
ಪ್ರತಿ enterprise automation program ಒಂದೇ wall ಗೆ ಬಡಿಯುತ್ತದೆ. ServiceNow ticket routing, Terraform drift remediation, certificate rotation, AD group provisioning, SCCM patch deployment, CI/CD pipeline orchestration. ಮೊದಲ ಹತ್ತು ಅಥವಾ ಇಪ್ಪತ್ತು workflows ಹೂಡಿಕೆ ಸುಲಭವಾಗಿ justify ಮಾಡುತ್ತವೆ, ಮತ್ತು ROI math ಅಸ್ಸಾದಿ ನಿಂತಿರುತ್ತದೆ workflow count ಮುನ್ನೂರಿಗೆ cross ಮಾಡಿ IT team ನ ವಾರದ ಸ್ಮರಣೀಯ ಅಂಶ ಹೊಸ automation ನಿರ್ಮಿಸುವ ಬದಲು ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ automation ಬೀಳದಂತೆ ತಡೆಯಲು shift ಆಗುವ ತನಕ.
Payer portal auth flow redesign ಮಾಡಿ claims submission workflow authentication ನಿಲ್ಲಿಸುತ್ತದೆ. Salesforce metadata update push ಮಾಡಿ lead-to-opportunity pipeline ನಲ್ಲಿ field mapping nulls ಬರೆಯಲು ಪ್ರಾರಂಭಿಸುತ್ತದೆ. AWS API version deprecate ಮಾಡಿ ಒಂದು ವರ್ಷ clean ಚಲಿಸಿದ Terraform plan ಪ್ರತಿ apply ನಲ್ಲಿ 400s throw ಮಾಡಲು ಪ್ರಾರಂಭಿಸುತ್ತದೆ. ಯಾರಾದರೊಬ್ಬರು ticket file ಮಾಡುತ್ತಾರೆ, ಬೇರೆಯವರು ಏನು ಬದಲಾಯಿತು ಎಂದು ಕಂಡು ಹಿಡಿಯುತ್ತಾರೆ, patch ಮಾಡಿ, test ಮಾಡಿ, fix deploy ಮಾಡುತ್ತಾರೆ, ಮತ್ತು ಆ ಸಮಯದಲ್ಲಿ ಅದು automate ಮಾಡುತ್ತಿದ್ದ process manually ಚಲಿಸಿತು ಅಥವಾ ಚಲಿಸಲೇ ಇಲ್ಲ.
ಇದು maintenance trap, ಮತ್ತು ಇದು implementation ನ failure ಗಿಂತ ಹೆಚ್ಚಾಗಿ structural. Traditional automation exact paths follow ಮಾಡುತ್ತದೆ, exact patterns match ಮಾಡುತ್ತದೆ, ಮತ್ತು workflow author ಮಾಡಿದ ಸಮಯದಿಂದ reality deviate ಆದ ಕ್ಷಣ break ಮಾಡುತ್ತದೆ. Research consistent: organizations ತಮ್ಮ ಒಟ್ಟು automation program costs ನ 70 ರಿಂದ 75 percent ಹೊಸ workflows ನಿರ್ಮಿಸಲು ಅಲ್ಲ, ಈಗಾಗಲೇ ಇರುವವು maintain ಮಾಡಲು ಖರ್ಚು ಮಾಡುತ್ತವೆ. ದೊಡ್ಡ deployments ನಲ್ಲಿ, 45 percent workflows ಪ್ರತಿ ವಾರ break ಮಾಡುತ್ತವೆ.
Triggerfish ನ workflow engine ಇದನ್ನು ಬದಲಾಯಿಸಲು ನಿರ್ಮಿಸಲ್ಪಟ್ಟಿದೆ. Self-healing workflows ಇಂದು ship ಮಾಡುತ್ತವೆ, ಮತ್ತು ಅವು platform ನಲ್ಲಿ ಇದುವರೆಗಿನ ಅತ್ಯಂತ ಮಹತ್ವದ capability ಆಗಿವೆ.
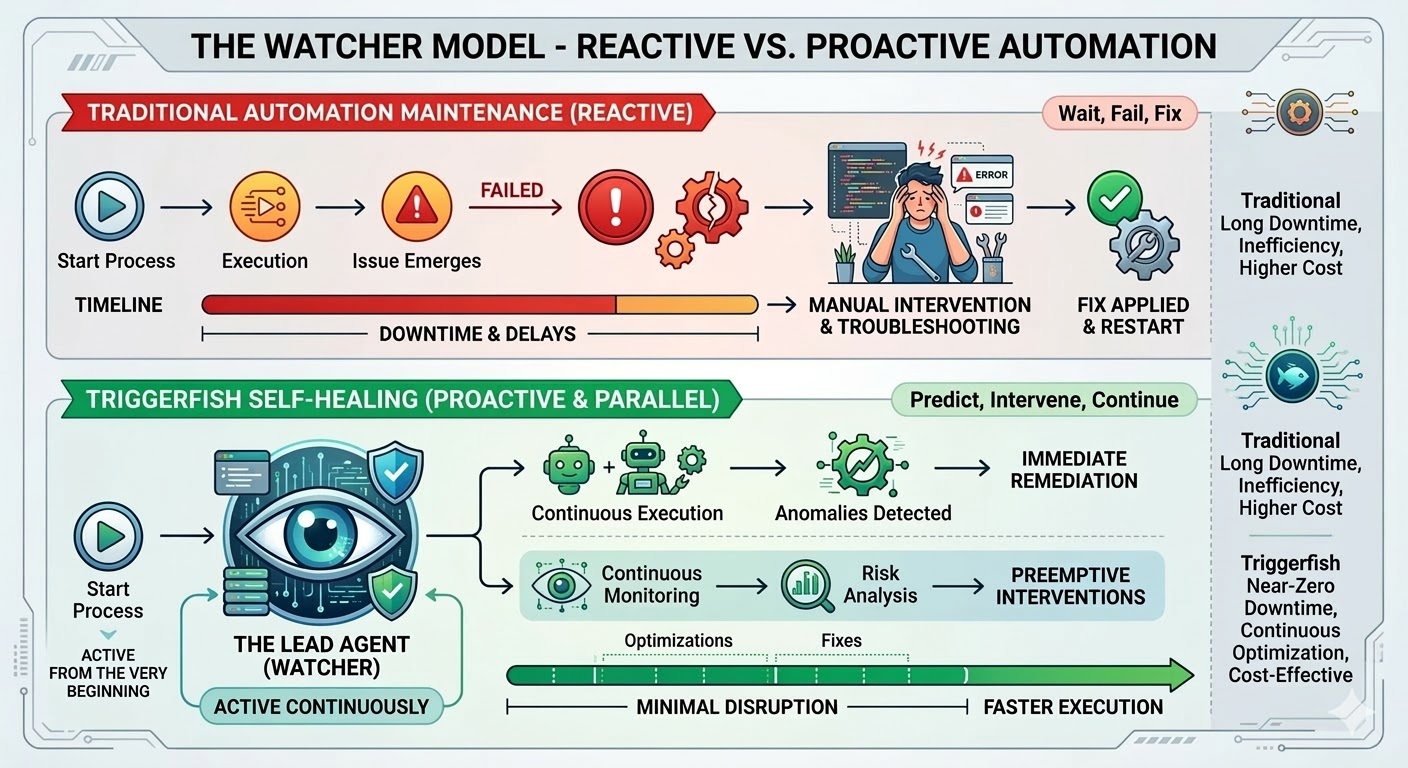
Self-Healing ನಿಜವಾಗಿ ಏನರ್ಥ
Phrase ಸಡಿಲವಾಗಿ ಬಳಸಲ್ಪಡುತ್ತದೆ, ಆದ್ದರಿಂದ ಇದು ಏನು ಎಂದು ನೇರವಾಗಿ ಹೇಳುತ್ತೇನೆ.
Triggerfish workflow ನಲ್ಲಿ self-healing enable ಮಾಡಿದಾಗ, ಆ workflow ಚಲಿಸಲು ಪ್ರಾರಂಭಿಸಿದ ಕ್ಷಣ lead agent spawn ಮಾಡಲ್ಪಡುತ್ತದೆ. ಏನಾದರೂ break ಮಾಡಿದಾಗ ಅಲ್ಲ; ಇದು ಮೊದಲ step ನಿಂದ watch ಮಾಡುತ್ತಿದೆ, workflow progresses ಆದಂತೆ engine ನಿಂದ live event stream ಸ್ವೀಕರಿಸಿ real time ನಲ್ಲಿ ಪ್ರತಿ step observe ಮಾಡುತ್ತದೆ.
Lead ಒಂದೇ step ಚಲಿಸುವ ಮೊದಲು ಸಂಪೂರ್ಣ workflow definition ತಿಳಿದಿದೆ, ಪ್ರತಿ step ರ intent, ಪ್ರತಿ step ಮೊದಲಿನವರಿಂದ ಏನನ್ನು expect ಮಾಡುತ್ತದೆ, ಮತ್ತು ನಂತರದವರಿಗೆ ಏನನ್ನು produce ಮಾಡುತ್ತದೆ ಸೇರಿದಂತೆ. ಏನಾದರೂ wrong ಹೋದಾಗ, lead triage ಮಾಡುತ್ತದೆ. Flaky network call retry ಮತ್ತು backoff ಪಡೆಯುತ್ತದೆ. Work around ಮಾಡಬಹುದಾದ changed API endpoint ಈ run ಗಾಗಿ worked around ಮಾಡಲ್ಪಡುತ್ತದೆ. Workflow definition ನಲ್ಲಿ structural problem run complete ಮಾಡಲು proposed fix ಪಡೆಯುತ್ತದೆ, permanent ಆಗುವ ಮೊದಲು ನಿಮ್ಮ approval ಗಾಗಿ submit ಮಾಡಿ.
Workflows ಗೆ ನೀವು Build ಮಾಡುವ Context ಏಕೆ ಮುಖ್ಯ
Self-healing ಪ್ರಾಯೋಗಿಕ ರೀತಿಯಲ್ಲಿ ಕೆಲಸ ಮಾಡಿಸುವ ವಿಷಯ ಏನೆಂದರೆ Triggerfish workflows ನೀವು ಅವನ್ನು ಬರೆದ ಕ್ಷಣದಿಂದ rich step-level metadata ಅಗತ್ಯ. ಇದು ಐಚ್ಛಿಕ ಅಲ್ಲ; ಇದು lead agent reason ಮಾಡುವ fuel.
Workflow ನ ಪ್ರತಿ step task definition ಮೀರಿ ನಾಲ್ಕು required fields ಹೊಂದಿದೆ: step mechanically ಏನು ಮಾಡುತ್ತದೆ ಎಂಬ description, step ಏಕೆ ಇದೆ ಮತ್ತು ಯಾವ business purpose serve ಮಾಡುತ್ತದೆ ಎಂಬ intent statement, ಸ್ವೀಕರಿಸುವ ಡೇಟಾ ಮತ್ತು ಮೊದಲಿನ steps ಯಾವ state ನಲ್ಲಿ ಇರಬೇಕು ಎಂದು describe ಮಾಡುವ expects field, ಮತ್ತು downstream steps consume ಮಾಡಲು context ಗೆ ಏನು ಬರೆಯುತ್ತದೆ ಎಂದು describe ಮಾಡುವ produces field.

Lead ಆ intent statement ಓದಿ step fail ಮಾಡಿದಾಗ ಏನು stake ನಲ್ಲಿದೆ ಎಂದು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುತ್ತದೆ. Partial record ಎಂದರೆ access provisioning steps ಕೆಟ್ಟ inputs ನೊಂದಿಗೆ ಚಲಿಸುತ್ತವೆ, ಎರಡು ದಿನಗಳಲ್ಲಿ ಪ್ರಾರಂಭಿಸುವ ನಿಜ ವ್ಯಕ್ತಿಗೆ ತಪ್ಪಾದ permissions grant ಮಾಡಬಹುದು ಎಂದು ತಿಳಿದಿದೆ. ಆ context recover ಮಾಡಲು ಹೇಗೆ ಪ್ರಯತ್ನಿಸುತ್ತದೆ, downstream steps pause ಮಾಡಬೇಕೇ ಎಂದು, ಮತ್ತು escalate ಮಾಡಿದ್ದರೆ ಏನು ಹೇಳಬೇಕೆಂದು shape ಮಾಡುತ್ತದೆ.
Live Watch ಮಾಡುವುದರಿಂದ Failures ಆಗುವ ಮೊದಲು Problems Catch ಮಾಡಲಾಗುತ್ತದೆ
Lead real time ನಲ್ಲಿ watch ಮಾಡುತ್ತಿರುವ ಕಾರಣ, ವಸ್ತುಗಳು ನಿಜವಾಗಿ break ಆಗುವ ಮೊದಲು soft signals ಮೇಲೆ act ಮಾಡಬಹುದು. ಐತಿಹಾಸಿಕವಾಗಿ ಎರಡು ಸೆಕೆಂಡ್ ನಲ್ಲಿ complete ಮಾಡುವ step ಈಗ ನಲ್ವತ್ತು ತೆಗೆದುಕೊಳ್ಳುತ್ತಿದೆ. ಪ್ರತಿ prior run ನಲ್ಲಿ ಡೇಟಾ return ಮಾಡಿದ step empty result return ಮಾಡಿದೆ. Conditional branch ತೆಗೆದುಕೊಳ್ಳಲ್ಪಟ್ಟಿದೆ ಅದು ಸಂಪೂರ್ಣ run history ನಲ್ಲಿ ಎಂದಿಗೂ ತೆಗೆದುಕೊಳ್ಳಲ್ಪಟ್ಟಿರಲಿಲ್ಲ. ಇವ್ಯಾವವೂ hard errors ಅಲ್ಲ ಮತ್ತು workflow ಚಲಿಸುತ್ತಲೇ ಇರುತ್ತದೆ, ಆದರೆ environment ನಲ್ಲಿ ಏನೋ ಬದಲಾಗಿದೆ ಎಂಬ signals. ಮುಂದಿನ step ಕೆಟ್ಟ ಡೇಟಾ consume ಮಾಡಲು ಪ್ರಯತ್ನಿಸುವ ಮೊದಲು catch ಮಾಡುವುದು ಉತ್ತಮ.
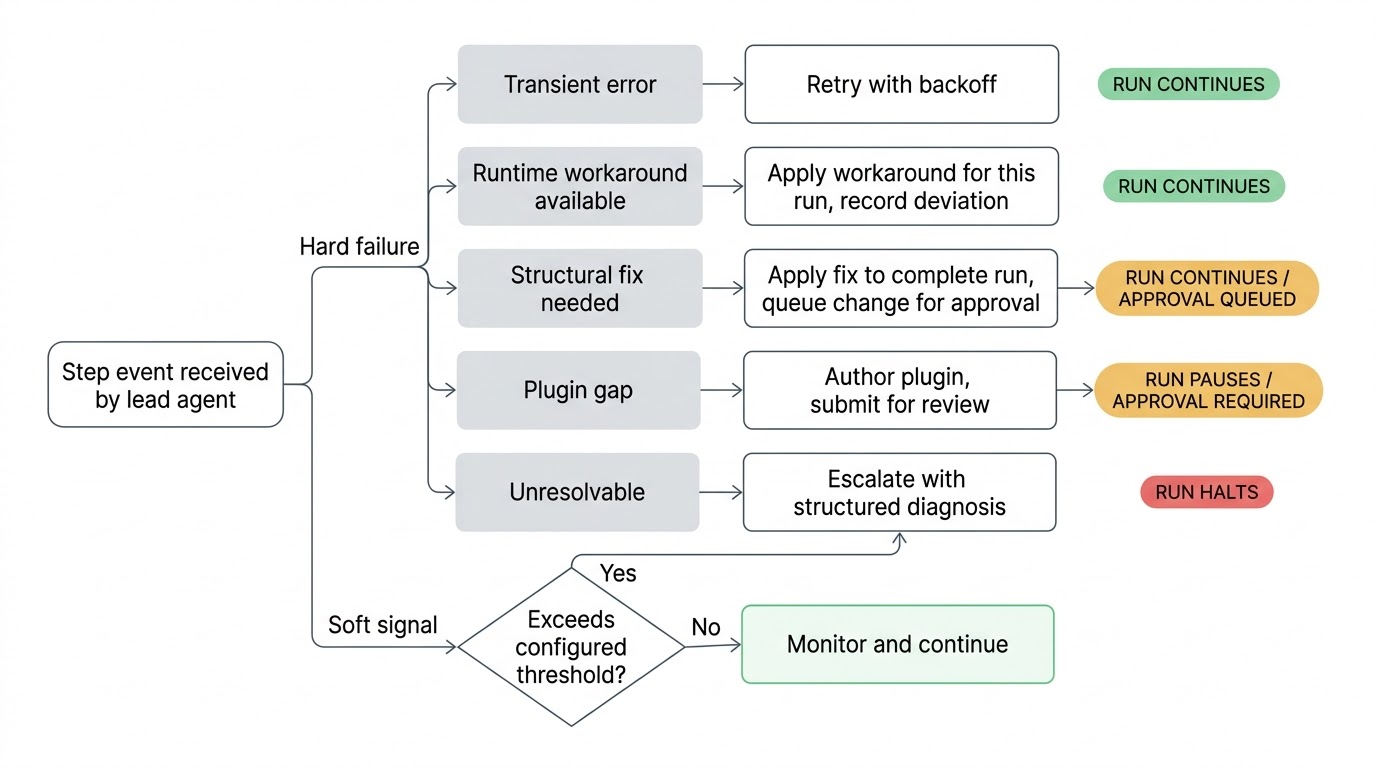
ಇದು ಇನ್ನೂ ನಿಮ್ಮ Workflow
Lead agent ಮತ್ತು ಅದರ team ನಿಮ್ಮ approval ಇಲ್ಲದೆ ನಿಮ್ಮ canonical workflow definition ಬದಲಾಯಿಸಲಾಗದು. Lead structural fix propose ಮಾಡಿದಾಗ, ಪ್ರಸ್ತುತ run complete ಮಾಡಲು fix apply ಮಾಡಿ change proposal ಆಗಿ submit ಮಾಡುತ್ತದೆ. ನೀವು ನಿಮ್ಮ queue ನಲ್ಲಿ ನೋಡುತ್ತೀರಿ, reasoning ನೋಡುತ್ತೀರಿ, approve ಅಥವಾ reject ಮಾಡುತ್ತೀರಿ. Reject ಮಾಡಿದರೆ, rejection ದಾಖಲಾಗುತ್ತದೆ ಮತ್ತು ಆ workflow ನಲ್ಲಿ ಕೆಲಸ ಮಾಡುವ ಪ್ರತಿ ಭಾವಿ lead ಅದೇ ವಿಷಯ propose ಮಾಡಬಾರದು ಎಂದು ತಿಳಿದಿರುತ್ತದೆ.
Lead configuration ಏನಾದರೂ ಸರಿ ಬದಲಾಯಿಸಲಾಗದ ಒಂದು ವಿಷಯ ಇದೆ: ಅದರ ಸ್ವಂತ mandate. Workflow definition ನಲ್ಲಿ self-healing policy -- pause ಮಾಡಬೇಕೇ, retry ಎಷ್ಟು ಸಮಯ, approval ಅಗತ್ಯವೇ -- owner-authored policy. Lead task definitions patch ಮಾಡಬಹುದು, API calls update ಮಾಡಬಹುದು, parameters adjust ಮಾಡಬಹುದು, ಮತ್ತು ಹೊಸ plugins author ಮಾಡಬಹುದು. ತನ್ನ ಸ್ವಂತ ನಡವಳಿಕೆ govern ಮಾಡುವ rules ಬದಲಾಯಿಸಲಾಗದು.
ನೀವು ಈಗಾಗಲೇ ಬಳಸುತ್ತಿರುವ ಪ್ರತಿ Channel ಅಡ್ಡಲಾಗಿ ನಿರ್ವಹಿಸುವುದು
Workflows ಏನು ಮಾಡುತ್ತಿವೆ ಎಂದು ತಿಳಿಯಲು ಪ್ರತ್ಯೇಕ dashboard ಗೆ login ಮಾಡಬೇಕಾಗಿಲ್ಲ. Self-healing notifications ನೀವು Triggerfish ತಲುಪಲು configure ಮಾಡಿದ ಎಲ್ಲೆಲ್ಲ ಬರುತ್ತವೆ: Slack ನಲ್ಲಿ intervention summary, Telegram ನಲ್ಲಿ approval request, email ನಲ್ಲಿ escalation report. Monitoring console refresh ಮಾಡದೆ urgency ಗೆ ಅರ್ಥ ಮಾಡಿಕೊಳ್ಳುವ channel ನಲ್ಲಿ system ನಿಮ್ಮ ಬಳಿ ಬರುತ್ತದೆ.
Workflow status model ಇದಕ್ಕಾಗಿ built. Status flat string ಅಲ್ಲ ಆದರೆ notification ಅರ್ಥಪೂರ್ಣ ಆಗಲು ಅಗತ್ಯ ಎಲ್ಲವನ್ನೂ ಒಯ್ಯುವ structured object: ಪ್ರಸ್ತುತ state, health signal, patch ನಿಮ್ಮ approval queue ನಲ್ಲಿ ಇದೆಯೇ, ಕೊನೆಯ run ನ outcome, ಮತ್ತು lead ಪ್ರಸ್ತುತ ಏನು ಮಾಡುತ್ತಿದೆ.
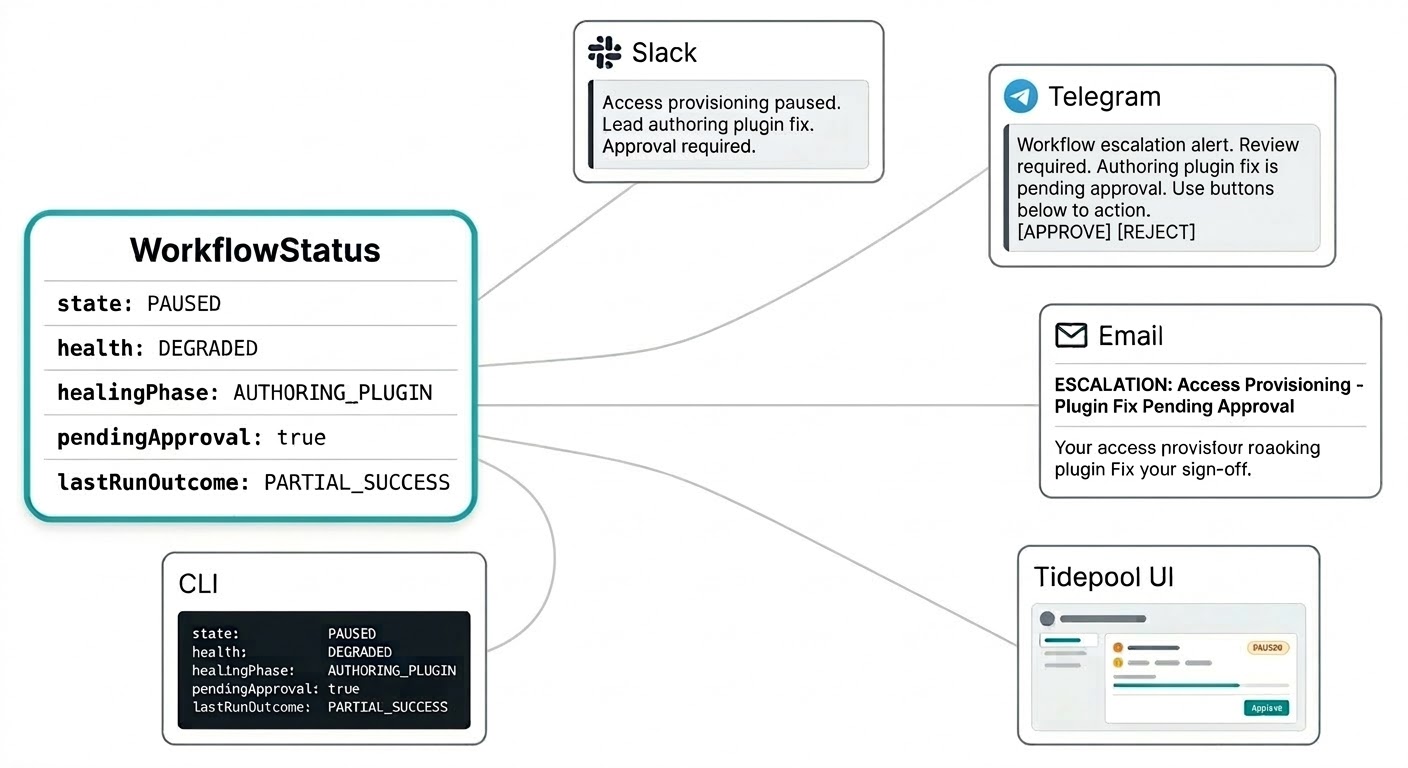
ಅದೇ structured status ನೀವು ಸಂಪೂರ್ಣ ಚಿತ್ರ ಬಯಸಿದಾಗ live Tidepool interface ಗೆ feed ಮಾಡುತ್ತದೆ. ಅದೇ data, ಭಿನ್ನ surface.
IT Teams ಗಾಗಿ ಇದು ನಿಜವಾಗಿ ಏನು ಬದಲಾಯಿಸುತ್ತದೆ
ನಿಮ್ಮ organization ನಲ್ಲಿ broken workflows fix ಮಾಡಲು ವಾರ ಖರ್ಚು ಮಾಡುವ ಜನರು low-skill ಕೆಲಸ ಮಾಡುತ್ತಿಲ್ಲ. ಅವರು distributed systems debug ಮಾಡುತ್ತಿದ್ದಾರೆ, API changelogs ಓದುತ್ತಿದ್ದಾರೆ, ಮತ್ತು ನಿನ್ನೆ ಚೆನ್ನಾಗಿ ಚಲಿಸಿದ workflow ಇಂದು ಏಕೆ fail ಮಾಡುತ್ತಿದೆ ಎಂದು reverse-engineer ಮಾಡುತ್ತಿದ್ದಾರೆ. ಇದು ಮೌಲ್ಯಯುತ judgment, ಮತ್ತು ಈಗ ಅದು ಹೆಚ್ಚಾಗಿ ಹೊಸ automation ನಿರ್ಮಿಸಲು ಅಥವಾ ಕಠಿಣ ಸಮಸ್ಯೆಗಳು ಪರಿಹರಿಸಲು ಅಲ್ಲ, ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ automation ಜೀವಂತ ಇಡಲು consume ಮಾಡಲ್ಪಡುತ್ತದೆ.
Self-healing workflows ಆ judgment ಅಳಿಸುವುದಿಲ್ಲ, ಆದರೆ ಅದನ್ನು apply ಮಾಡಿದಾಗ shift ಮಾಡುತ್ತದೆ. Midnight ನಲ್ಲಿ broken workflow firefight ಮಾಡುವ ಬದಲು, ಬೆಳಿಗ್ಗೆ proposed fix review ಮಾಡಿ lead ನ diagnosis ಸರಿ ಎಂದು ನಿರ್ಧರಿಸುತ್ತೀರಿ. ನೀವು proposed change ನ approver, pressure ನಲ್ಲಿ patch ನ author ಅಲ್ಲ.
ಇದು Triggerfish ನಿರ್ಮಿಸಲ್ಪಟ್ಟ labor model: agents ಮಾಡಬಲ್ಲ ಕೆಲಸ execute ಮಾಡುವ ಬದಲು humans agent ಕೆಲಸ review ಮತ್ತು approve ಮಾಡುತ್ತಾರೆ. ಮೇಲ್ವಿಚಾರಣೆ ಕಡಿಮೆಯಾಗುತ್ತಿರುವಾಗ automation coverage ಹೆಚ್ಚಾಗುತ್ತದೆ, ಮತ್ತು upkeep ನಲ್ಲಿ ತನ್ನ ಸಮಯದ 75 percent ಖರ್ಚು ಮಾಡುತ್ತಿದ್ದ team ಆ ಸಮಯದ ಹೆಚ್ಚಿನ ಭಾಗವನ್ನು human judgment ನಿಜವಾಗಿ ಅಗತ್ಯವಿರುವ ವಿಷಯಗಳಿಗೆ redirect ಮಾಡಬಹುದು.
ಇಂದು Ship ಆಗುತ್ತಿದೆ
Self-healing workflows Triggerfish workflow engine ನಲ್ಲಿ optional feature ಆಗಿ ಇಂದು ship ಮಾಡುತ್ತವೆ. ಇದು per-workflow opt-in, workflow metadata block ನಲ್ಲಿ configure ಮಾಡಲ್ಪಟ್ಟಿದೆ. Enable ಮಾಡದಿದ್ದರೆ, workflows ಹೇಗೆ ಚಲಿಸುತ್ತವೆ ಎಂಬುದರ ಬಗ್ಗೆ ಏನೂ ಬದಲಾಗುವುದಿಲ್ಲ.
ಇದು ಮುಖ್ಯ ಏಕೆಂದರೆ ಇದು ಕಠಿಣ technical problem (ಅಗಿದ್ದರೂ), ಆದರೆ ಏಕೆಂದರೆ ಇದು enterprise automation ಅಗತ್ಯಕ್ಕಿಂತ ಹೆಚ್ಚು ದುಬಾರಿ ಮತ್ತು ನೋವಿನ ಮಾಡಿದ ವಿಷಯವನ್ನು ನೇರವಾಗಿ address ಮಾಡುತ್ತದೆ. Workflow maintenance team AI automation ತೆಗೆದುಕೊಳ್ಳಬೇಕಾದ ಮೊದಲ ಕೆಲಸ. ಇದು ಈ technology ನ ಸರಿಯಾದ ಬಳಕೆ, ಮತ್ತು Triggerfish ನಿರ್ಮಿಸಿದ್ದು ಅದೇ.
ಇದು ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ ಎಂದು ತಿಳಿಯಲು ಬಯಸಿದರೆ, ಸಂಪೂರ್ಣ spec repository ನಲ್ಲಿ ಇದೆ. Try ಮಾಡಲು ಬಯಸಿದರೆ, workflow-builder skill ನಿಮ್ಮ ಮೊದಲ self-healing workflow ಬರೆಯುವ ಮೂಲಕ ನಡೆಯುತ್ತದೆ.