
Elk enterprise-automatiseringsprogramma stuit op dezelfde muur. ServiceNow-ticketroutering, Terraform-drift-herstel, certificaatrotatie, AD-groepprovisioning, SCCM-patch-implementatie, CI/CD-pijplijnorkestratie. De eerste tien of twintig workflows rechtvaardigen de investering gemakkelijk, en de ROI-berekening klopt totdat het aantal workflows in de honderden loopt en een aanzienlijk deel van de week van het IT-team verschuift van het bouwen van nieuwe automatisering naar het in stand houden van bestaande automatisering.
Een betaalportaal herontwerpt zijn authenticatiestroom en de workflow voor het indienen van claims stopt met authenticeren. Salesforce pusht een metadata-update en een veldtoewijzing in de lead-naar-opportunity-pijplijn begint nullen te schrijven. AWS depreceert een API-versie en een Terraform-plan dat een jaar lang schoon liep begint 400-fouten te gooien bij elke toepassing. Iemand dient een ticket in, iemand anders zoekt uit wat er is veranderd, patcht het, test het, implementeert de fix, en ondertussen liep het proces dat werd geautomatiseerd handmatig of helemaal niet.
Dit is de onderhoudsval, en het is structureel in plaats van een implementatiefout. Traditionele automatisering volgt exacte paden, matcht exacte patronen en breekt het moment dat de werkelijkheid afwijkt van wat bestond toen de workflow werd gemaakt. Het onderzoek is consistent: organisaties besteden 70 tot 75 procent van hun totale automatiseringsprogrammakosten niet aan het bouwen van nieuwe workflows maar aan het onderhouden van bestaande. Bij grote implementaties breekt 45 procent van de workflows elke week.
De workflow-engine van Triggerfish is gebouwd om dit te veranderen. Zelfherstellende workflows worden vandaag geleverd en vertegenwoordigen de meest significante mogelijkheid in het platform tot nu toe.
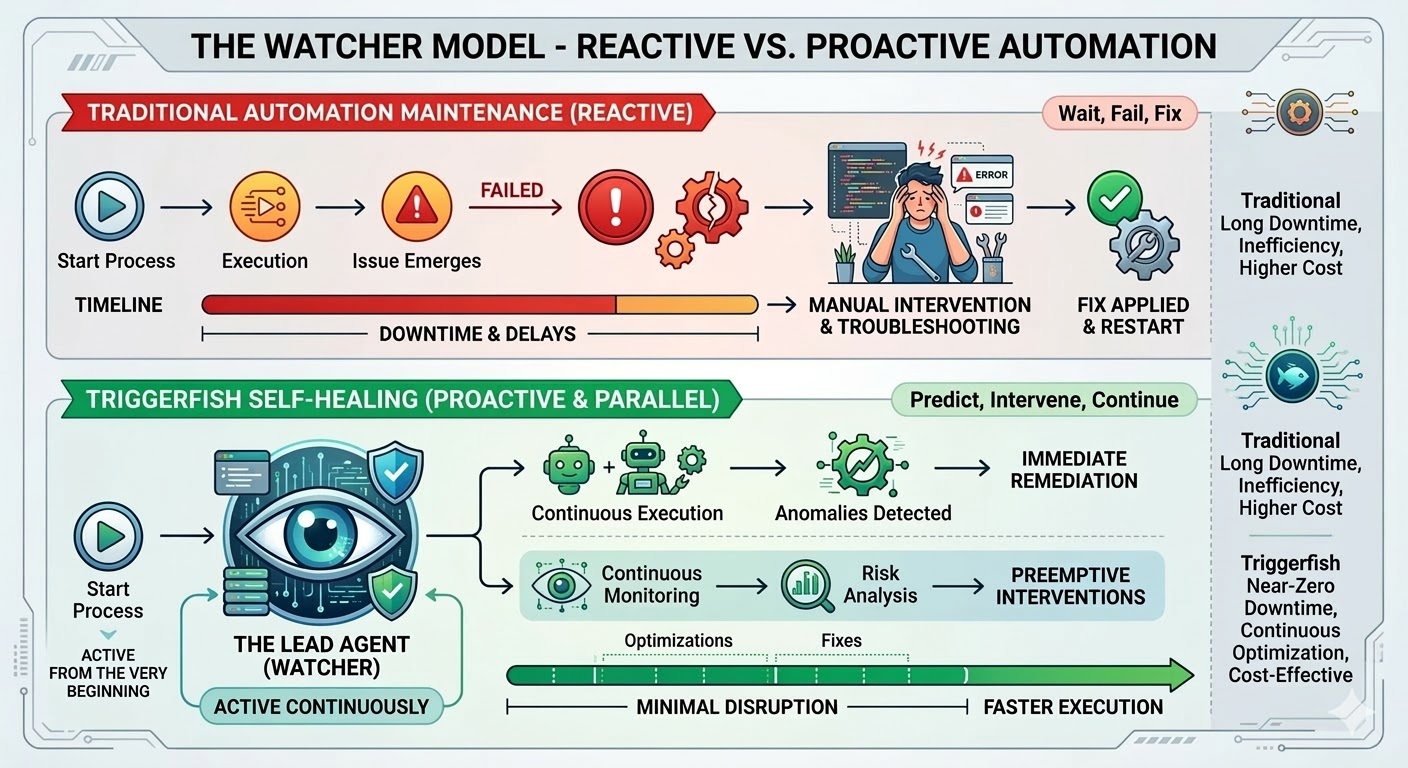
Wat Zelfherstellend Werkelijk Betekent
De term wordt losjes gebruikt, dus laat me direct zijn over wat dit is.
Wanneer u zelfherstel inschakelt op een Triggerfish-workflow, wordt een lead-agent gestart op het moment dat die workflow begint te draaien. Het start niet wanneer er iets kapot gaat; het kijkt vanaf de eerste stap, ontvangt een live evenementenstroom van de engine terwijl de workflow vordert en observeert elke stap in realtime.
De lead kent de volledige workflow-definitie voordat een enkele stap wordt uitgevoerd, inclusief de intentie achter elke stap, wat elke stap verwacht van de stappen ervoor en wat het produceert voor de stappen erna. Het kent ook de geschiedenis van eerdere runs: wat slaagde, wat faalde, welke patches werden voorgesteld en of een mens ze goedkeurde of afwees. Wanneer het iets identificeert dat de moeite waard is om op te handelen, is al die context al in het geheugen omdat het de hele tijd keek in plaats van achteraf te reconstrueren.
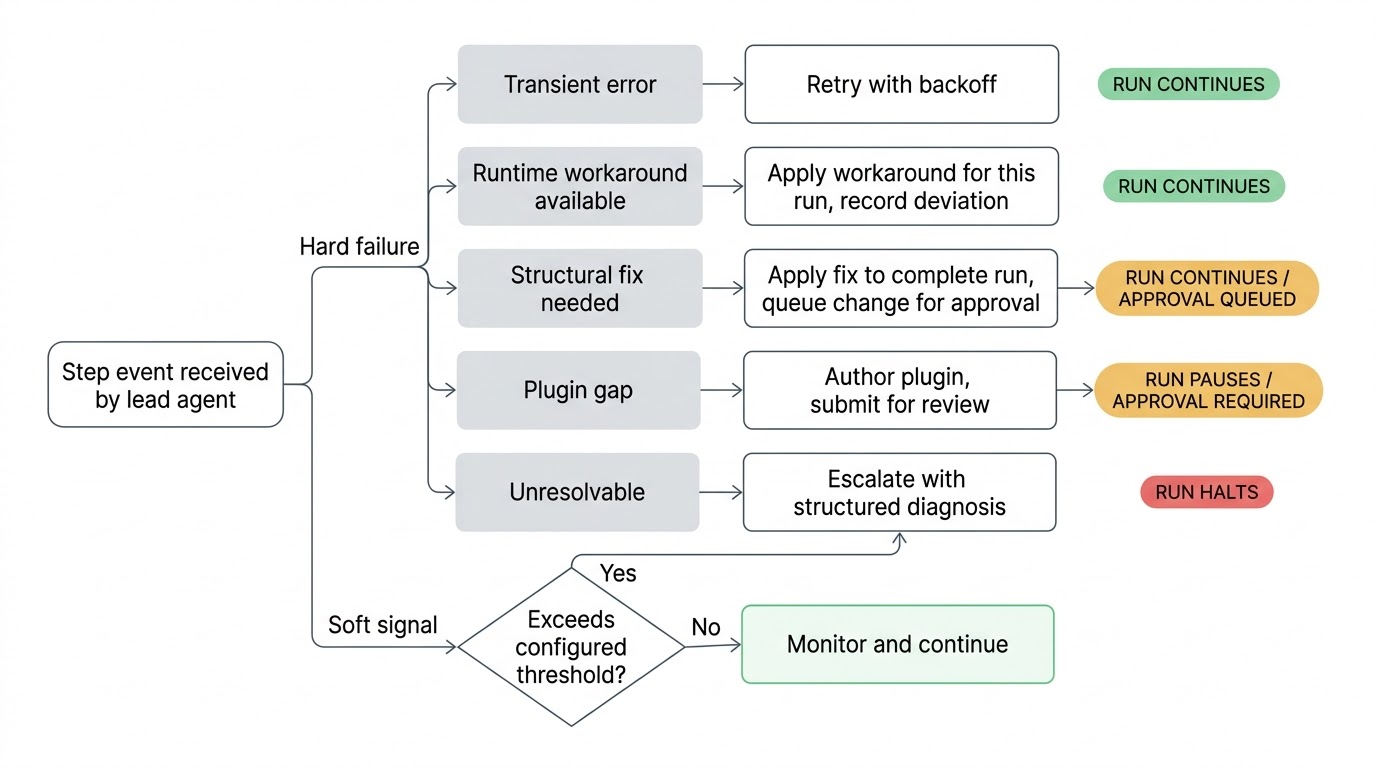
Wanneer er iets misgaat, triageert de lead het. Een wispelturige netwerkaanroep krijgt een nieuwe poging met backoff. Een gewijzigd API-eindpunt dat omzeild kan worden, wordt omzeild voor deze run. Een structureel probleem in de workflow-definitie krijgt een voorgestelde fix toegepast om de run te voltooien, waarbij de wijziging ter goedkeuring wordt ingediend voordat het permanent wordt. Een kapotte plugin-integratie krijgt een nieuwe of bijgewerkte plugin die wordt geschreven en ter beoordeling ingediend. Als de lead zijn pogingen uitput en het probleem niet kan oplossen, escaleert het naar u met een gestructureerde diagnose van wat het heeft geprobeerd en wat het denkt dat de hoofdoorzaak is.
De workflow blijft draaien wanneer dat veilig kan. Als een stap geblokkeerd is, pauseren alleen de downstream-stappen die ervan afhangen terwijl parallelle branches doorgaan. De lead kent de afhankelijkheidsgraph en pauzeert alleen wat daadwerkelijk geblokkeerd is.
Waarom de Context Die U in Workflows Bouwt Belangrijk Is
Wat zelfherstel in de praktijk laat werken is dat Triggerfish-workflows rijke stap-niveau-metadata vereisen vanaf het moment dat u ze schrijft. Dit is niet optioneel en het is geen documentatie voor zijn eigen bestwil; het is waar de lead-agent van redeneert.
Elke stap in een workflow heeft vier verplichte velden naast de taakdefinitie zelf: een beschrijving van wat de stap mechanisch doet, een intent-verklaring die uitlegt waarom deze stap bestaat en welk zakelijk doel het dient, een expects-veld dat beschrijft welke gegevens het aanneemt te ontvangen en in welke staat eerdere stappen moeten zijn, en een produces-veld dat beschrijft wat het naar context schrijft voor downstream-stappen om te consumeren.
Stel, u automatiseert de inrichting van medewerkerstoegang. Een nieuwe medewerker begint maandag en de workflow moet accounts aanmaken in Active Directory, hun GitHub-org-lidmaatschap inrichten, hun Okta-groepen toewijzen en een Jira-ticket openen ter bevestiging. Een stap haalt het medewerkerrecord op uit uw HR-systeem. Het intent-veld zegt niet alleen "haal het medewerkerrecord op." Het leest: "Deze stap is de bron van waarheid voor elke downstream inrichtingsbeslissing. Rol, afdeling en startdatum uit dit record bepalen welke AD-groepen worden toegewezen, welke GitHub-teams worden ingericht en welke Okta-beleidsregels van toepassing zijn. Als deze stap verouderde of onvolledige gegevens retourneert, zullen alle downstream-stappen de verkeerde toegang inrichten."

De lead leest die intent-verklaring wanneer de stap faalt en begrijpt wat er op het spel staat. Het weet dat een gedeeltelijk record betekent dat de toegangsinrichtingsstappen draaien met slechte invoeren, wat mogelijk verkeerde rechten verleent aan een echte persoon die over twee dagen begint. Die context bepaalt hoe het probeert te herstellen, of het downstream-stappen pauzeert en wat het u vertelt als het escaleert.
Een andere stap in dezelfde workflow controleert het produces-veld van de HR-ophaalstap en weet dat het .employee.role en .employee.department als niet-lege strings verwacht. Als uw HR-systeem zijn API bijwerkt en die velden genest begint te retourneren onder .employee.profile.role, detecteert de lead de schemadrift, past een runtime-mapping toe voor deze run zodat de nieuwe medewerker correct wordt ingericht, en stelt een structurele fix voor om de stapbeschrijving bij te werken. U schreef geen schemamigreeregel of uitzonderingsafhandeling voor dit specifieke geval. De lead redeneerde ernaar toe vanuit de context die er al was.
Dit is waarom de kwaliteit van workflow-ontwerp belangrijk is. De metadata is geen ceremonie; het is de brandstof waarop het zelfherstellend systeem draait. Een workflow met ondiepe stapbeschrijvingen is een workflow waarover de lead niet kan redeneren wanneer het erop aankomt.
Live Kijken Betekent Problemen Opvangen Voordat Ze Fouten Worden
Omdat de lead in realtime kijkt, kan het handelen op zachte signalen voordat de zaken daadwerkelijk kapot gaan. Een stap die historisch in twee seconden voltooit, duurt nu veertig seconden. Een stap die bij elke eerdere run gegevens retourneerde, retourneert een leeg resultaat. Een conditionele tak wordt genomen die nooit eerder in de volledige rungeschiedenis is genomen. Geen van deze zijn harde fouten en de workflow blijft draaien, maar het zijn signalen dat er iets in de omgeving is veranderd. Het is beter om ze op te vangen voordat de volgende stap probeert slechte gegevens te consumeren.
De gevoeligheid van deze controles is configureerbaar per workflow. Een nachtelijke rapportgeneratie kan losse drempels hebben terwijl een toegangsinrichtingspijplijn nauwlettend kijkt. U stelt in welk niveau van afwijking de aandacht van de lead waard is.
Het Blijft Uw Workflow
De lead-agent en zijn team kunnen uw canonieke workflow-definitie niet wijzigen zonder uw goedkeuring. Wanneer de lead een structurele fix voorstelt, past het de fix toe om de huidige run te voltooien en dient de wijziging in als een voorstel. U ziet het in uw wachtrij, u ziet de redenering, u keurt het goed of wijst het af. Als u het afwijst, wordt die afwijzing vastgelegd en weet elke toekomstige lead die aan die workflow werkt dezelfde zaak niet opnieuw voor te stellen.
Er is één ding dat de lead nooit kan veranderen, ongeacht de configuratie: zijn eigen mandaat. Het zelfherstellingsbeleid in de workflow-definitie, of het moet pauseren, hoe lang het opnieuw moet proberen, of goedkeuring vereist is, is door de eigenaar geschreven beleid. De lead kan taakdefinities patchen, API-aanroepen bijwerken, parameters aanpassen en nieuwe plugins schrijven. Het kan de regels die zijn eigen gedrag beheren niet wijzigen. Die grens is hardgecodeerd.
Plugin-wijzigingen volgen hetzelfde goedkeuringspad als elke plugin die door een agent in Triggerfish is geschreven. Het feit dat de plugin is geschreven om een kapotte workflow te repareren, geeft het geen speciaal vertrouwen. Het gaat door dezelfde beoordeling alsof u een agent had gevraagd een nieuwe integratie voor u te bouwen.
Dit Beheren Via Elk Kanaal Dat U Al Gebruikt
U zou zich niet hoeven aan te melden bij een apart dashboard om te weten wat uw workflows doen. Zelfherstellende meldingen komen door via waar u Triggerfish hebt geconfigureerd om u te bereiken: een interventiesamenvatting op Slack, een goedkeuringsverzoek op Telegram, een escalatierapport per e-mail. Het systeem komt naar u toe via het kanaal dat zinvol is voor de urgentie, zonder dat u een bewakingsconsole hoeft te vernieuwen.
Het workflow-statusmodel is hiervoor gebouwd. Status is geen platte string maar een gestructureerd object dat alles bevat wat een melding nodig heeft om betekenisvol te zijn: de huidige toestand, het gezondheidssignaal, of een patch in uw goedkeuringswachtrij staat, de uitkomst van de laatste run en wat de lead momenteel doet. Uw Slack-bericht kan zeggen "de toegangsinrichtingworkflow is gepauzeerd, de lead schrijft een plugin-fix, goedkeuring is vereist" in één melding zonder zoeken naar context.
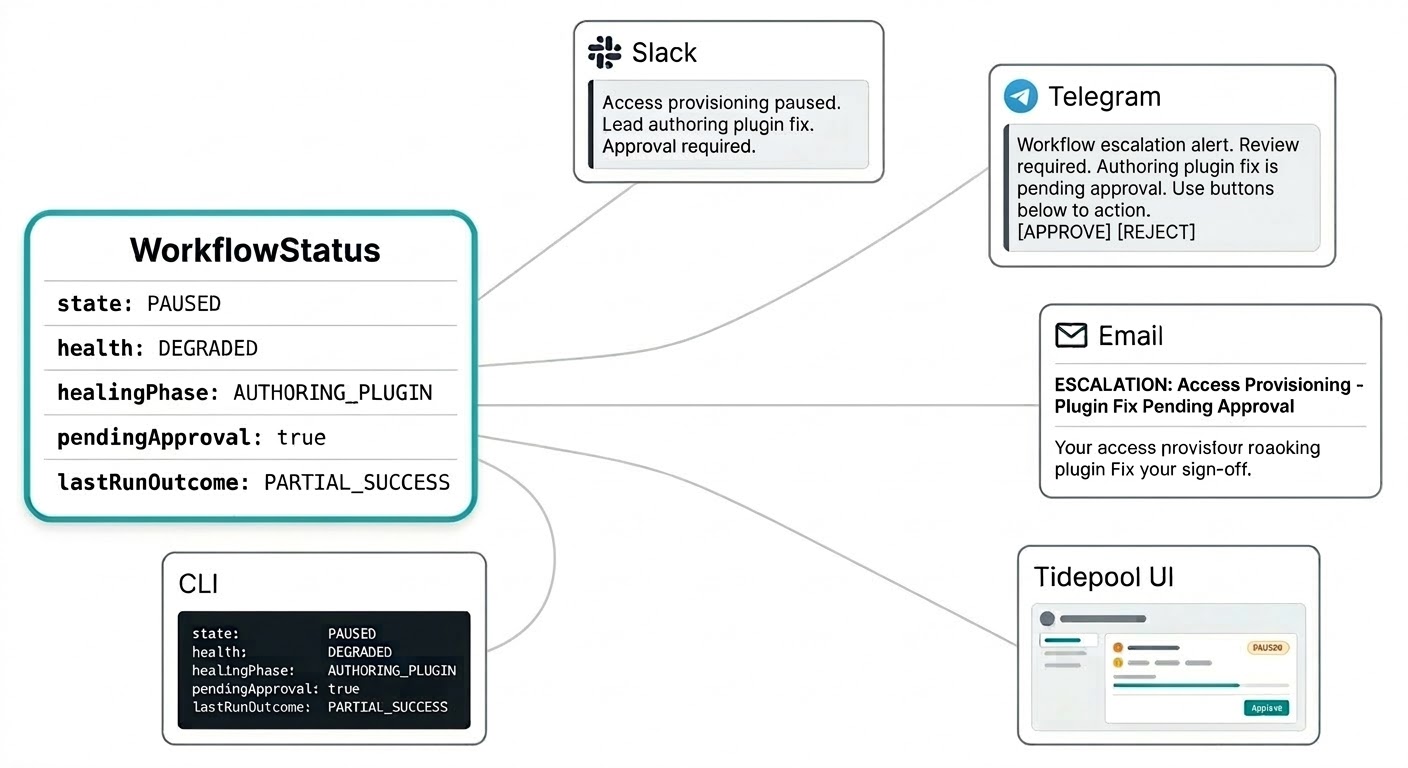
Diezelfde gestructureerde status voedt de live Tidepool-interface wanneer u het volledige beeld wilt. Dezelfde gegevens, ander oppervlak.
Wat Dit Werkelijk Verandert voor IT-teams
De mensen in uw organisatie die hun week besteden aan het repareren van kapotte workflows doen geen laagvaardig werk. Ze debuggen gedistribueerde systemen, lezen API-changelogs en reverse-engineeren waarom een workflow die gisteren prima liep vandaag faalt. Dat is waardevolle oordeelsvorming, en op dit moment wordt het bijna volledig verbruikt door bestaande automatisering in stand te houden in plaats van nieuwe automatisering te bouwen of moeilijkere problemen op te lossen.
Zelfherstellende workflows elimineren dat oordeel niet, maar ze verschuiven wanneer het wordt toegepast. In plaats van 's nachts een kapotte workflow te blussen, beoordeelt u 's ochtends een voorgestelde fix en beslist u of de diagnose van de lead klopt. U bent de goedkeurder van een voorgestelde wijziging, niet de auteur van een patch onder druk.
Dat is het arbeidsmodel waaromheen Triggerfish is gebouwd: mensen die agentwerk beoordelen en goedkeuren in plaats van het werk uitvoeren dat agenten aankunnen. De automatiseringsdekking gaat omhoog terwijl de onderhoudsdruk daalt, en het team dat 75 procent van zijn tijd besteedde aan onderhoud kan het grootste deel van die tijd omsturen naar dingen die daadwerkelijk menselijk oordeel vereisen.
Vandaag Geleverd
Zelfherstellende workflows worden vandaag geleverd als een optionele functie in de Triggerfish-workflow-engine. Het is opt-in per workflow, geconfigureerd in het workflow-metadatablok. Als u het niet inschakelt, verandert er niets aan hoe uw workflows draaien.
Dit is van belang niet omdat het een moeilijk technisch probleem is (hoewel dat zo is), maar omdat het direct het probleem aanpakt dat enterprise-automatisering duurder en pijnlijker heeft gemaakt dan nodig is. Het workflow-onderhoudsteam zou de eerste baan moeten zijn die AI-automatisering overneemt. Dat is het juiste gebruik van deze technologie, en dat is wat Triggerfish heeft gebouwd.
Als u wilt begrijpen hoe het werkt, is de volledige specificatie in de repository. Als u het wilt proberen, begeleidt de workflow-builder-skill u bij het schrijven van uw eerste zelfherstellende workflow.