
Tout programme d'automatisation en entreprise finit par se heurter au même mur. Routage des tickets ServiceNow, remédiation de la dérive Terraform, rotation des certificats, provisionnement des groupes Active Directory, déploiement de correctifs SCCM, orchestration de pipelines CI/CD. Les dix ou vingt premiers workflows justifient facilement l'investissement, et le calcul du retour sur investissement tient la route jusqu'à ce que le nombre de workflows se compte en centaines et qu'une part significative de la semaine de l'équipe IT passe de la construction de nouvelles automatisations à la maintenance de celles qui menacent de tomber en panne.
Un portail de paiement remanie son flux d'authentification et le workflow de soumission des demandes cesse de s'authentifier. Salesforce pousse une mise à jour de métadonnées et un mapping de champs dans le pipeline lead-to-opportunity commence à écrire des valeurs nulles. AWS déprécie une version d'API et un plan Terraform qui tournait proprement depuis un an commence à renvoyer des erreurs 400 à chaque apply. Quelqu'un ouvre un ticket, quelqu'un d'autre identifie ce qui a changé, applique un correctif, le teste, déploie la correction, et pendant ce temps le processus qu'il était censé automatiser a été exécuté manuellement ou ne l'a pas été du tout.
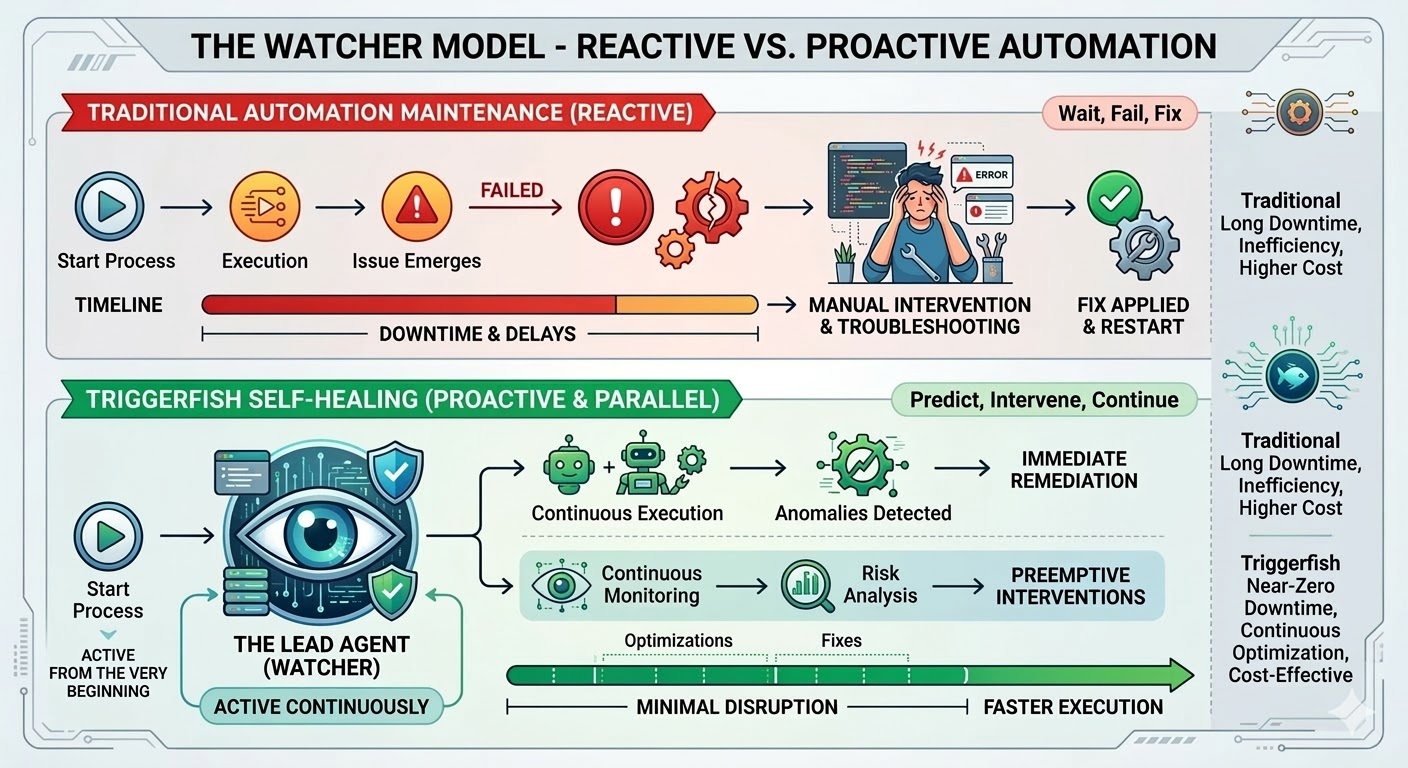
C'est le piège de la maintenance, et il est structurel plutôt qu'un défaut d'implémentation. L'automatisation traditionnelle suit des chemins exacts, recherche des motifs exacts, et casse dès que la réalité dévie de ce qui existait au moment où le workflow a été conçu. La recherche est unanime : les organisations consacrent 70 à 75 pour cent du coût total de leur programme d'automatisation non pas à construire de nouveaux workflows, mais à maintenir ceux qui existent déjà. Dans les déploiements de grande envergure, 45 pour cent des workflows tombent en panne chaque semaine.
Le moteur de workflows de Triggerfish a été conçu pour changer cette donne. Les workflows auto-réparateurs sont disponibles dès aujourd'hui, et ils représentent la capacité la plus significative de la plateforme à ce jour.
Ce que signifie réellement l'auto-réparation
L'expression est utilisée à toutes les sauces, alors soyons précis sur ce dont il s'agit.
Lorsque vous activez l'auto-réparation sur un workflow Triggerfish, un agent principal est instancié dès que ce workflow commence à s'exécuter. Il ne se lance pas quand quelque chose casse ; il observe dès la première étape, recevant un flux d'événements en direct du moteur à mesure que le workflow progresse et observant chaque étape en temps réel.
L'agent principal connaît la définition complète du workflow avant même qu'une seule étape ne s'exécute, y compris l'intention derrière chaque étape, ce que chaque étape attend de celles qui la précèdent, et ce qu'elle produit pour celles qui suivent. Il connaît également l'historique des exécutions précédentes : ce qui a réussi, ce qui a échoué, quels correctifs ont été proposés et si un humain les a approuvés ou rejetés. Lorsqu'il identifie quelque chose qui mérite une intervention, tout ce contexte est déjà en mémoire parce qu'il observait depuis le début plutôt que de le reconstituer après coup.
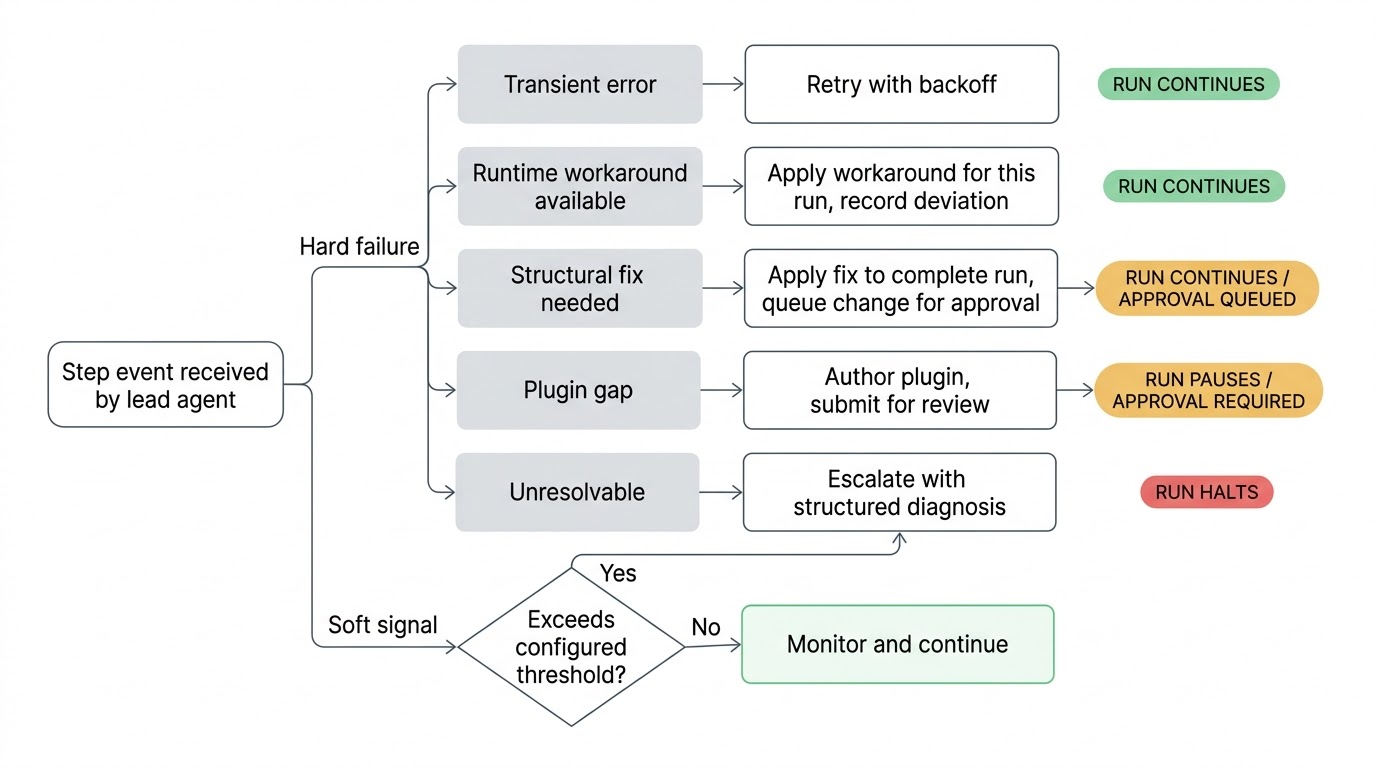
Quand quelque chose ne va pas, l'agent principal procède au triage. Un appel réseau instable fait l'objet d'une nouvelle tentative avec backoff exponentiel. Un endpoint d'API modifié qui peut être contourné est contourné pour cette exécution. Un problème structurel dans la définition du workflow donne lieu à un correctif proposé, appliqué pour terminer l'exécution en cours, puis soumis à votre approbation avant de devenir permanent. Une intégration de plugin défaillante déclenche la rédaction d'un nouveau plugin ou la mise à jour d'un plugin existant, soumis pour revue. Si l'agent principal épuise ses tentatives et ne parvient pas à résoudre le problème, il vous escalade avec un diagnostic structuré de ce qu'il a essayé et de ce qu'il pense être la cause racine.
Le workflow continue de s'exécuter dès que cela peut se faire en toute sécurité. Si une étape est bloquée, seules les étapes en aval qui en dépendent sont mises en pause tandis que les branches parallèles continuent. L'agent principal connaît le graphe de dépendances et ne met en pause que ce qui est réellement bloqué.
Pourquoi le contexte que vous intégrez dans les workflows est déterminant
Ce qui fait fonctionner l'auto-réparation en pratique, c'est que les workflows Triggerfish exigent des métadonnées riches au niveau de chaque étape dès leur conception. Ce n'est pas optionnel et ce n'est pas de la documentation pour le plaisir ; c'est ce sur quoi l'agent principal raisonne.
Chaque étape d'un workflow possède quatre champs obligatoires au-delà de la définition de la tâche elle-même : une description de ce que l'étape fait mécaniquement, une déclaration d'intention expliquant pourquoi cette étape existe et quel objectif métier elle sert, un champ expects décrivant quelles données elle suppose recevoir et dans quel état les étapes précédentes doivent se trouver, et un champ produces décrivant ce qu'elle écrit dans le contexte pour les étapes en aval.
Voici ce que cela donne en pratique. Imaginons que vous automatisez le provisionnement des accès d'un nouvel employé. Un nouvel embauché commence lundi et le workflow doit créer des comptes dans Active Directory, provisionner son appartenance à l'organisation GitHub, attribuer ses groupes Okta, et ouvrir un ticket Jira confirmant l'achèvement. Une étape récupère le dossier de l'employé depuis votre système RH. Son champ d'intention ne dit pas simplement "récupérer le dossier de l'employé". Il indique : "Cette étape est la source de vérité pour toute décision de provisionnement en aval. Le rôle, le département et la date de début issus de ce dossier déterminent quels groupes Active Directory sont attribués, quelles équipes GitHub sont provisionnées, et quelles politiques Okta s'appliquent. Si cette étape retourne des données obsolètes ou incomplètes, chaque étape en aval provisionnera les mauvais accès."

L'agent principal lit cette déclaration d'intention lorsque l'étape échoue et comprend ce qui est en jeu. Il sait qu'un dossier partiel signifie que les étapes de provisionnement d'accès vont s'exécuter avec des entrées erronées, attribuant potentiellement de mauvaises permissions à une vraie personne qui commence dans deux jours. Ce contexte détermine comment il tente la récupération, s'il met en pause les étapes en aval, et ce qu'il vous communique en cas d'escalade.
Une autre étape du même workflow vérifie le champ produces de l'étape de récupération RH et sait qu'elle attend .employee.role et .employee.department comme chaînes non vides. Si votre système RH met à jour son API et commence à retourner ces champs imbriqués sous .employee.profile.role, l'agent principal détecte la dérive de schéma, applique un mapping à la volée pour cette exécution afin que le nouvel embauché soit correctement provisionné, et propose un correctif structurel pour mettre à jour la définition de l'étape. Vous n'avez pas écrit de règle de migration de schéma ni de gestion d'exception pour ce cas précis. L'agent principal a raisonné jusqu'à la solution à partir du contexte déjà présent.
C'est pourquoi la qualité de conception des workflows est importante. Les métadonnées ne sont pas du formalisme ; elles sont le carburant dont le système d'auto-réparation a besoin. Un workflow avec des descriptions d'étapes superficielles est un workflow sur lequel l'agent principal ne pourra pas raisonner quand ça compte.
Observer en temps réel, c'est détecter les problèmes avant qu'ils ne deviennent des pannes
Parce que l'agent principal observe en temps réel, il peut agir sur des signaux faibles avant que les choses ne cassent réellement. Une étape qui s'exécute historiquement en deux secondes prend maintenant quarante secondes. Une étape qui retournait des données à chaque exécution précédente retourne un résultat vide. Une branche conditionnelle est empruntée alors qu'elle ne l'avait jamais été dans tout l'historique d'exécution. Aucun de ces cas n'est une erreur franche et le workflow continue de tourner, mais ce sont des signaux que quelque chose a changé dans l'environnement. Mieux vaut les détecter avant que l'étape suivante ne tente de consommer des données erronées.
La sensibilité de ces vérifications est configurable par workflow. Une génération de rapports nocturne peut avoir des seuils larges tandis qu'un pipeline de provisionnement d'accès surveille de près. Vous définissez quel niveau de déviation mérite l'attention de l'agent principal.
C'est toujours votre workflow
L'agent principal et son équipe ne peuvent pas modifier la définition canonique de votre workflow sans votre approbation. Lorsque l'agent principal propose un correctif structurel, il applique le correctif pour terminer l'exécution en cours et soumet la modification sous forme de proposition. Vous la voyez dans votre file d'attente, vous voyez le raisonnement, vous approuvez ou rejetez. Si vous rejetez, ce rejet est enregistré et chaque futur agent principal travaillant sur ce workflow sait qu'il ne doit pas proposer la même chose à nouveau.
Il y a une chose que l'agent principal ne peut jamais modifier, quelle que soit la configuration : son propre mandat. La politique d'auto-réparation dans la définition du workflow — s'il faut mettre en pause, combien de temps réessayer, si l'approbation est requise — est une politique définie par le propriétaire. L'agent principal peut corriger des définitions de tâches, mettre à jour des appels API, ajuster des paramètres et rédiger de nouveaux plugins. Il ne peut pas modifier les règles qui gouvernent son propre comportement. Cette frontière est codée en dur. Un agent qui pourrait désactiver l'exigence d'approbation régissant ses propres propositions rendrait l'ensemble du modèle de confiance caduque.
Les modifications de plugins suivent le même parcours d'approbation que tout plugin rédigé par un agent dans Triggerfish. Le fait que le plugin ait été créé pour corriger un workflow défaillant ne lui confère aucune confiance particulière. Il passe par la même revue que si vous aviez demandé à un agent de vous construire une nouvelle intégration de zéro.
Gérer tout cela depuis chaque canal que vous utilisez déjà
Vous ne devriez pas avoir à vous connecter à un tableau de bord séparé pour savoir ce que font vos workflows. Les notifications d'auto-réparation arrivent là où vous avez configuré Triggerfish pour vous joindre : un résumé d'intervention sur Slack, une demande d'approbation sur Telegram, un rapport d'escalade par email. Le système vient à vous sur le canal adapté à l'urgence sans que vous rafraîchissiez une console de supervision.
Le modèle de statut des workflows est conçu pour cela. Le statut n'est pas une simple chaîne de caractères mais un objet structuré qui porte tout ce dont une notification a besoin pour être pertinente : l'état actuel, le signal de santé, si un correctif attend dans votre file d'approbation, le résultat de la dernière exécution, et ce que l'agent principal est en train de faire. Votre message Slack peut indiquer "le workflow de provisionnement d'accès est en pause, l'agent principal rédige un correctif de plugin, une approbation sera requise" en une seule notification sans avoir à chercher le contexte.
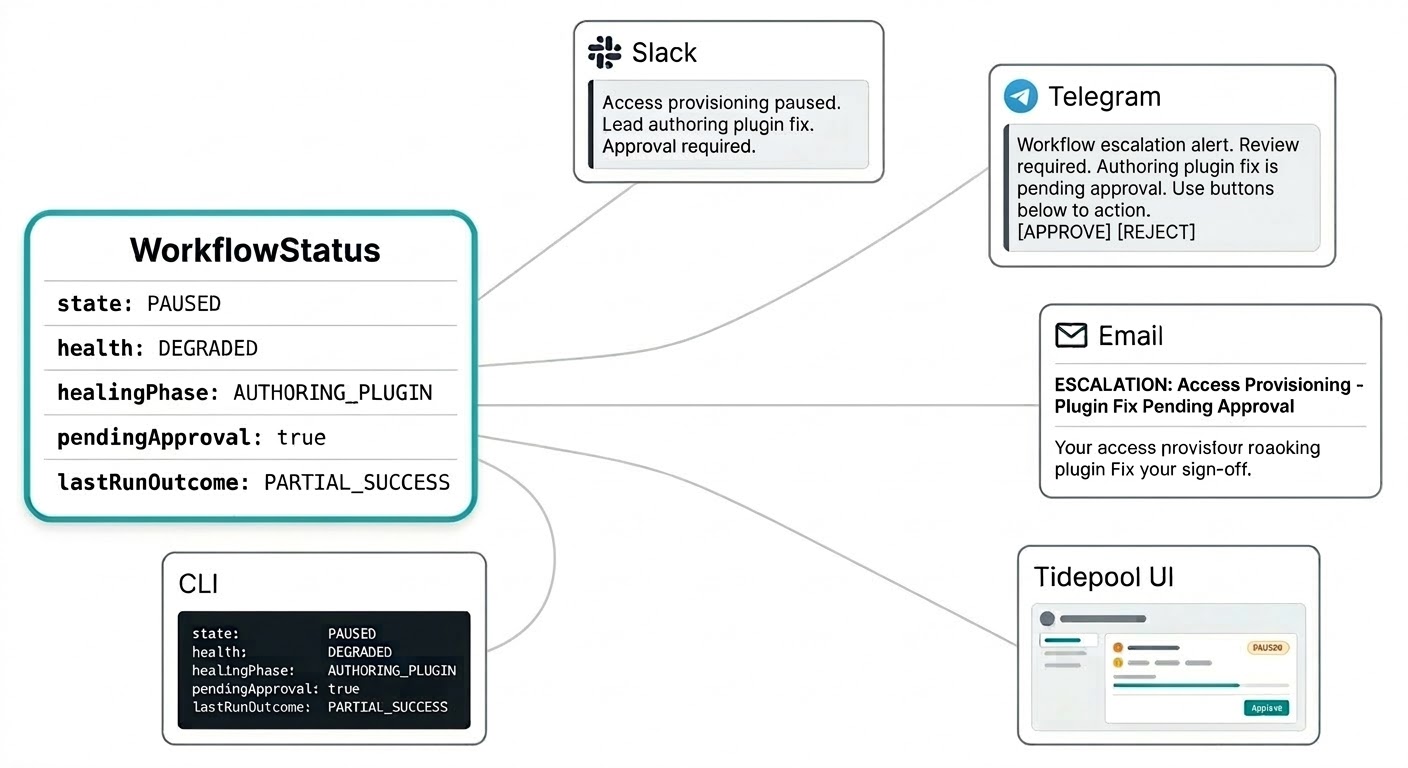
Ce même statut structuré alimente l'interface Tidepool en temps réel lorsque vous voulez la vue d'ensemble. Mêmes données, surface différente.
Ce que cela change concrètement pour les équipes IT
Les personnes de votre organisation qui passent leur semaine à réparer des workflows cassés ne font pas un travail de faible qualification. Elles déboguent des systèmes distribués, lisent des changelogs d'API, et tentent de comprendre par rétro-ingénierie pourquoi un workflow qui fonctionnait hier échoue aujourd'hui. C'est un jugement précieux, et actuellement il est presque entièrement absorbé par le maintien en vie de l'automatisation existante plutôt que par la construction de nouvelles automatisations ou la résolution de problèmes plus complexes.
Les workflows auto-réparateurs n'éliminent pas ce jugement, mais ils déplacent le moment où il est sollicité. Au lieu de combattre un incendie sur un workflow cassé à minuit, vous examinez un correctif proposé le matin et décidez si le diagnostic de l'agent principal est juste. Vous êtes l'approbateur d'une modification proposée, pas l'auteur d'un correctif sous pression.
C'est le modèle de travail sur lequel Triggerfish est bâti : les humains examinent et approuvent le travail des agents plutôt que d'exécuter le travail que les agents peuvent prendre en charge. La couverture d'automatisation augmente tandis que la charge de maintenance diminue, et l'équipe qui consacrait 75 pour cent de son temps à la maintenance peut réorienter l'essentiel de ce temps vers des tâches qui requièrent véritablement le jugement humain.
Disponible dès aujourd'hui
Les workflows auto-réparateurs sont disponibles dès aujourd'hui en tant que fonctionnalité optionnelle du moteur de workflows Triggerfish. L'activation se fait par workflow, configurée dans le bloc de métadonnées du workflow. Si vous ne l'activez pas, rien ne change dans le fonctionnement de vos workflows.
Cela compte non pas parce que c'est un problème technique difficile (bien qu'il le soit), mais parce que cela s'attaque directement à ce qui rend l'automatisation en entreprise plus coûteuse et plus pénible qu'elle ne devrait l'être. L'équipe de maintenance des workflows devrait être le premier poste que l'automatisation par IA prend en charge. C'est le bon usage de cette technologie, et c'est ce que Triggerfish a construit.
Si vous voulez approfondir le fonctionnement, la spécification complète est dans le dépôt. Si vous voulez essayer, le skill workflow-builder vous guidera dans la création de votre premier workflow auto-réparateur.