
Cos'è l'avvelenamento dei modelli AI? È un attacco informatico in cui malintenzionati corrompono deliberatamente i dati o il processo di addestramento di un sistema AI per manipolarne il comportamento. Questo fa sì che il modello produca output errati, distorti o dannosi, spesso senza che nessuno se ne accorga finché il danno reale non è già stato causato.
La maggior parte delle persone presume che le minacce AI provengano dall'esterno, come hacker che cercano di violare un sistema. Ma con l'avvelenamento dei modelli, l'attacco avviene silenziosamente, sepolto all'interno dei dati da cui l'AI apprende. Quando il modello viene implementato e sta causando danni, risalire all'origine del problema è incredibilmente difficile. Questa guida analizza esattamente come funziona, perché è importante per la Sua azienda e cosa stanno facendo le organizzazioni più intelligenti per proteggersi.
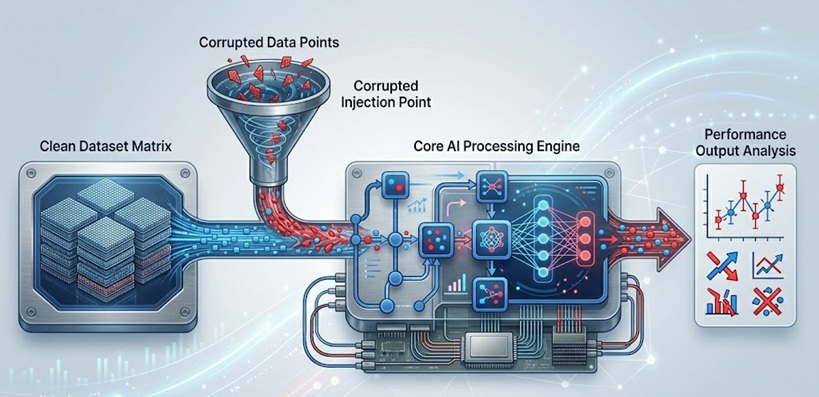
Perché l'avvelenamento dei modelli AI è più pericoloso di quanto sembri
Pensi a un modello AI come a uno studente. Fornisca a quello studente informazioni accurate e di alta qualità per anni, e diventerà affidabile e degno di fiducia. Ma cosa succederebbe se qualcuno introducesse libri di testo ingannevoli in classe dal primo giorno? Al momento del diploma, la visione del mondo dello studente è distorta, e non lo sa nemmeno.
È esattamente così che funziona l'avvelenamento dei modelli. Gli aggressori non devono violare un sistema in tempo reale. Hanno solo bisogno di accesso alla pipeline di addestramento, al dataset, o talvolta anche al loop di feedback che il modello utilizza per continuare a migliorare. Una volta che i dati avvelenati vengono mescolati, il modello apprende da essi proprio come apprende da tutto il resto.
Ciò che rende questa minaccia particolarmente inquietante è quanto sia invisibile. Il modello continua a funzionare. Continua a dare risposte. Potrebbe persino ottenere buoni punteggi su benchmark standard. La corruzione non è ovvia, è chirurgica. E in ambienti ad alto rischio come sanità, finanza o sistemi autonomi, un modello sottilmente corrotto può causare enormi danni prima che qualcuno suoni l'allarme.
Comprendere i rischi di sicurezza AI che la Sua organizzazione affronta inizia con il riconoscere che la minaccia non è sempre una violazione drammatica. A volte è un dataset silenziosamente avvelenato che si trova alla base di tutto.
Come funziona effettivamente l'avvelenamento dei modelli
Ci sono alcuni modi diversi in cui gli aggressori possono eseguire questo tipo di attacco, e ciascuno mira a una parte diversa della pipeline AI.
Avvelenamento dei dati
Questo è il metodo più comune. L'aggressore inietta esempi corrotti o manipolati nel dataset di addestramento. Se l'AI sta imparando a rilevare email spam, l'aggressore potrebbe aggiungere migliaia di messaggi spam etichettati come legittimi. Con il tempo, il modello impara a fidarsi di ciò che dovrebbe rifiutare.
L'avvelenamento dei dati è particolarmente facile da realizzare quando i sistemi AI si basano su dati crowdsourced, contenuti web scrapati o dataset di terze parti. La maggior parte delle organizzazioni ha visibilità limitata su esattamente da dove provengono i loro dati di addestramento, il che apre completamente la porta.
Attacchi backdoor
Un attacco backdoor è più sofisticato. Qui, l'aggressore non corrompe semplicemente il comportamento generale del modello. Pianta un trigger nascosto, un pattern di input specifico che fa sì che il modello si comporti in un certo modo a comando.
Ad esempio, un modello di riconoscimento delle immagini potrebbe funzionare perfettamente su ogni foto normale. Ma se l'aggressore aggiunge una piccola filigrana specifica a un'immagine, il modello la classifica improvvisamente in modo errato. Il trigger è invisibile agli utenti ma totalmente controllabile dall'aggressore.
Attacchi di fine-tuning del modello
Nei casi in cui le organizzazioni utilizzano modelli pre-addestrati da fonti di terze parti e poi li perfezionano sui propri dati, l'avvelenamento può essere già incorporato prima ancora che li tocchino. Questa è una preoccupazione crescente man mano che più aziende adottano fondazioni AI open source o concesse in licenza commerciale senza verificare cosa c'è già all'interno.

Tipi di avvelenamento dei modelli AI: Un riferimento rapido
| Tipo di attacco | Metodo | Obiettivo primario |
|---|---|---|
| Avvelenamento dei dati | Iniezione di esempi di addestramento falsi | Dataset di addestramento |
| Attacco backdoor | Incorporamento di trigger nascosti nel modello | Fase di inferenza |
| Inversione delle etichette | Etichettatura errata dei dati per confondere la classificazione | Modelli di apprendimento supervisionato |
| Attacco di fine-tuning del modello | Fornitura di pesi del modello pre-avvelenati | Pipeline di apprendimento per trasferimento |
| Attacco gradiente | Manipolazione degli aggiornamenti del modello durante l'addestramento | Sistemi di apprendimento federato |
Scenari del mondo reale dove questo diventa serio
Aiuta vedere come questo si svolge nella pratica. Ecco alcuni esempi che illustrano quanto possa essere ampio l'impatto.
Strumenti di diagnosi medica: Un'AI addestrata a rilevare tumori nelle scansioni radiologiche potrebbe essere avvelenata per perdere costantemente un tipo specifico di crescita. I pazienti ricevono certificati di salute puliti. Il modello non segnala mai il problema. Il danno è invisibile e potenzialmente fatale.
Rilevamento di frodi finanziarie: Un modello di rilevamento frodi che è stato avvelenato potrebbe imparare a lasciar passare certi schemi di transazione, creando essenzialmente una backdoor per crimini finanziari per passare inosservati su larga scala.
Moderazione dei contenuti: Le piattaforme sociali che utilizzano l'AI per filtrare contenuti dannosi potrebbero essere manipolate per consentire a certe categorie di abusi di passare costantemente, mentre sembrano funzionare normalmente in superficie.
Veicoli autonomi: Un sistema di guida autonoma avvelenato durante l'addestramento potrebbe non riconoscere un cartello stradale specifico in determinate condizioni di illuminazione. Una backdoor potrebbe teoricamente essere collegata a un trigger visivo personalizzato che causa comportamenti pericolosi su richiesta.
Questi non sono casi peggiori ipotetici. Mentre l'AI viene incorporata in più sistemi critici, la superficie di attacco continua ad espandersi. Le aziende che comprendono come vengono costruite e implementate le funzionalità AI sono in una posizione migliore per identificare dove vivono i rischi di avvelenamento nel proprio stack.
Cose da sapere
- L'avvelenamento dei modelli non è la stessa cosa degli attacchi adversariali. Gli attacchi adversariali avvengono al momento dell'inferenza manipolando gli input. L'avvelenamento avviene durante l'addestramento, rendendolo molto più difficile da rilevare a posteriori.
- I modelli open source comportano rischi ereditati. Scaricare e implementare un modello pre-addestrato senza verificarne la cronologia di addestramento significa accettare tutto ciò che è stato incorporato in esso.
- L'apprendimento federato introduce nuove superfici di attacco. Quando i modelli vengono addestrati su dispositivi o organizzazioni distribuiti, il contributo di dati di ciascun partecipante è un potenziale punto di ingresso per l'avvelenamento.
- I modelli avvelenati possono superare i test standard. Gli aggressori spesso progettano attacchi di avvelenamento per preservare l'accuratezza complessiva sui dataset di benchmark, quindi i test di routine non rileveranno il problema.
- L'esposizione normativa è reale. Nelle industrie regolamentate, l'implementazione di un modello che produce output discriminatori o errati, anche inconsapevolmente, può portare a gravi conseguenze di conformità.
- La provenienza dei dati è più importante di quanto la maggior parte dei team pensi. Sapere da dove proviene ogni pezzo di dati di addestramento, ed essere in grado di verificarlo, è una delle difese più sottoutilizzate contro questa classe di attacchi.
Come le organizzazioni stanno reagendo
Difendersi da cos'è l'avvelenamento dei modelli AI richiede un approccio a strati. Nessuna singola soluzione ferma ogni variante di questo attacco. Ma le organizzazioni che prendono sul serio la sicurezza AI stanno costruendo abitudini e sistemi che rendono l'avvelenamento molto più difficile da realizzare e più facile da intercettare.
Audit dei dati e tracciamento della provenienza: Il punto di partenza più efficace è conoscere i Suoi dati. I team dovrebbero documentare da dove provengono i dati di addestramento, chi li ha contribuiti, come sono stati etichettati e se sono state introdotte anomalie lungo il percorso. Gli strumenti che segnalano i valori statistici anomali nei dataset possono catturare i batch avvelenati prima che raggiungano la pipeline di addestramento.
Monitoraggio del comportamento del modello: Una volta che un modello è implementato, monitorare i suoi output per schemi inaspettati è critico. Se un modello di rilevamento frodi inizia improvvisamente ad approvare una categoria di transazioni che prima segnalava costantemente, vale la pena indagare. La deriva comportamentale può essere un sintomo di avvelenamento che è passato durante l'addestramento.
Test adversariali: Eseguire stress test deliberati contro modelli implementati, inclusi scenari progettati per esporre trigger nascosti, aiuta a scoprire attacchi backdoor prima che gli avversari del mondo reale li trovino per primi.
Audit di terze parti: Per le organizzazioni che utilizzano modelli di provenienza esterna, audit indipendenti dell'architettura del modello e della cronologia di addestramento forniscono uno strato aggiuntivo di fiducia. Questo è particolarmente importante quando quei modelli vanno in applicazioni ad alto rischio.
Comprendere come l'architettura AI influisce sulla vulnerabilità aiuta i team tecnici a prendere decisioni migliori su dove aggiungere controlli e come strutturare le difese contro gli attacchi alla catena di approvvigionamento.
Cosa rende alcuni sistemi AI più vulnerabili
Non tutti i sistemi AI sono ugualmente esposti. Diversi fattori tendono ad aumentare la suscettibilità di un modello all'avvelenamento.
| Fattore di rischio | Perché aumenta la vulnerabilità |
|---|---|
| Dipendenza da dati di terze parti | Meno controllo su ciò che entra nella pipeline di addestramento |
| Dataset grandi e non auditati | Più difficile individuare campioni corrotti individuali su larga scala |
| Configurazioni di apprendimento continuo | L'ingestione continua di dati significa esposizione continua |
| Monitoraggio limitato post-implementazione | Il comportamento avvelenato può passare inosservato per mesi |
| Uso di fondazioni open source pre-addestrate | Avvelenamento ereditato da fonti a monte |
Cosa ci dice la conversazione più ampia
La preoccupazione per l'avvelenamento dei modelli AI non esiste nel vuoto. Si inserisce in una conversazione molto più ampia che pensatori seri sollevano da anni.
Stephen Hawking ha notoriamente avvertito che l'AI potrebbe essere la cosa migliore o peggiore mai accaduta all'umanità, dipendendo interamente dal fatto se la sviluppiamo responsabilmente. La sua preoccupazione non riguardava solo i sistemi super-intelligenti che diventano incontrollabili. Riguardava i rischi strutturali che emergono quando strumenti potenti vengono costruiti senza adeguate salvaguardie a ogni livello.
Elon Musk ha ripetutamente sollevato punti simili, descrivendo lo sviluppo incontrollato dell'AI come uno dei più gravi rischi civilizzazionali che affrontiamo. Qualunque sia il Suo punto di vista sulla scala di quegli avvertimenti, la logica sottostante si applica direttamente all'avvelenamento dei modelli: i sistemi potenti costruiti su fondamenta corrotte creano danni cumulativi che diventano più difficili da invertire nel tempo.
Questi non sono argomenti per rallentare l'AI. Sono argomenti per costruirla correttamente. E "costruirla correttamente" include assolutamente trattare la Sua pipeline di addestramento come una superficie di sicurezza degna di protezione.

Comprendere cos'è l'avvelenamento dei modelli AI: La conclusione
Cos'è l'avvelenamento dei modelli AI? È una delle minacce più silenziose e sottovalutate nell'AI aziendale di oggi. Non attiva allarmi. Non appare nei risultati dei test di penetrazione. Si nasconde dentro la cosa stessa di cui le organizzazioni si fidano di più: i dati da cui i loro modelli hanno imparato.
Man mano che l'AI viene incorporata sempre più profondamente nelle decisioni aziendali, nei sistemi finanziari, negli strumenti sanitari e nell'infrastruttura di sicurezza, gli stake associati all'integrità del modello continuano a crescere. Un modello avvelenato non è solo un problema tecnico. È una responsabilità, un rischio di conformità e, a seconda del contesto di implementazione, un problema di sicurezza.
La buona notizia è che le difese esistono e stanno migliorando. Strumenti di provenienza dei dati, monitoraggio comportamentale, test adversariali e controlli a livello di architettura contribuiscono tutti a una postura più forte. Ma quelle difese funzionano solo quando le organizzazioni accettano prima che il rischio sia reale.
Se desidera approfondire la protezione dei Suoi sistemi AI, la guida completa al rischio e all'architettura AI è un solido passo successivo per i team in qualsiasi fase del loro percorso di sicurezza AI.
Domande frequenti
Quali sono gli esempi di avvelenamento AI?
Gli esempi includono l'iniezione di spam etichettato erroneamente nei filtri email, l'inserimento di immagini corrotte nei dataset di riconoscimento facciale e l'incorporamento di trigger nascosti nei dati di addestramento dei veicoli autonomi. Qualsiasi sistema che si basa su dati di addestramento esterni o crowdsourced è un candidato per questo tipo di attacco.
Cos'è la tossicità nei modelli AI?
La tossicità nell'AI si riferisce a output dannosi, distorti, offensivi o pericolosi, spesso causati dall'addestramento su dati non filtrati o deliberatamente corrotti. Si sovrappone all'avvelenamento quando il comportamento tossico è intenzionalmente progettato piuttosto che un sottoprodotto accidentale di dati disordinati.
Cos'è l'avvelenamento dei modelli?
L'avvelenamento dei modelli è quando un aggressore corrompe i dati di addestramento o il processo di un sistema AI per farlo comportare in modi dannosi o errati. Può mirare all'accuratezza della classificazione, introdurre backdoor o causare specifiche modalità di guasto che si attivano in condizioni controllate.
Qual era l'avvertimento di Stephen Hawking sull'AI?
Hawking ha avvertito che l'AI potrebbe essere il migliore o il peggiore sviluppo nella storia umana, dipendendo dal fatto se viene sviluppata con adeguate salvaguardie. Ha sottolineato che i rischi si compongono quando i sistemi potenti vengono costruiti senza adeguati controlli a ogni livello.
Cosa ha detto Elon Musk sui pericoli dell'AI?
Musk ha definito lo sviluppo incontrollato dell'AI uno dei più gravi rischi per la civiltà, spingendo per una supervisione normativa e standard di sviluppo responsabili. La sua preoccupazione si concentra sulla natura cumulativa dei rischi AI quando i problemi fondazionali non vengono controllati.