
Jedes Automatisierungsprogramm in Unternehmen stößt an dieselbe Wand. ServiceNow-Ticket-Routing, Terraform-Drift-Behebung, Zertifikatsrotation, AD-Gruppenbereitstellung, SCCM-Patch-Deployment, CI/CD-Pipeline-Orchestrierung. Die ersten zehn oder zwanzig Workflows rechtfertigen die Investition leicht, und die ROI-Rechnung geht auf, genau so lange, bis die Zahl der Workflows in die Hunderte geht und ein erheblicher Teil der Woche des IT-Teams sich davon verschiebt, neue Automatisierung zu bauen, hin dazu, bestehende Automatisierung am Laufen zu halten.
Ein Zahlungsportal gestaltet seinen Auth-Flow um und der Workflow zur Schadensmeldung kann sich nicht mehr authentifizieren. Salesforce schiebt ein Metadaten-Update und ein Feld-Mapping in der Lead-to-Opportunity-Pipeline beginnt, Nullwerte zu schreiben. AWS depreciert eine API-Version und ein Terraform-Plan, der ein Jahr lang sauber durchlief, wirft bei jedem Apply 400er-Fehler. Jemand erstellt ein Ticket, jemand anderes findet heraus, was sich geändert hat, patcht es, testet es, deployt den Fix, und in der Zwischenzeit lief der Prozess, den der Workflow automatisieren sollte, entweder manuell oder gar nicht.
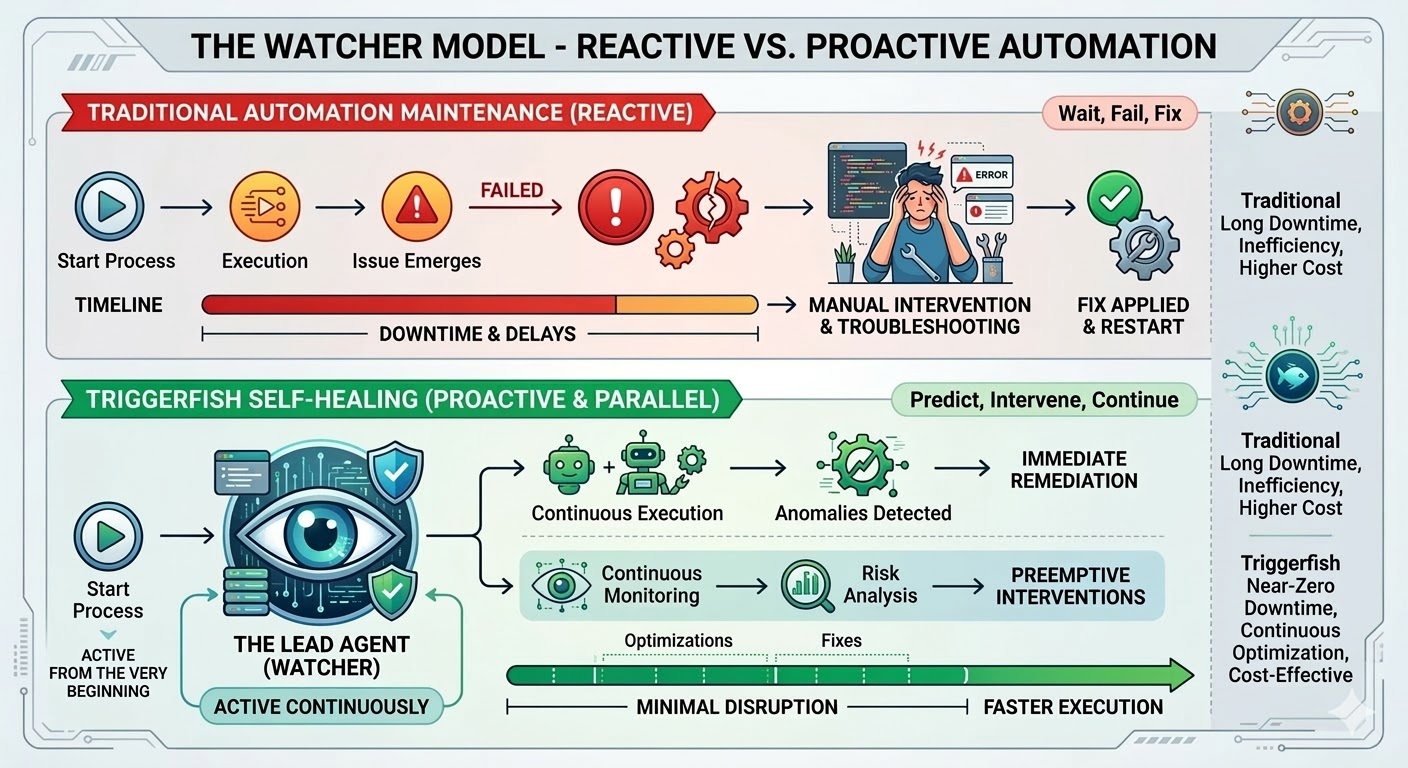
Das ist die Wartungsfalle, und sie ist strukturell bedingt, kein Implementierungsfehler. Traditionelle Automatisierung folgt exakten Pfaden, matcht exakte Muster und bricht in dem Moment, in dem die Realität von dem abweicht, was beim Erstellen des Workflows existierte. Die Forschungslage ist eindeutig: Organisationen geben 70 bis 75 Prozent ihrer gesamten Automatisierungsprogrammkosten nicht für den Bau neuer Workflows aus, sondern für die Wartung der bereits vorhandenen. In großen Deployments brechen 45 Prozent der Workflows jede einzelne Woche.
Die Workflow-Engine von Triggerfish wurde gebaut, um das zu ändern. Self-Healing Workflows werden ab heute ausgeliefert und stellen die bisher bedeutendste Fähigkeit der Plattform dar.
Was Self-Healing tatsächlich bedeutet
Der Begriff wird oft ungenau verwendet, daher möchte ich klar sagen, was damit gemeint ist.
Wenn Sie Self-Healing für einen Triggerfish-Workflow aktivieren, wird in dem Moment ein Lead-Agent gestartet, in dem der Workflow zu laufen beginnt. Er startet nicht erst, wenn etwas kaputt geht; er beobachtet ab dem ersten Schritt, empfängt einen Live-Event-Stream von der Engine, während der Workflow fortschreitet, und beobachtet jeden Schritt in Echtzeit.
Der Lead kennt die vollständige Workflow-Definition, bevor ein einziger Schritt ausgeführt wird, einschließlich der Absicht hinter jedem Schritt, was jeder Schritt von seinen Vorgängern erwartet und was er für die nachfolgenden produziert. Er kennt auch die Historie früherer Läufe: was erfolgreich war, was fehlschlug, welche Patches vorgeschlagen wurden und ob ein Mensch sie genehmigt oder abgelehnt hat. Wenn er etwas Handlungsrelevantes erkennt, ist der gesamte Kontext bereits im Speicher, weil er die ganze Zeit zugeschaut hat, anstatt im Nachhinein zu rekonstruieren.
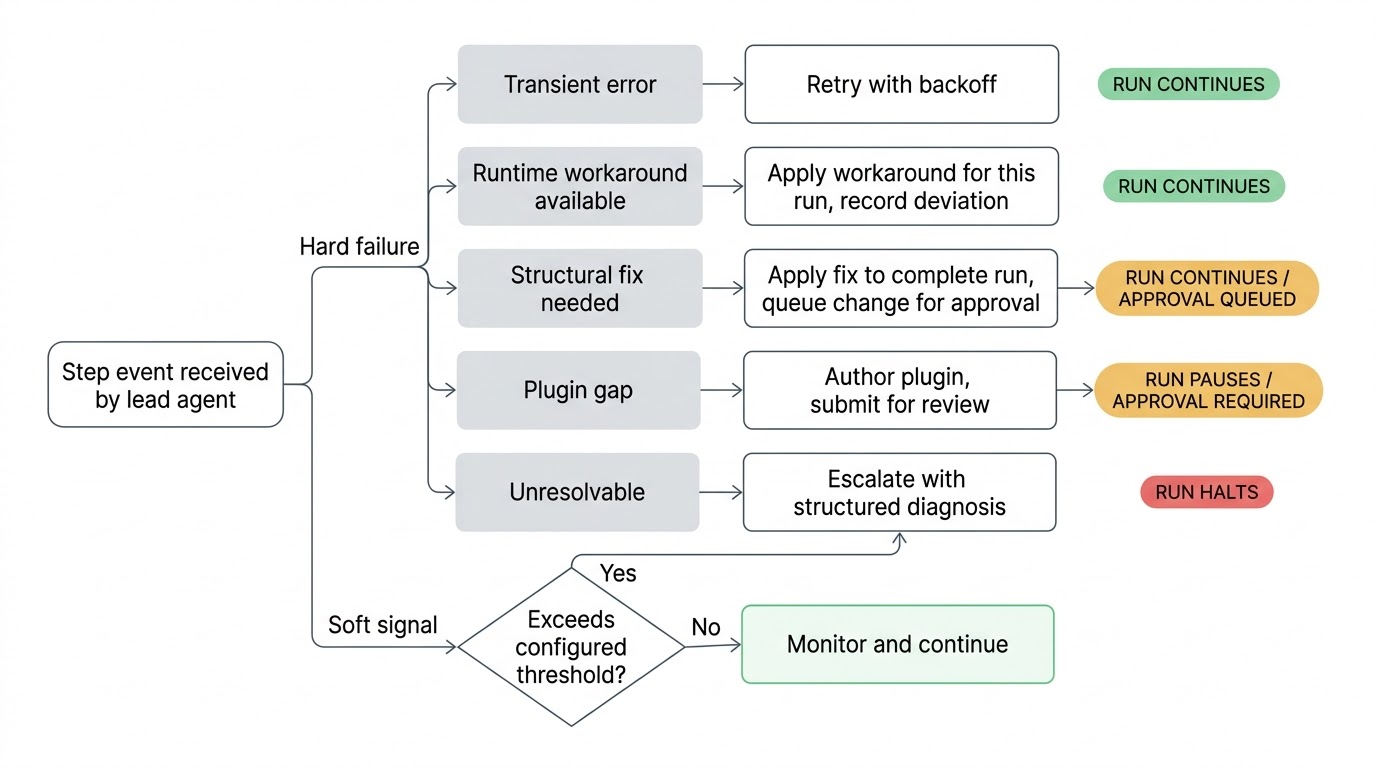
Wenn etwas schiefgeht, triagiert der Lead. Ein instabiler Netzwerkaufruf bekommt einen Retry mit Backoff. Ein geänderter API-Endpunkt, der sich umgehen lässt, wird für diesen Lauf umgangen. Ein strukturelles Problem in der Workflow-Definition bekommt einen vorgeschlagenen Fix, der angewendet wird, um den Lauf abzuschließen, wobei die Änderung zur Genehmigung eingereicht wird, bevor sie permanent wird. Eine defekte Plugin-Integration bekommt ein neues oder aktualisiertes Plugin, das erstellt und zur Prüfung eingereicht wird. Wenn der Lead seine Versuche ausgeschöpft hat und das Problem nicht lösen kann, eskaliert er an Sie mit einer strukturierten Diagnose dessen, was er versucht hat und was er als Ursache vermutet.
Der Workflow läuft weiter, wann immer das sicher möglich ist. Wenn ein Schritt blockiert ist, pausieren nur die nachgelagerten Schritte, die davon abhängen, während parallele Zweige weiterlaufen. Der Lead kennt den Abhängigkeitsgraphen und pausiert nur das, was tatsächlich blockiert ist.
Warum der Kontext, den Sie in Workflows einbauen, entscheidend ist
Was Self-Healing in der Praxis funktionieren lässt, ist, dass Triggerfish-Workflows von Anfang an reichhaltige Metadaten auf Schrittebene erfordern. Das ist nicht optional und keine Dokumentation um ihrer selbst willen; es ist das, wovon der Lead-Agent seine Schlüsse zieht.
Jeder Schritt in einem Workflow hat vier Pflichtfelder über die Aufgabendefinition hinaus: eine Beschreibung dessen, was der Schritt mechanisch tut, ein Intent-Statement, das erklärt, warum dieser Schritt existiert und welchem Geschäftszweck er dient, ein Expects-Feld, das beschreibt, welche Daten er als Eingabe erwartet und in welchem Zustand vorherige Schritte sein müssen, und ein Produces-Feld, das beschreibt, was er in den Kontext für nachgelagerte Schritte schreibt.
So sieht das in der Praxis aus. Angenommen, Sie automatisieren die Zugangsbereitstellung für neue Mitarbeiter. Ein neuer Mitarbeiter beginnt am Montag und der Workflow muss Konten in Active Directory erstellen, die GitHub-Org-Mitgliedschaft bereitstellen, die Okta-Gruppen zuweisen und ein Jira-Ticket zur Bestätigung des Abschlusses erstellen. Ein Schritt holt den Mitarbeiterdatensatz aus Ihrem HR-System. Sein Intent-Feld sagt nicht einfach „Mitarbeiterdatensatz abrufen." Es lautet: „Dieser Schritt ist die maßgebliche Datenquelle für jede nachgelagerte Bereitstellungsentscheidung. Rolle, Abteilung und Startdatum aus diesem Datensatz bestimmen, welche AD-Gruppen zugewiesen, welche GitHub-Teams bereitgestellt und welche Okta-Richtlinien angewendet werden. Wenn dieser Schritt veraltete oder unvollständige Daten liefert, wird jeder nachgelagerte Schritt die falschen Zugänge bereitstellen."

Der Lead liest dieses Intent-Statement, wenn der Schritt fehlschlägt, und versteht, was auf dem Spiel steht. Er weiß, dass ein unvollständiger Datensatz bedeutet, dass die Zugangsbereitstellungsschritte mit fehlerhaften Eingaben laufen und möglicherweise einer realen Person, die in zwei Tagen anfängt, falsche Berechtigungen erteilen. Dieser Kontext bestimmt, wie er versucht, die Situation zu beheben, ob er nachgelagerte Schritte pausiert und was er Ihnen mitteilt, falls er eskaliert.
Ein weiterer Schritt im selben Workflow prüft das Produces-Feld des HR-Abrufschritts und weiß, dass er .employee.role und .employee.department als nicht-leere Strings erwartet. Wenn Ihr HR-System seine API aktualisiert und diese Felder stattdessen unter .employee.profile.role verschachtelt zurückgibt, erkennt der Lead die Schema-Abweichung, wendet ein Laufzeit-Mapping für diesen Lauf an, damit der neue Mitarbeiter korrekt bereitgestellt wird, und schlägt einen strukturellen Fix vor, um die Schrittdefinition zu aktualisieren. Sie haben keine Schema-Migrationsregel oder Fehlerbehandlung für genau diesen Fall geschrieben. Der Lead hat es aus dem bereits vorhandenen Kontext abgeleitet.
Deshalb ist die Qualität der Workflow-Erstellung wichtig. Die Metadaten sind kein Formalismus; sie sind der Treibstoff, mit dem das Self-Healing-System arbeitet. Ein Workflow mit oberflächlichen Schrittbeschreibungen ist ein Workflow, über den der Lead nicht nachdenken kann, wenn es darauf ankommt.
Live-Beobachtung bedeutet, Probleme zu erkennen, bevor sie zu Ausfällen werden
Weil der Lead in Echtzeit beobachtet, kann er auf schwache Signale reagieren, bevor tatsächlich etwas kaputt geht. Ein Schritt, der bisher in zwei Sekunden abgeschlossen war, braucht jetzt vierzig. Ein Schritt, der bei jedem bisherigen Lauf Daten zurückgab, liefert ein leeres Ergebnis. Ein bedingter Zweig wird genommen, der in der gesamten Laufhistorie noch nie genommen wurde. Nichts davon sind harte Fehler und der Workflow läuft weiter, aber es sind Signale, dass sich etwas in der Umgebung geändert hat. Besser, man erkennt sie, bevor der nächste Schritt versucht, fehlerhafte Daten zu verarbeiten.
Die Empfindlichkeit dieser Prüfungen ist pro Workflow konfigurierbar. Eine nächtliche Berichtserstellung mag lockere Schwellenwerte haben, während eine Zugangsbereitstellungspipeline genau hinschaut. Sie legen fest, welches Maß an Abweichung die Aufmerksamkeit des Lead rechtfertigt.
Es bleibt Ihr Workflow
Der Lead-Agent und sein Team können Ihre kanonische Workflow-Definition nicht ohne Ihre Genehmigung ändern. Wenn der Lead einen strukturellen Fix vorschlägt, wendet er den Fix an, um den aktuellen Lauf abzuschließen, und reicht die Änderung als Vorschlag ein. Sie sehen ihn in Ihrer Warteschlange, Sie sehen die Begründung, Sie genehmigen oder lehnen ab. Wenn Sie ablehnen, wird diese Ablehnung aufgezeichnet und jeder zukünftige Lead, der an diesem Workflow arbeitet, weiß, dass er dasselbe nicht erneut vorschlagen soll.
Es gibt eine Sache, die der Lead unabhängig von der Konfiguration niemals ändern kann: sein eigenes Mandat. Die Self-Healing-Policy in der Workflow-Definition, ob pausiert werden soll, wie lange Retries laufen, ob eine Genehmigung erforderlich ist, ist vom Eigentümer verfasste Policy. Der Lead kann Aufgabendefinitionen patchen, API-Aufrufe aktualisieren, Parameter anpassen und neue Plugins erstellen. Er kann nicht die Regeln ändern, die sein eigenes Verhalten bestimmen. Diese Grenze ist fest im Code verankert. Ein Agent, der die Genehmigungspflicht für seine eigenen Vorschläge abschalten könnte, würde das gesamte Vertrauensmodell sinnlos machen.
Plugin-Änderungen durchlaufen denselben Genehmigungspfad wie jedes andere von einem Agenten erstellte Plugin in Triggerfish. Die Tatsache, dass das Plugin erstellt wurde, um einen defekten Workflow zu reparieren, verleiht ihm kein besonderes Vertrauen. Es durchläuft dieselbe Prüfung, als hätten Sie einen Agenten gebeten, eine komplett neue Integration von Grund auf zu bauen.
Verwaltung über jeden Kanal, den Sie bereits nutzen
Sie sollten sich nicht in ein separates Dashboard einloggen müssen, um zu wissen, was Ihre Workflows tun. Self-Healing-Benachrichtigungen kommen dort an, wo Sie Triggerfish konfiguriert haben: eine Interventionszusammenfassung auf Slack, eine Genehmigungsanfrage auf Telegram, ein Eskalationsbericht per E-Mail. Das System kommt zu Ihnen auf dem Kanal, der für die jeweilige Dringlichkeit sinnvoll ist, ohne dass Sie eine Monitoring-Konsole aktualisieren müssen.
Das Workflow-Statusmodell ist dafür gebaut. Status ist kein flacher String, sondern ein strukturiertes Objekt, das alles mitbringt, was eine Benachrichtigung braucht, um aussagekräftig zu sein: den aktuellen Zustand, das Gesundheitssignal, ob ein Patch in Ihrer Genehmigungswarteschlange liegt, das Ergebnis des letzten Laufs und was der Lead gerade tut. Ihre Slack-Nachricht kann sagen „Der Zugangsbereitstellungs-Workflow ist pausiert, der Lead erstellt einen Plugin-Fix, eine Genehmigung wird erforderlich sein" in einer einzigen Benachrichtigung, ohne dass Sie nach Kontext suchen müssen.
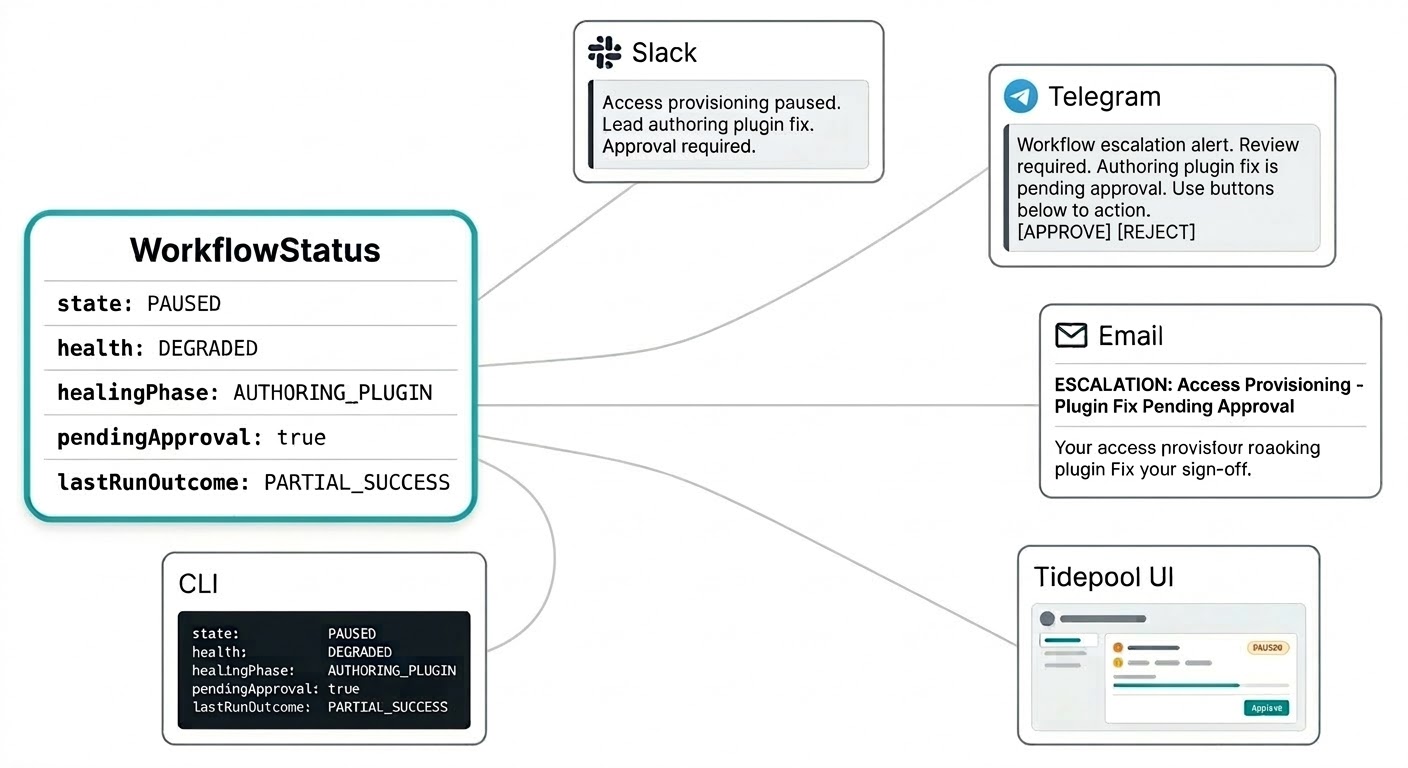
Derselbe strukturierte Status speist die Live-Tidepool-Oberfläche, wenn Sie das vollständige Bild wollen. Dieselben Daten, andere Darstellung.
Was das für IT-Teams tatsächlich verändert
Die Leute in Ihrer Organisation, die ihre Woche damit verbringen, defekte Workflows zu reparieren, machen keine einfache Arbeit. Sie debuggen verteilte Systeme, lesen API-Changelogs und rekonstruieren, warum ein Workflow, der gestern noch lief, heute fehlschlägt. Das ist wertvolles Urteilsvermögen, und im Moment wird es fast vollständig davon aufgezehrt, bestehende Automatisierung am Leben zu halten, anstatt neue Automatisierung zu bauen oder schwierigere Probleme zu lösen.
Self-Healing Workflows beseitigen dieses Urteilsvermögen nicht, aber sie verschieben den Zeitpunkt, an dem es zum Einsatz kommt. Anstatt um Mitternacht einen defekten Workflow zu debuggen, prüfen Sie morgens einen vorgeschlagenen Fix und entscheiden, ob die Diagnose des Lead richtig ist. Sie sind der Genehmiger einer vorgeschlagenen Änderung, nicht der Autor eines Patches unter Zeitdruck.
Das ist das Arbeitsmodell, auf dem Triggerfish aufgebaut ist: Menschen, die Agentenarbeit prüfen und genehmigen, anstatt die Arbeit selbst auszuführen, die Agenten übernehmen können. Die Automatisierungsabdeckung steigt, während der Wartungsaufwand sinkt, und das Team, das 75 Prozent seiner Zeit für Instandhaltung aufgewendet hat, kann den Großteil dieser Zeit auf Aufgaben umlenken, die tatsächlich menschliches Urteilsvermögen erfordern.
Ab heute verfügbar
Self-Healing Workflows werden ab heute als optionale Funktion in der Triggerfish-Workflow-Engine ausgeliefert. Die Aktivierung erfolgt pro Workflow über den Workflow-Metadatenblock. Wenn Sie es nicht aktivieren, ändert sich nichts daran, wie Ihre Workflows laufen.
Das ist nicht deshalb wichtig, weil es ein schwieriges technisches Problem ist (auch wenn es das ist), sondern weil es direkt das Problem adressiert, das Enterprise-Automatisierung teurer und schmerzhafter gemacht hat, als sie sein müsste. Das Workflow-Wartungsteam sollte der erste Job sein, den AI-Automatisierung übernimmt. Das ist der richtige Einsatz dieser Technologie, und dafür hat Triggerfish das gebaut.
Wenn Sie tiefer einsteigen möchten, wie es funktioniert, finden Sie die vollständige Spezifikation im Repository. Wenn Sie es ausprobieren möchten, führt Sie der Workflow-Builder-Skill durch die Erstellung Ihres ersten Self-Healing Workflows.