, तुमचे workflows कसे run होतात त्यात काहीही बदलत नाही.
हे एक hard technical problem म्हणून नव्हे (जरी आहे) तर enterprise automation खर्चिक आणि आवश्यकतेपेक्षा जास्त painful बनवणाऱ्या गोष्टीला directly address करते म्हणून महत्त्वाचे आहे. Workflow maintenance team ही पहिली job असावी जी AI automation घेते. Technology चा हा right use आहे, आणि Triggerfish ने हे built केले.
हे कसे काम करते ते deeper मध्ये जायचे असल्यास, full spec repository मध्ये आहे. Try करायचे असल्यास, workflow-builder skill तुम्हाला तुमचा पहिला self-healing workflow लिहिण्यातून walk through करेल.