
すべてのエンタープライズ自動化プログラムは同じ壁にぶつかります。ServiceNowチケットルーティング、Terraformドリフト修正、証明書ローテーション、ADグループプロビジョニング、SCCMパッチデプロイメント、CI/CDパイプラインオーケストレーション。最初の10〜20のワークフローは簡単に投資を正当化し、ROIの計算は、ワークフロー数が数百を超え、ITチームの週の重要な部分が新しい自動化の構築から既存の自動化を崩壊から守ることにシフトするまではうまくいきます。
ペイヤーポータルが認証フローを再設計し、クレーム提出ワークフローが認証を停止します。Salesforceがメタデータ更新をプッシュし、リードからオポチュニティへのパイプラインのフィールドマッピングがnullを書き始めます。AWSがAPIバージョンを非推奨にし、1年間クリーンに動いていたTerraformプランがすべてのapplyで400エラーを投げ始めます。誰かがチケットを提出し、他の誰かが何が変わったかを解明し、パッチを当て、テストし、修正をデプロイします。その間、自動化されていたプロセスは手動で実行されるか、まったく実行されませんでした。
これはメンテナンストラップであり、実装の失敗ではなく構造的なものです。従来の自動化は正確なパスをたどり、正確なパターンに一致し、ワークフローが作成されたときに存在したものから現実が逸脱した瞬間に壊れます。調査は一致しています:組織は自動化プログラムの総コストの70〜75パーセントを新しいワークフローの構築ではなく、既にあるワークフローのメンテナンスに費やしています。大規模なデプロイメントでは、45パーセントのワークフローが毎週壊れます。
Triggerfishのワークフローエンジンはこれを変えるために構築されました。自己修復ワークフローは本日出荷され、これまでのプラットフォームで最も重要な機能です。
自己修復が実際に意味すること
この言葉は緩く使われているので、これが何であるかについて直接的に説明します。
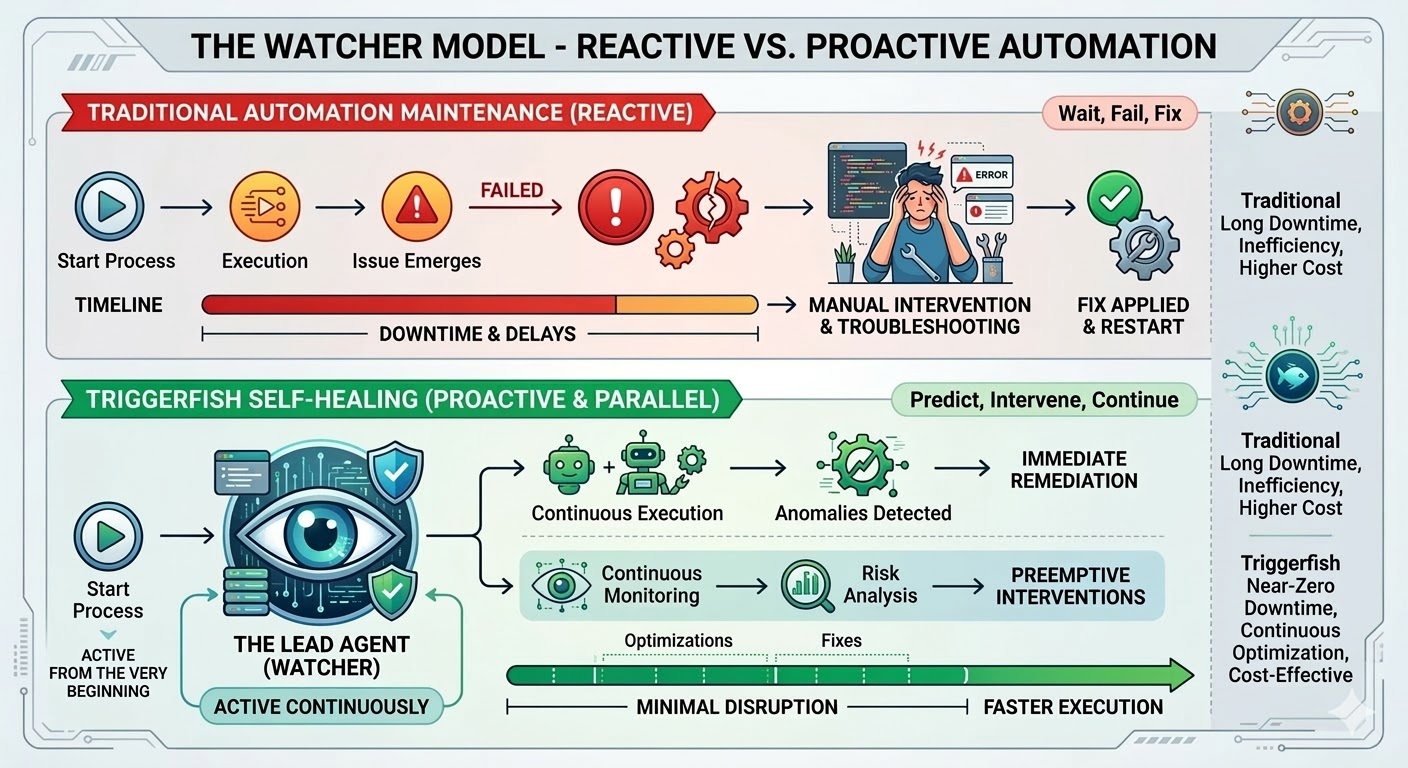
Triggerfishのワークフローで自己修復を有効にすると、そのワークフローが実行を開始した瞬間にリードエージェントが生成されます。何かが壊れたときに起動するのではなく、最初のステップから監視していて、ワークフローが進行するにつれてエンジンからライブイベントストリームを受信し、すべてのステップをリアルタイムで観察します。
リードはすべての単一のステップが実行される前にワークフロー定義全体を知っています。すべてのステップの背後にある意図、各ステップが前のステップに何を期待しているか、次のステップのために何を生成するかを含みます。また、過去の実行の履歴も知っています:何が成功し、何が失敗し、どのパッチが提案され、人間がそれを承認または拒否したかを。対処すべきことを識別したとき、そのコンテキストすべてがすでにメモリにあります。後で再構築するのではなく、ずっと監視していたからです。
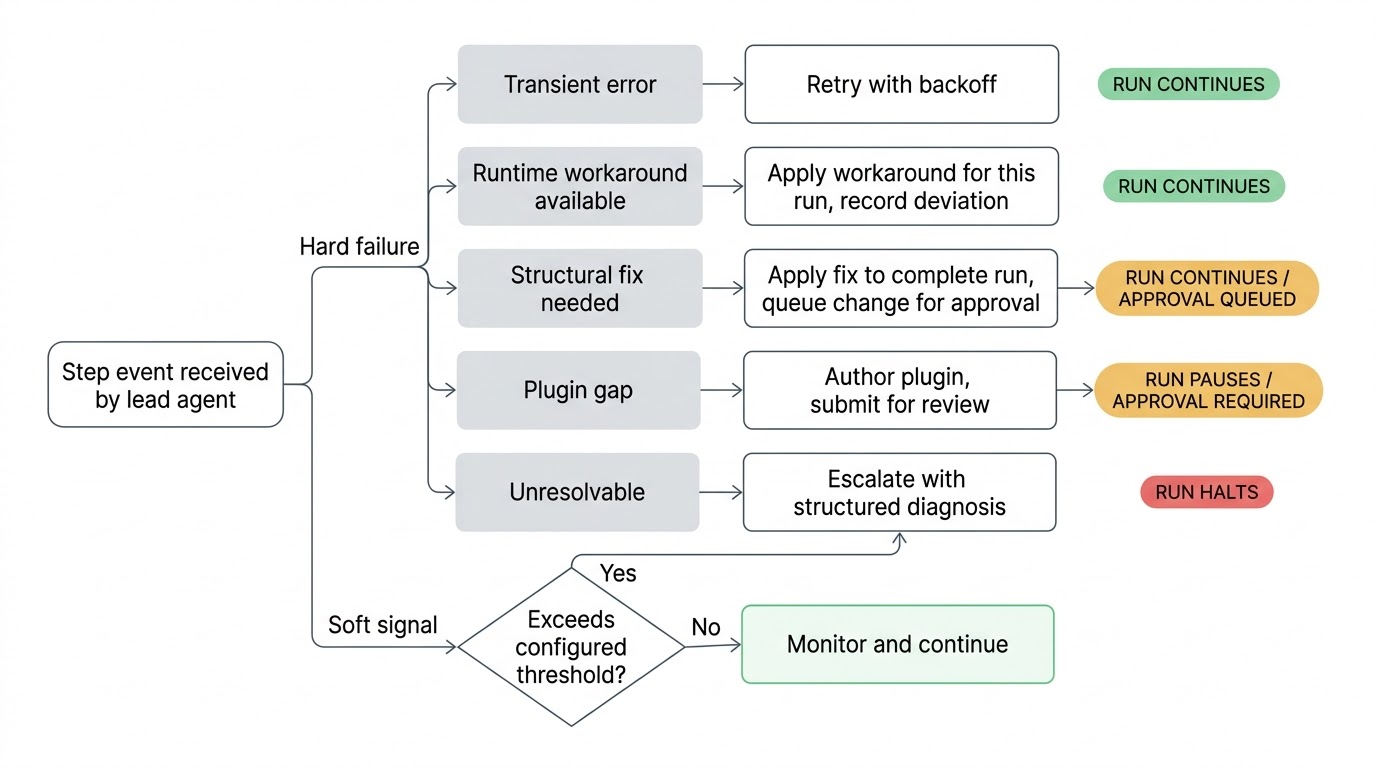
何かがうまくいかないと、リードがトリアージします。不安定なネットワーク呼び出しはバックオフ付きでリトライされます。回避できる変更されたAPIエンドポイントはこの実行のために回避されます。ワークフロー定義の構造的な問題は、実行を完了するための提案された修正を適用され、変更が永続的になる前に承認のために提出されます。壊れたプラグイン統合には、新しいまたは更新されたプラグインが作成されてレビューのために提出されます。リードが試みを尽くして問題を解決できない場合、試みたことと根本原因が何だと思うかの構造化された診断を添えてあなたにエスカレートします。
ワークフローは安全に実行できる場合はいつでも実行を続けます。ステップがブロックされた場合、それに依存するダウンストリームステップのみが一時停止し、並行ブランチは継続します。リードは依存関係グラフを知っており、実際にブロックされているものだけを一時停止します。
ワークフローに構築するコンテキストが重要な理由
自己修復が実際に機能するのは、Triggerfishのワークフローがあなたがそれらを書く瞬間から豊富なステップレベルのメタデータを要求するからです。これはオプションではなく、そのためだけのドキュメントでもありません。リードエージェントが推論するのはそこからです。
ワークフローのすべてのステップには、タスク定義自体を超えた4つの必須フィールドがあります:ステップが機械的に何をするかの説明、このステップが存在する理由と何のビジネス目的を果たすかを説明する意図ステートメント、受け取ると想定されるデータと前のステップがどのような状態でなければならないかを説明するexpectsフィールド、ダウンストリームステップが使用するためにコンテキストに何を書き込むかを説明するproducesフィールド。
これが実際にどのように見えるか説明します。従業員アクセスプロビジョニングを自動化しているとします。新入社員が月曜日に入社し、ワークフローはActive Directoryにアカウントを作成し、GitHubの組織メンバーシップをプロビジョニングし、Oktaグループを割り当て、完了を確認するJiraチケットを開く必要があります。あるステップがHRシステムから従業員レコードをフェッチします。そのintentフィールドには単に「従業員レコードを取得」とは書かれていません。「このステップは、すべてのダウンストリームプロビジョニング決定の真実のソースです。このレコードからの役割、部門、入社日は、どのADグループが割り当てられるか、どのGitHubチームがプロビジョニングされるか、どのOktaポリシーが適用されるかを決定します。このステップが古いまたは不完全なデータを返す場合、すべてのダウンストリームステップは間違ったアクセスをプロビジョニングします」と書かれています。

リードはステップが失敗したときにその意図ステートメントを読み、何が危機に瀕しているかを理解します。部分的なレコードは、アクセスプロビジョニングステップが不良な入力で実行され、2日後に入社する実際の人物に間違ったアクセス権を付与する可能性があることを知っています。そのコンテキストは、リードが回復を試みる方法、ダウンストリームステップを一時停止するかどうか、エスカレートする場合に何を伝えるかを形成します。
同じワークフローの別のステップは、HRフェッチステップのproducesフィールドを確認し、.employee.roleと.employee.departmentが空でない文字列であることを期待していることを知っています。HRシステムがAPIを更新し、それらのフィールドを.employee.profile.roleの下にネストして返し始めると、リードはスキーマドリフトを検出し、新入社員が正しくプロビジョニングされるようにこの実行のためのランタイムマッピングを適用し、ステップ定義を更新するための構造的な修正を提案します。あなたはこの特定のケースのためのスキーマ移行ルールや例外処理を書きませんでした。リードはすでにあったコンテキストからそれを推論しました。
これがワークフローオーサリングの品質が重要な理由です。メタデータは儀式ではありません。それが自己修復システムが動作する燃料です。浅いステップの説明を持つワークフローは、重要な時にリードが推論できないワークフローです。
ライブで監視することは、失敗になる前に問題をキャッチすること
リードはリアルタイムで監視しているため、物事が実際に壊れる前にソフトシグナルに対処できます。歴史的に2秒で完了するステップが今40秒かかっています。すべての以前の実行でデータを返したステップが空の結果を返します。完全な実行履歴で一度も取られたことのない条件ブランチが取られています。これらはハードエラーではなく、ワークフローは実行を続けますが、環境で何かが変わったことを示すシグナルです。次のステップが不良なデータを消費しようとする前にキャッチする方がよいです。
これらのチェックの感度はワークフローごとに設定可能です。夜間レポート生成は緩いしきい値を持つかもしれませんが、アクセスプロビジョニングパイプラインは注意深く監視します。どのレベルの逸脱がリードの注意を warrantsするかを設定します。
それでもあなたのワークフローです
リードエージェントとそのチームは、あなたの承認なしにカノニカルなワークフロー定義を変更できません。リードが構造的な修正を提案すると、現在の実行を完了するために修正を適用し、変更を提案として提出します。キューでそれを確認し、推論を見て、承認または拒否します。拒否した場合、その拒否が記録され、そのワークフローで作業するすべての将来のリードは同じことを再び提案しないことを知っています。
設定に関係なく、リードが決して変更できないことが1つあります:自身のマンデートです。ワークフロー定義の自己修復ポリシー(一時停止するかどうか、どれだけリトライするか、承認を要求するかどうか)は、オーナーが作成したポリシーです。リードはタスク定義にパッチを当て、APIコールを更新し、パラメーターを調整し、新しいプラグインを作成できます。自身の動作を管理するルールは変更できません。その境界はハードコードされています。自身の提案を管理する承認要件を無効にできるエージェントは、信頼モデル全体を無意味にします。
プラグインの変更は、Triggerfishでエージェントが作成した任意のプラグインと同じ承認パスをたどります。プラグインが壊れたワークフローを修正するために作成されたという事実は、特別な信頼を与えません。スクラッチから新しい統合を構築するようエージェントに依頼した場合と同じレビューを経ます。
すでに使用しているすべてのチャンネルで管理する
ワークフローが何をしているかを知るために別のダッシュボードにログインする必要はありません。自己修復通知は、Triggerfishが到達するよう設定したどこでも届きます:Slackへの介入サマリー、Telegramへの承認リクエスト、メールへのエスカレーションレポート。システムは、モニタリングコンソールをリフレッシュすることなく、緊急度に合ったチャンネルであなたのところに来ます。
ワークフローステータスモデルはこのために構築されています。ステータスはフラットな文字列ではなく、通知が意味のあるものになるために必要なすべてを持つ構造化されたオブジェクトです:現在の状態、健康シグナル、承認キューにパッチがあるかどうか、最後の実行の結果、リードが現在何をしているか。SlackメッセージはコンテキストをHuntingすることなく、単一の通知で「アクセスプロビジョニングワークフローが一時停止中、リードがプラグイン修正を作成中、承認が必要になる」と言えます。
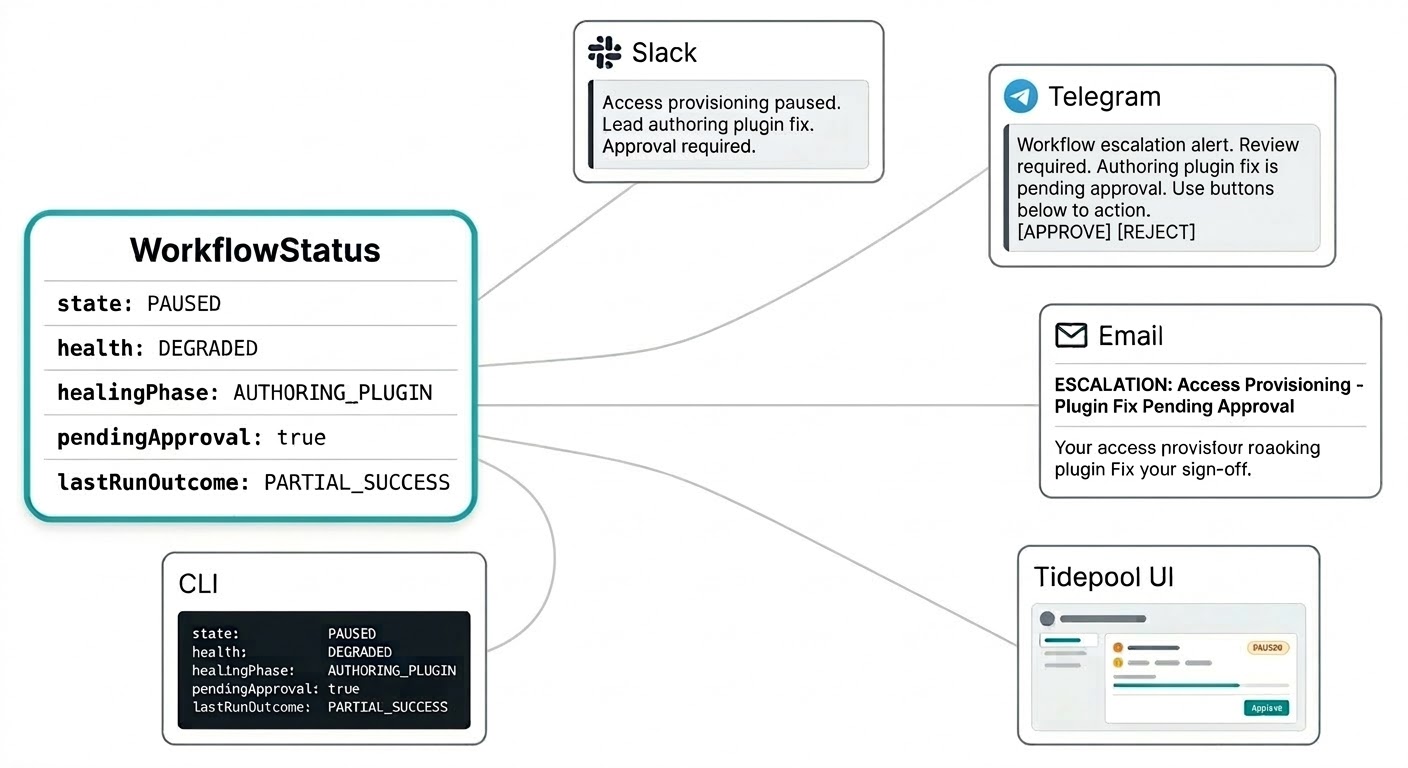
同じ構造化されたステータスが、完全な画像が必要なときのライブTidepoolインターフェースにフィードされます。同じデータ、異なるサーフェス。
IT チームにとって実際に何が変わるか
ワークフローの修正に週を費やしている組織内の人々は、低スキルの仕事をしているわけではありません。分散システムをデバッグし、API変更ログを読み、昨日はうまくいったワークフローが今日失敗している理由をリバースエンジニアリングしています。それは価値のある判断であり、今は新しい自動化の構築やより難しい問題の解決ではなく、既存の自動化を生かし続けることにほぼ完全に消費されています。
自己修復ワークフローはその判断を排除しませんが、それが適用されるタイミングをシフトします。真夜中に壊れたワークフローと格闘する代わりに、朝に提案された修正をレビューし、リードの診断が正しいかどうかを決定します。プレッシャー下でパッチの著者ではなく、提案された変更の承認者です。
それがTriggerfishが構築されている労働モデルです:エージェントが処理できる作業を実行するのではなく、エージェントの作業をレビューして承認する人間。自動化カバレッジが上がりながらメンテナンスの負担が下がり、70%の時間をメンテナンスに費やしていたチームは、その時間のほとんどを実際に人間の判断を必要とすることにリダイレクトできます。
本日出荷
自己修復ワークフローは本日、Triggerfishワークフローエンジンのオプション機能として出荷されます。ワークフローごとにオプトインで、ワークフローメタデータブロックで設定されます。有効にしない場合、ワークフローの実行方法に何も変わりません。
これが重要なのは、難しい技術的問題だからではなく(そうですが)、エンタープライズ自動化を必要以上にコストが高く痛みを伴うものにしてきたことを直接解決するからです。ワークフローメンテナンスチームは、AI自動化が最初に担うべき仕事です。それがこのテクノロジーの正しい使用法であり、それがTriggerfishが構築したものです。
仕組みを詳しく知りたい場合は、完全なスペックがリポジトリにあります。試したい場合は、workflow-builder skillが最初の自己修復ワークフローを書く手順を案内します。