
Apakah itu peracunan model AI? Ia merupakan satu serangan siber di mana pihak berniat jahat dengan sengaja merosakkan data atau proses latihan sesebuah sistem AI untuk memanipulasi cara ia berkelakuan. Hal ini menyebabkan model tersebut menghasilkan output yang salah, berat sebelah, atau berniat jahat, selalunya tanpa sebarang kesedaran sehingga kerosakan sebenar sudah berlaku.
Kebanyakan orang menganggap bahawa ancaman AI datang dari luar, seperti penggodam yang cuba menceroboh sesebuah sistem. Namun dengan peracunan model, serangan berlaku secara senyap-senyap, tersembunyi dalam data yang dipelajari oleh AI. Ketika model itu telah digunakan dan menyebabkan kerosakan, mengesan sumber masalah tersebut menjadi sangat sukar. Panduan ini menerangkan dengan tepat bagaimana ini berfungsi, mengapa ia penting bagi perniagaan tuan/puan, dan apakah yang dilakukan oleh organisasi yang paling bijak untuk melindungi diri mereka.
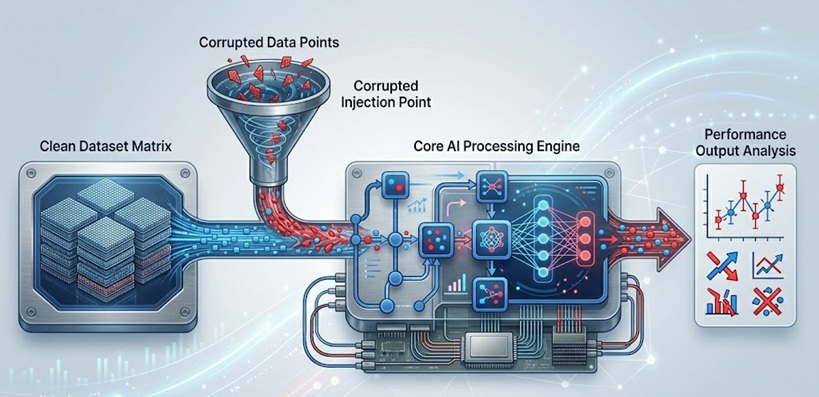
Mengapa Peracunan Model AI Lebih Berbahaya daripada Bunyinya
Anggaplah sebuah model AI itu seperti seorang pelajar. Berikan pelajar itu maklumat yang tepat dan berkualiti tinggi selama bertahun-tahun, dan mereka akan menjadi orang yang boleh dipercayai dan diharapkan. Tetapi bagaimana jika seseorang menyelitkan buku teks yang mengelirukan ke dalam bilik darjah sejak hari pertama? Pada masa tamat pengajian, pandangan dunia pelajar itu sudah terpesong, dan mereka sendiri pun tidak menyedarinya.
Begitulah cara sebenar peracunan model berlaku. Penyerang tidak perlu menceroboh sistem yang sedang beroperasi. Mereka hanya memerlukan akses kepada saluran latihan, set data, atau kadangkala gelung maklum balas yang digunakan oleh model untuk terus meningkatkan diri. Setelah data yang diracuni dicampurkan, model akan mempelajarinya sama seperti ia mempelajari segala-galanya yang lain.
Apa yang menjadikan ancaman ini sangat menggusarkan adalah betapa tidak kelihatannya ia. Model terus berfungsi. Ia masih memberikan jawapan. Ia mungkin juga mencapai markah yang baik dalam penanda aras yang standard. Kerosakan ini tidak ketara, ia bersifat pembedahan yang halus. Dan dalam persekitaran yang berisiko tinggi seperti penjagaan kesihatan, kewangan, atau sistem berautonomi, sebuah model yang dirosakkan secara halus boleh menyebabkan kemudaratan yang sangat besar sebelum sesiapa pun menyedarinya.
Memahami risiko keselamatan AI yang dihadapi oleh organisasi tuan/puan bermula dengan mengakui bahawa ancaman bukan sentiasa berbentuk pencerobohan yang dramatik. Kadangkala ia adalah sebuah set data yang diracuni secara senyap-senyap di asas segala-galanya.
Bagaimana Peracunan Model Sebenarnya Berfungsi
Terdapat beberapa cara berbeza yang boleh digunakan oleh penyerang untuk melaksanakan jenis serangan ini, dan setiap satu menyasarkan bahagian saluran AI yang berbeza.
Peracunan Data
Inilah kaedah yang paling biasa. Penyerang menyuntik contoh yang dirosakkan atau dimanipulasi ke dalam set data latihan. Jika AI sedang belajar mengesan e-mel spam, penyerang mungkin menambah beribu-ribu mesej spam yang dilabel sebagai sah. Lama-kelamaan, model akan belajar untuk mempercayai apa yang sepatutnya ditolak.
Peracunan data sangat mudah dilaksanakan apabila sistem AI bergantung kepada data sumber ramai, kandungan web yang dikikis, atau set data pihak ketiga. Kebanyakan organisasi mempunyai pandangan yang terhad tentang sumber sebenar data latihan mereka, yang membuka pintu lebar-lebar.
Serangan Pintu Belakang
Serangan pintu belakang adalah lebih canggih. Di sini, penyerang bukan sekadar merosakkan kelakuan umum model. Mereka menanam pencetus tersembunyi, iaitu corak input tertentu yang menyebabkan model berkelakuan dengan cara tertentu apabila diarahkan.
Sebagai contoh, sebuah model pengecaman imej mungkin berfungsi dengan sempurna pada setiap foto biasa. Tetapi jika penyerang menambah tera air yang kecil dan khusus pada sesebuah imej, model itu tiba-tiba akan mengelaskannya dengan salah. Pencetus tersebut tidak kelihatan kepada pengguna tetapi boleh dikawal sepenuhnya oleh penyerang.
Serangan Penalaan Halus Model
Dalam kes di mana organisasi menggunakan model yang telah dilatih dahulu daripada sumber pihak ketiga dan kemudian melakukan penalaan halus pada data mereka sendiri, peracunan mungkin sudah tertanam sebelum mereka menyentuhnya. Ini adalah kebimbangan yang semakin meningkat memandangkan semakin banyak perniagaan menggunakan asas AI sumber terbuka atau yang dilesenkan secara komersial tanpa mengaudit kandungan yang sedia ada di dalamnya.

Jenis-Jenis Peracunan Model AI: Rujukan Pantas
| Jenis Serangan | Kaedah | Sasaran Utama |
|---|---|---|
| Peracunan Data | Menyuntik contoh latihan yang palsu | Set data latihan |
| Serangan Pintu Belakang | Menanam pencetus tersembunyi dalam model | Peringkat inferens |
| Pembalikan Label | Melabelkan data dengan salah untuk mengelirukan pengelasan | Model pembelajaran terselia |
| Serangan Penalaan Halus Model | Menyerahkan pemberat model yang sudah diracuni | Saluran pembelajaran pindahan |
| Serangan Kecerunan | Memanipulasi kemas kini model semasa latihan | Sistem pembelajaran bersekutu |
Senario Dunia Sebenar yang Menjadi Serius
Ia membantu untuk melihat bagaimana ini berlaku dalam amalan. Berikut adalah beberapa contoh yang menggambarkan betapa luasnya impak yang boleh berlaku.
Alat Diagnosis Perubatan: Sebuah AI yang dilatih untuk mengesan tumor dalam imbasan radiologi boleh diracuni untuk secara konsisten terlepas pandang jenis pertumbuhan tertentu. Pesakit menerima laporan kesihatan yang bersih. Model tidak pernah menandakan masalah tersebut. Kerosakannya tidak kelihatan dan berpotensi membawa maut.
Pengesanan Penipuan Kewangan: Sebuah model pengesanan penipuan yang telah diracuni mungkin belajar untuk membiarkan corak transaksi tertentu melepasi, pada dasarnya mencipta pintu belakang untuk jenayah kewangan dilakukan tanpa dikesan dalam skala besar.
Penyederhanaan Kandungan: Platform sosial yang menggunakan AI untuk menapis kandungan berbahaya boleh dimanipulasi supaya membenarkan kategori penyalahgunaan tertentu lepas secara konsisten, sambil kelihatan berfungsi secara normal di permukaan.
Kenderaan Berautonomi: Sebuah sistem pemanduan sendiri yang diracuni semasa latihan mungkin gagal mengenali tanda jalan tertentu dalam keadaan pencahayaan tertentu. Sebuah pintu belakang secara teori boleh dikaitkan dengan pencetus visual tersuai yang menyebabkan kelakuan berbahaya atas permintaan.
Ini bukanlah kes terburuk hipotesis. Apabila AI semakin tertanam dalam lebih banyak sistem yang kritikal, permukaan serangan terus berkembang. Perniagaan yang memahami bagaimana ciri-ciri AI dibina dan digunakan berada dalam kedudukan yang lebih baik untuk mengenal pasti di mana risiko peracunan wujud dalam tindanan mereka sendiri.
Perkara yang Perlu Diketahui
- Peracunan model bukan sama dengan serangan pencerobohan. Serangan pencerobohan berlaku pada masa inferens dengan memanipulasi input. Peracunan berlaku semasa latihan, menjadikannya jauh lebih sukar untuk dikesan selepas itu.
- Model sumber terbuka membawa risiko yang diwarisi. Memuat turun dan menggunakan model yang telah dilatih dahulu tanpa mengaudit sejarah latihannya bermakna menerima apa sahaja yang telah tertanam di dalamnya.
- Pembelajaran bersekutu memperkenalkan permukaan serangan baharu. Apabila model dilatih merentas peranti atau organisasi yang teragih, sumbangan data setiap peserta adalah titik masuk yang berpotensi untuk peracunan.
- Model yang diracuni boleh lulus ujian yang standard. Penyerang sering mereka bentuk serangan peracunan untuk mengekalkan ketepatan keseluruhan pada set data penanda aras, jadi ujian rutin tidak akan mengesan masalah itu.
- Pendedahan kawal selia adalah nyata. Dalam industri yang dikawal selia, menggunakan model yang menghasilkan output yang diskriminasi atau salah, walaupun tanpa disedari, boleh mengakibatkan akibat pematuhan yang serius.
- Asal-usul data lebih penting daripada apa yang difikirkan oleh kebanyakan pasukan. Mengetahui dari mana datangnya setiap kepingan data latihan, dan dapat mengesahkannya, adalah salah satu pertahanan yang paling kurang digunakan terhadap kelas serangan ini.
Bagaimana Organisasi Melawan Balik
Mempertahankan diri terhadap apakah itu peracunan model AI memerlukan pendekatan berlapis. Tiada penyelesaian tunggal yang dapat menghentikan setiap varian serangan ini. Tetapi organisasi yang menganggap keselamatan AI dengan serius sedang membina tabiat dan sistem yang menjadikan peracunan jauh lebih sukar dilakukan dan lebih mudah dikesan.
Pengauditan Data dan Penjejakan Asal-usul: Titik permulaan yang paling berkesan adalah mengetahui data tuan/puan. Pasukan haruslah mendokumenkan dari mana datangnya data latihan, siapa yang menyumbang, bagaimana ia dilabel, dan sama ada terdapat sebarang anomali yang diperkenalkan sepanjang perjalanan. Alat yang menandakan nilai luar statistik dalam set data boleh mengesan kelompok yang diracuni sebelum ia mencapai saluran latihan.
Pemantauan Kelakuan Model: Setelah model digunakan, memantau outputnya untuk corak yang tidak dijangka adalah penting. Jika sebuah model pengesanan penipuan tiba-tiba mula meluluskan satu kategori transaksi yang sebelumnya ditandakan secara konsisten, perkara itu wajar disiasat. Penyimpangan kelakuan boleh menjadi gejala peracunan yang terlepas semasa latihan.
Ujian Pencerobohan: Menjalankan ujian tekanan yang sengaja terhadap model yang telah digunakan, termasuk senario yang direka untuk mendedahkan pencetus tersembunyi, membantu mendedahkan serangan pintu belakang sebelum musuh dunia sebenar menemuinya terlebih dahulu.
Audit Pihak Ketiga: Untuk organisasi yang menggunakan model yang diperoleh secara luaran, audit bebas terhadap seni bina dan sejarah latihan model menyediakan lapisan keyakinan tambahan. Ini sangat penting apabila model tersebut digunakan dalam aplikasi yang berisiko tinggi.
Memahami bagaimana seni bina AI mempengaruhi kerentanan membantu pasukan teknikal membuat keputusan yang lebih baik tentang di mana harus menambah kawalan dan bagaimana menyusun pertahanan terhadap serangan rantaian bekalan.
Apa yang Menjadikan Sesetengah Sistem AI Lebih Terdedah
Tidak setiap sistem AI terdedah secara sama rata. Beberapa faktor cenderung meningkatkan kerentanan sesebuah model kepada peracunan.
| Faktor Risiko | Mengapa Ia Meningkatkan Kerentanan |
|---|---|
| Pergantungan kepada data pihak ketiga | Kurang kawalan ke atas apa yang masuk ke dalam saluran latihan |
| Set data yang besar dan tidak diaudit | Lebih sukar untuk mengesan sampel yang dirosakkan secara individu pada skala besar |
| Penyediaan pembelajaran berterusan | Pengambilan data yang berterusan bermakna pendedahan yang berterusan |
| Pemantauan terhad selepas penggunaan | Kelakuan yang diracuni mungkin tidak disedari selama berbulan-bulan |
| Penggunaan asas sumber terbuka yang telah dilatih dahulu | Peracunan yang diwarisi daripada sumber huluan |
Apa yang Diberitahu oleh Perbualan yang Lebih Besar
Kebimbangan mengenai peracunan model AI tidak wujud dalam ruang kosong. Ia sesuai dengan perbualan yang jauh lebih besar yang telah dibangkitkan oleh pemikir yang serius selama bertahun-tahun.
Stephen Hawking pernah memberi amaran bahawa AI boleh menjadi perkara terbaik atau terburuk yang berlaku kepada umat manusia, bergantung sepenuhnya kepada sama ada kita membangunkannya dengan bertanggungjawab. Kebimbangan beliau bukan sahaja mengenai sistem super pintar yang menyimpang. Ia mengenai risiko struktur yang muncul apabila alat yang berkuasa dibina tanpa perlindungan yang mencukupi pada setiap lapisan.
Elon Musk telah berulang kali membuat penyataan yang sama, menggambarkan pembangunan AI yang tidak terkawal sebagai salah satu risiko peradaban yang paling serius yang kita hadapi. Tidak kira apa pun pandangan tuan/puan tentang skala amaran tersebut, logik yang mendasari diterapkan secara langsung kepada peracunan model: sistem yang berkuasa yang dibina di atas asas yang dirosakkan menghasilkan kemudaratan yang berganda yang menjadi lebih sukar untuk diterbalikkan dari semasa ke semasa.
Ini bukanlah hujah untuk memperlahankan AI. Ia adalah hujah untuk membinanya dengan betul. Dan "membinanya dengan betul" sememangnya termasuk menganggap saluran latihan tuan/puan sebagai permukaan keselamatan yang patut dilindungi.

Memahami Apakah Itu Peracunan Model AI: Kesimpulan
Apakah itu peracunan model AI? Ia adalah salah satu ancaman yang paling senyap dan paling kurang dihargai dalam AI perusahaan hari ini. Ia tidak mencetuskan penggera. Ia tidak muncul dalam keputusan ujian pencerobohan. Ia bersembunyi di dalam perkara yang paling dipercayai oleh organisasi: data yang dipelajari oleh model mereka.
Apabila AI semakin tertanam dalam keputusan perniagaan, sistem kewangan, alat penjagaan kesihatan, dan infrastruktur keselamatan, taruhan yang berkait dengan integriti model terus meningkat. Sebuah model yang diracuni bukan sahaja merupakan masalah teknikal. Ia adalah satu liabiliti, satu risiko pematuhan, dan bergantung kepada konteks penggunaan, satu isu keselamatan.
Berita baiknya adalah pertahanan wujud dan sedang bertambah baik. Alat asal-usul data, pemantauan kelakuan, ujian pencerobohan, dan kawalan peringkat seni bina semuanya menyumbang kepada postur yang lebih kukuh. Tetapi pertahanan itu hanya berfungsi apabila organisasi terlebih dahulu menerima bahawa risiko itu adalah nyata.
Jika tuan/puan ingin mendalami perlindungan sistem AI tuan/puan, panduan penuh kepada risiko AI dan seni bina adalah langkah seterusnya yang kukuh bagi pasukan pada mana-mana peringkat perjalanan keselamatan AI mereka.
Soalan Lazim
Apakah contoh peracunan AI?
Contoh-contohnya termasuk menyuntik spam yang dilabel salah ke dalam penapis e-mel, menanam imej yang dirosakkan dalam set data pengecaman wajah, dan menanam pencetus tersembunyi dalam data latihan kenderaan berautonomi. Mana-mana sistem yang bergantung kepada data latihan luaran atau bersumberkan ramai merupakan calon untuk jenis serangan ini.
Apakah ketoksikan dalam model AI?
Ketoksikan dalam AI merujuk kepada output yang berbahaya, berat sebelah, menyinggung, atau merbahaya, selalunya disebabkan oleh latihan pada data yang tidak ditapis atau dirosakkan dengan sengaja. Ia bertindih dengan peracunan apabila kelakuan toksik tersebut sengaja dijuruterai dan bukannya hasil sampingan yang tidak disengajakan daripada data yang tidak teratur.
Apakah peracunan model?
Peracunan model adalah apabila seorang penyerang merosakkan data atau proses latihan sesebuah sistem AI untuk membuatnya berkelakuan dengan cara yang berbahaya atau salah. Ia boleh menyasarkan ketepatan pengelasan, memperkenalkan pintu belakang, atau menyebabkan mod kegagalan tertentu yang aktif di bawah keadaan yang terkawal.
Apakah amaran Stephen Hawking mengenai AI?
Hawking memberi amaran bahawa AI boleh menjadi perkembangan terbaik atau terburuk dalam sejarah manusia, bergantung kepada sama ada ia dibangunkan dengan perlindungan yang sewajarnya. Beliau menekankan bahawa risiko berganda apabila sistem yang berkuasa dibina tanpa kawalan yang mencukupi pada setiap lapisan.
Apakah yang dikatakan oleh Elon Musk tentang bahaya AI?
Musk telah menyifatkan pembangunan AI yang tidak terkawal sebagai salah satu risiko yang paling serius kepada peradaban, mendorong pengawasan kawal selia dan standard pembangunan yang bertanggungjawab. Kebimbangan beliau berkisar pada sifat berganda risiko AI apabila masalah asas tidak dipantau.