
Varje företagsautomatiseringsprogram stöter på samma vägg. ServiceNow-ärendesortering, Terraform-driftsavvikelsekorrektion, certifikatrotation, AD-gruppprovisionering, SCCM-patchdriftsättning, CI/CD-pipelineorkestrering. De första tio eller tjugo arbetsflödena motiverar investeringen enkelt, och ROI-kalkylen håller ända tills arbetsflödessantalet överstiger hundratalet och en meningsfull andel av IT-teamets vecka skiftar från att bygga ny automatisering till att hålla befintlig automatisering från att falla sönder.
En betalningsportal omdesignar sitt autentiseringsflöde och arbetsflödet för anspråksinlämning slutar autentisera. Salesforce pushar en metadatauppdatering och en fältmappning i lead-till-möjlighet-pipelinen börjar skriva nullvärden. AWS avvecklar en API-version och en Terraform-plan som körde felfritt i ett år börjar kasta 400-fel vid varje tillämpning. Någon skickar ett ärende, någon annan räknar ut vad som ändrades, patchar det, testar det, driftsätter korrigeringen — och under tiden kördes den process det automatiserade antingen manuellt eller inte alls.
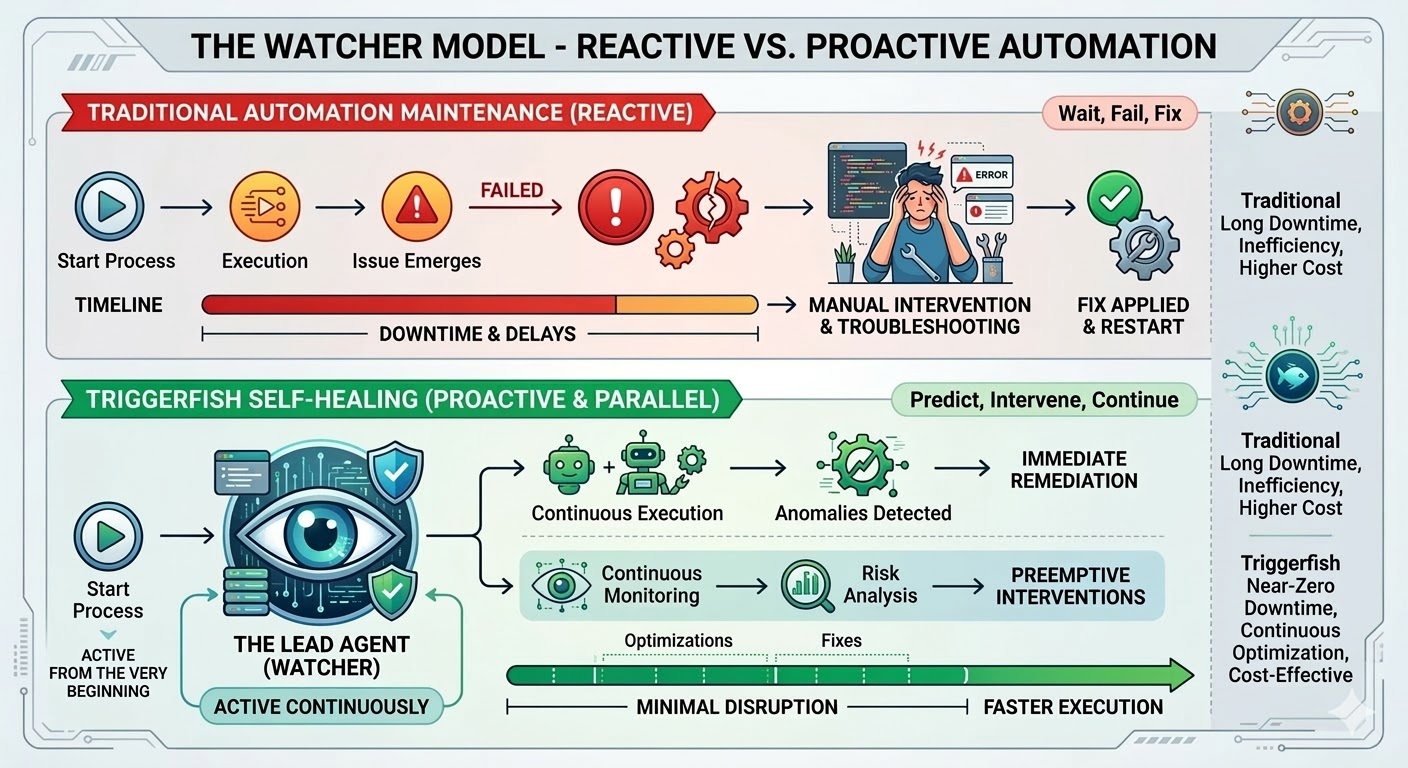
Det här är underhållsfällan, och den är strukturell snarare än ett implementeringsmisslyckande. Traditionell automatisering följer exakta vägar, matchar exakta mönster och går sönder i det ögonblick verkligheten avviker från vad som existerade när arbetsflödet skapades. Forskningen är konsekvent: organisationer spenderar 70 till 75 procent av sina totala automatiseringsprogramkostnader inte på att bygga nya arbetsflöden utan på att underhålla de de redan har. I stora driftsättningar går 45 procent av arbetsflödena sönder varje enskild vecka.
Triggerfishs arbetsflödesmotor byggdes för att förändra detta. Självläkande arbetsflöden lanseras idag, och de representerar den mest betydande kapabiliteten i plattformen hittills.
Vad självläkning faktiskt innebär
Frasen används löst, så låt mig vara direkt om vad det här är.
När du aktiverar självläkning på ett Triggerfish-arbetsflöde startas en leadagent i det ögonblick arbetsflödet börjar köra. Den startar inte när något går sönder; den bevakar från det första steget och tar emot en live-händelseström från motorn när arbetsflödet fortskrider och observerar varje steg i realtid.
Leadagenten känner till den fullständiga arbetsflödesdefinitionen innan ett enda steg körs, inklusive avsikten bakom varje steg, vad varje steg förväntar sig från de föregående och vad det producerar för de efterföljande. Den känner också till historiken från tidigare körningar: vad som lyckades, vad som misslyckades, vilka patchar som föreslogs och om en människa godkände eller avvisade dem. När den identifierar något värt att agera på finns redan all den kontexten i minnet eftersom den bevakade hela tiden snarare än rekonstruerade i efterhand.
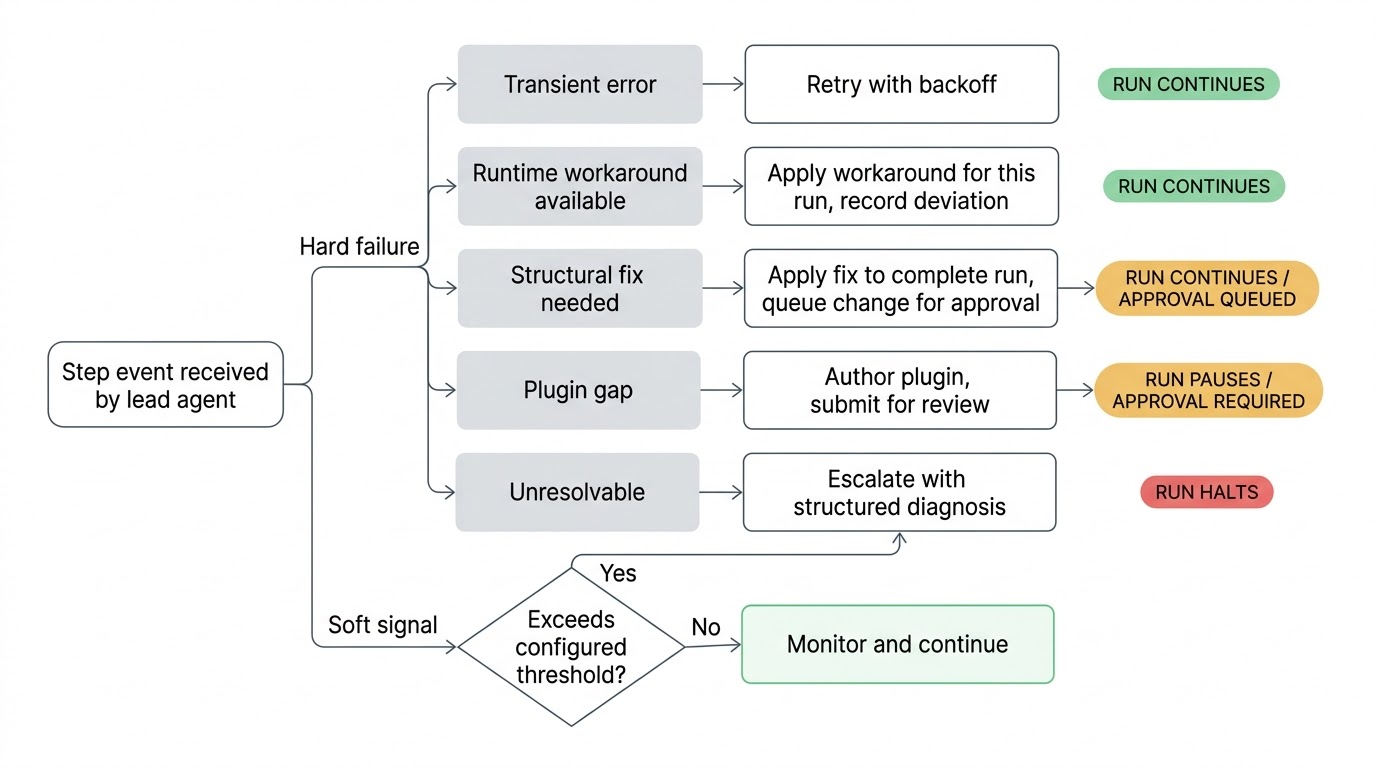
När något går fel triagerar leadagenten det. Ett instabilt nätverksanrop får ett nytt försök med backoff. En ändrad API-endpoint som kan arbetas runt arbetas runt för den här körningen. Ett strukturellt problem i arbetsflödesdefinitionen får en föreslagen korrigering tillämpad för att slutföra körningen, med förändringen inlämnad för ditt godkännande innan den blir permanent. En trasig pluginintegration får ett nytt eller uppdaterat plugin skapat och inlämnat för granskning. Om leadagenten uttömmer sina försök och inte kan lösa problemet eskalerar den till dig med en strukturerad diagnos av vad den försökte och vad den tror är grundorsaken.
Arbetsflödet fortsätter att köra när det säkert kan. Om ett steg är blockerat pausas bara de nedströms steg som är beroende av det medan parallella grenar fortsätter. Leadagenten känner till beroendegrafen och pausar bara det som faktiskt är blockerat.
Varför kontexten du bygger in i arbetsflöden spelar roll
Det som gör att självläkning fungerar i praktiken är att Triggerfish-arbetsflöden kräver rika stegmetadata från det ögonblick du skriver dem. Det är inte valfritt och det är inte dokumentation för sin egen skull; det är vad leadagenten resonerar utifrån.
Varje steg i ett arbetsflöde har fyra obligatoriska fält utöver uppgiftsdefinitionen: en beskrivning av vad steget gör mekaniskt, ett avsiktspåstående som förklarar varför det här steget finns och vilket affärssyfte det tjänar, ett expects-fält som beskriver vilka data det antar att det tar emot och vilket tillstånd tidigare steg måste befinna sig i, och ett produces-fält som beskriver vad det skriver till kontext för nedströms steg att konsumera.
Så här ser det ut i praktiken. Säg att du automatiserar provisionering av medarbetaråtkomst. En nyanställd börjar måndag och arbetsflödet behöver skapa konton i Active Directory, provisionera deras GitHub-organisationsmedlemskap, tilldela deras Okta-grupper och öppna ett Jira-ärende som bekräftar slutförande. Ett steg hämtar medarbetarposten från ditt HR-system. Dess intent-fält säger inte bara "hämta medarbetarposten." Det lyder: "Det här steget är sanningskällan för varje nedströms provisioneringsbeslut. Roll, avdelning och startdatum från den här posten avgör vilka AD-grupper som tilldelas, vilka GitHub-team som provisioneras och vilka Okta-policyer som tillämpas. Om det här steget returnerar inaktuella eller ofullständiga data kommer varje nedströms steg att provisionera fel åtkomst."

Leadagenten läser det avsiktspåståendet när steget misslyckas och förstår vad som står på spel. Den vet att en partiell post innebär att åtkomstetableringsstegen körs med felaktiga indata och potentiellt beviljar fel behörigheter till en riktig person som börjar om två dagar. Den kontexten formar hur den försöker återhämta sig, om den pausar nedströms steg och vad den berättar för dig om den eskalerar.
Ett annat steg i samma arbetsflöde kontrollerar produces-fältet för HR-hämtningssteget och vet att det förväntar sig .employee.role och .employee.department som icke-tomma strängar. Om ditt HR-system uppdaterar sitt API och börjar returnera de fälten kapslade under .employee.profile.role istället, identifierar leadagenten schemadriften, tillämpar en körtidsmappning för den här körningen så att den nyanställde provisioneras korrekt, och föreslår en strukturell korrigering för att uppdatera stegdefinitionen. Du skrev inte en schemamigreringsregel eller undantagshantering för det här specifika fallet. Leadagenten resonerade fram det från kontexten som redan var där.
Det här är varför kvaliteten på arbetsflödesförfattande spelar roll. Metadatan är inte ceremoni; det är bränslet som självläkningssystemet körs på. Ett arbetsflöde med ytliga stegbeskrivningar är ett arbetsflöde som leadagenten inte kan resonera om när det räknas.
Att bevaka live innebär att fånga problem innan de blir fel
Eftersom leadagenten bevakar i realtid kan den agera på svaga signaler innan saker faktiskt går sönder. Ett steg som historiskt slutförs på två sekunder tar nu fyrtio. Ett steg som returnerade data i varje tidigare körning returnerar ett tomt resultat. En villkorlig gren tas som aldrig tagits i den fullständiga körningshistoriken. Inget av detta är hårda fel och arbetsflödet fortsätter köra, men de är signaler på att något har förändrats i miljön. Det är bättre att fånga dem innan nästa steg försöker konsumera dåliga data.
Känsligheten hos dessa kontroller är konfigurerbar per arbetsflöde. En nattlig rapportgenerering kan ha lösa tröskelvärden medan en åtkomstprovisioneringsprocess bevakar noga. Du ställer in vilken nivå av avvikelse som förtjänar leadagentens uppmärksamhet.
Det är fortfarande ditt arbetsflöde
Leadagenten och dess team kan inte ändra din kanoniska arbetsflödesdefinition utan ditt godkännande. När leadagenten föreslår en strukturell korrigering tillämpar den korrigeringen för att slutföra den aktuella körningen och lämnar in förändringen som ett förslag. Du ser det i din kö, du ser resonemanget, du godkänner eller avvisar det. Om du avvisar det registreras det avvisandet och varje framtida leadagent som arbetar med det arbetsflödet vet att inte föreslå samma sak igen.
Det finns en sak som leadagenten aldrig kan ändra oavsett konfiguration: sitt eget mandat. Självläkningspolicyn i arbetsflödesdefinitionen — om den ska pausa, hur länge den ska försöka igen, om den kräver godkännande — är ägarbeskriven policy. Leadagenten kan patcha uppgiftsdefinitioner, uppdatera API-anrop, justera parametrar och skapa nya plugins. Den kan inte ändra reglerna som styr sitt eget beteende. Den gränsen är hårdkodad. En agent som kunde inaktivera godkännandekravet som styr sina egna förslag skulle göra hela förtroendemodellen meningslös.
Pluginförändringar följer samma godkännandeväg som alla plugins skapade av en agent i Triggerfish. Det faktum att pluginet skapades för att korrigera ett trasigt arbetsflöde ger det inget speciellt förtroende. Det går igenom samma granskning som om du hade bett en agent att bygga en ny integration från grunden.
Att hantera detta på varje kanal du redan använder
Du borde inte behöva logga in på en separat instrumentpanel för att veta vad dina arbetsflöden gör. Självläkningsnotifieringar kommer via varhelst du har konfigurerat Triggerfish att nå dig: en interventionssammanfattning på Slack, en godkännandeförfrågan på Telegram, en eskaleringsrapport via e-post. Systemet kommer till dig på kanalen som är lämplig för brådskan utan att du behöver uppdatera en övervakningskonsol.
Arbetsflödets statusmodell är byggd för detta. Status är inte en platt sträng utan ett strukturerat objekt som bär allt en notifiering behöver för att vara meningsfull: det nuvarande tillståndet, hälsosignalen, om en patch finns i din godkännandekö, resultatet av den senaste körningen och vad leadagenten gör för närvarande. Ditt Slack-meddelande kan säga "åtkomstprovisioneringsarbetsflödet är pausat, leadagenten skapar en plugin-korrigering, godkännande krävs" i en enda notifiering utan att du behöver leta efter kontext.
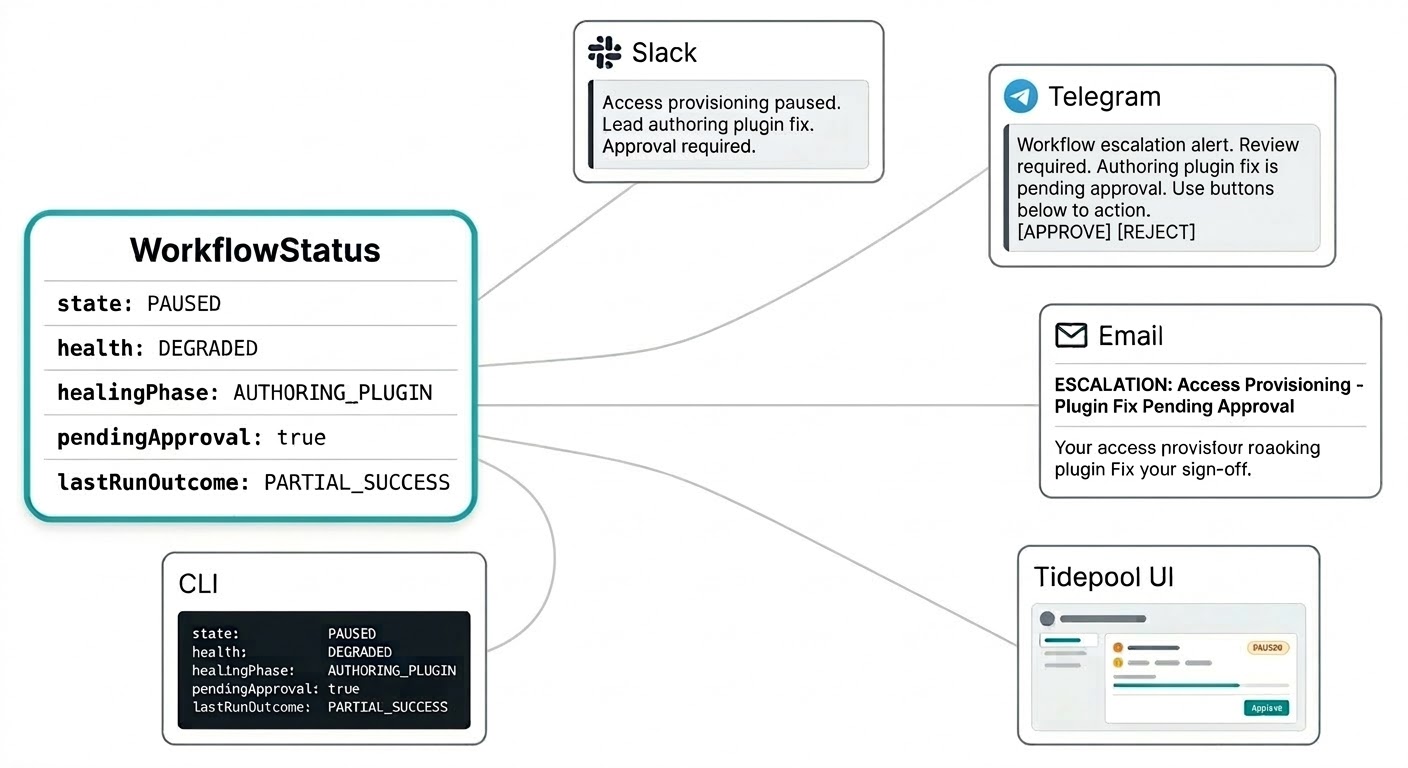
Samma strukturerade status matar det levande Tidepool-gränssnittet när du vill ha hela bilden. Samma data, annan yta.
Vad det faktiskt förändrar för IT-team
Personerna i din organisation som spenderar sin vecka med att korrigera trasiga arbetsflöden gör inte lågkvalificerat arbete. De felsöker distribuerade system, läser API-ändringsloggar och reverse-engineers varför ett arbetsflöde som fungerade bra igår misslyckas idag. Det är värdefull bedömningsförmåga, och just nu konsumeras den nästan uteslutande av att hålla befintlig automatisering vid liv snarare än att bygga ny automatisering eller lösa svårare problem.
Självläkande arbetsflöden eliminerar inte den bedömningsförmågan, men de förskjuter när den tillämpas. Istället för att bekämpa ett trasigt arbetsflöde mitt i natten granskar du en föreslagen korrigering på morgonen och beslutar om leadagentens diagnos är rätt. Du är godkännaren av en föreslagen förändring, inte skaparen av en patch under press.
Det är arbetsmodellen Triggerfish är byggd kring: människor som granskar och godkänner agentarbete snarare än att utföra det arbete som agenter kan hantera. Automatiseringstäckningen ökar medan underhållsbördan minskar, och teamet som spenderade 75 procent av sin tid på underhåll kan rikta om större delen av den tiden mot saker som faktiskt kräver mänsklig bedömning.
Lanseras idag
Självläkande arbetsflöden lanseras idag som en valfri funktion i Triggerfishs arbetsflödesmotor. Det är opt-in per arbetsflöde, konfigurerat i arbetsflödets metadatablock. Om du inte aktiverar det ändras ingenting i hur dina arbetsflöden körs.
Det här spelar roll inte för att det är ett svårt tekniskt problem (fastän det är det), utan för att det direkt adresserar det som har gjort företagsautomatisering dyrare och mer smärtsam än det behöver vara. Arbetsflödesunderhållsteamet borde vara det första jobbet som AI-automatisering tar över. Det är rätt användning av den här tekniken, och det är vad Triggerfish byggde.
Om du vill gräva djupare i hur det fungerar finns den fullständiga specifikationen i arkivet. Om du vill prova det, kommer färdigheten workflow-builder att guida dig genom att skriva ditt första självläkande arbetsflöde.