
Ano ang AI model poisoning? Ito ay isang cyberattack kung saan sinasadya ng mga masasamang aktor na sirain ang data o training process ng isang AI system para manipulahin kung paano ito kumikilos. Dahil dito, gumagawa ang model ng mali, biased, o malisyosong outputs, kadalasang walang nakakapansin hangga't may tunay nang naidulot na pinsala.
Karamihan sa mga tao ay nag-aakala na ang AI threats ay galing sa labas, tulad ng mga hackers na sinusubukang pasukin ang isang system. Pero sa model poisoning, tahimik na nangyayari ang attack, nakabaon sa loob ng data na pinagaaralan ng AI. Sa oras na deployed na ang model at gumagawa na ng pinsala, sobrang hirap nang i-trace ang pinagmulan ng problema. Bibreak down ng guide na ito kung paano eksaktong gumagana ito, bakit mahalaga ito para sa iyong negosyo, at ano ang ginagawa ng pinakamga matalinong organisasyon para protektahan ang sarili nila.
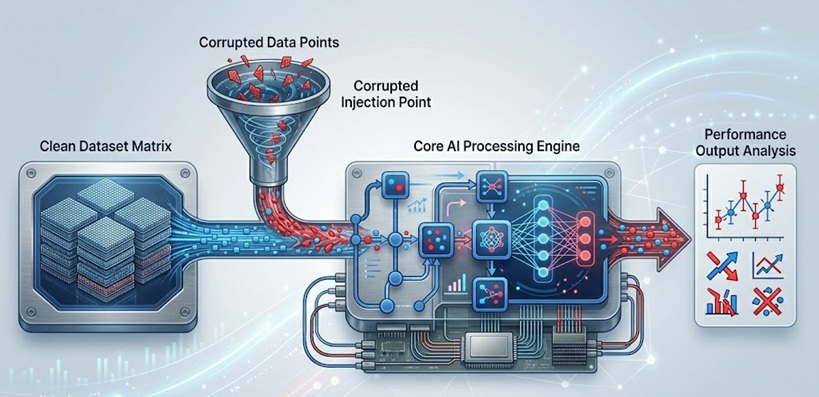
Bakit Mas Mapanganib ang AI Model Poisoning Kaysa sa Tunog Nito
Isipin ang AI model bilang isang estudyante. Bigyan ang estudyanteng iyon ng accurate, high-quality na impormasyon sa loob ng mga taon, at magiging reliable at trustworthy sila. Pero paano kung may nagsuksok ng misleading na mga textbooks sa classroom mula day one? Sa graduation, baluktot na ang pananaw ng estudyante sa mundo, at hindi nila ito alam.
Ganyan eksakto gumagana ang model poisoning. Hindi kailangan ng mga attackers na pasukin ang isang live system. Kailangan lang nila ng access sa training pipeline, sa dataset, o minsan kahit sa feedback loop na ginagamit ng model para patuloy na mag-improve. Kapag nahalo na ang poisoned data, natutunan ng model mula dito tulad ng pagkatuto nito sa lahat ng iba pa.
Ang nagpapatindi sa banta na ito ay kung gaano ito ka-invisible. Patuloy ang model sa paggana. Nagbibigay pa rin ito ng mga sagot. Maaari pa nga itong magka-good score sa mga standard benchmarks. Hindi obvious ang corruption, surgical ito. At sa high-stakes environments tulad ng healthcare, finance, o autonomous systems, ang subtly corrupted model ay maaaring magdulot ng napakalaking pinsala bago may magtaas ng flag.
Ang pag-unawa sa AI security risks na hinaharap ng iyong organisasyon ay nagsisimula sa pagkilala na hindi laging dramatic breach ang threat. Minsan ito ay isang tahimik na poisoned dataset na nakaupo sa foundation ng lahat.
Paano Aktwal na Gumagana ang Model Poisoning
May ilang iba't ibang paraan kung paano maaaring i-execute ng mga attackers ang ganitong klaseng attack, at bawat isa ay nagta-target ng iba't ibang bahagi ng AI pipeline.
Data Poisoning
Ito ang pinakakaraniwang paraan. Nag-iinject ang attacker ng corrupted o manipulated examples sa training dataset. Kung natututo ang AI na mag-detect ng spam emails, maaaring magdagdag ang attacker ng libu-libong spam messages na nakalabel bilang legitimate. Sa paglipas ng panahon, natututo ang model na magtiwala sa dapat nitong tanggihan.
Ang data poisoning ay madali lang isagawa kapag ang AI systems ay nakadepende sa crowdsourced data, scraped web content, o third-party datasets. Karamihan sa mga organisasyon ay may limitadong visibility kung saan eksaktong galing ang kanilang training data, na nagbubukas ng pinto nang malawak.
Backdoor Attacks
Mas sopistikado ang backdoor attack. Dito, hindi lang sinisira ng attacker ang pangkalahatang behavior ng model. Nagtatanim sila ng hidden trigger, isang specific input pattern na nagiging dahilan para kumilos ang model sa isang tiyak na paraan sa command.
Halimbawa, maaaring perpektong gumana ang isang image recognition model sa bawat normal na photo. Pero kung magdagdag ang attacker ng maliit, specific na watermark sa isang image, bigla itong mag-misclassify. Hindi nakikita ng mga users ang trigger pero ganap na nakokontrol ng attacker.
Model Fine-Tuning Attacks
Sa mga kaso kung saan gumagamit ang mga organisasyon ng pre-trained models mula sa third-party sources at saka fine-tune sa sarili nilang data, baka naka-bake na ang poisoning bago pa man nila ito hawakan. Ito ay isang lumalagong concern habang mas maraming negosyo ang nag-aadopt ng open-source o commercially licensed AI foundations nang hindi ina-audit kung ano na ang nasa loob.

Mga Uri ng AI Model Poisoning: Isang Quick Reference
| Uri ng Attack | Paraan | Primary na Target |
|---|---|---|
| Data Poisoning | Pag-inject ng false training examples | Training datasets |
| Backdoor Attack | Pag-embed ng hidden triggers sa model | Inference stage |
| Label Flipping | Pag-mislabel ng data para malito ang classification | Supervised learning models |
| Model Fine-Tuning Attack | Pagdeliver ng pre-poisoned model weights | Transfer learning pipelines |
| Gradient Attack | Pagmamanipula ng model updates habang nagti-training | Federated learning systems |
Mga Real-World Scenario Kung Saan Nagiging Serious Ito
Nakakatulong na makita kung paano ito nangyayari sa praktika. Heto ang ilang mga halimbawa na nag-iillustrate kung gaano kalawak ang impact.
Medical Diagnosis Tools: Ang AI na trained para mag-detect ng tumors sa radiology scans ay maaaring i-poison para consistent na mami-miss ang isang specific na uri ng growth. Nakakatanggap ang mga pasyente ng clean bills of health. Hindi nilalagyan ng flag ng model ang problema. Invisible ang damage at potentially fatal.
Financial Fraud Detection: Ang fraud detection model na napoison ay maaaring matutunang papasahin ang ilang transaction patterns, essentially gumagawa ng backdoor para sa financial crimes para hindi ma-detect sa scale.
Content Moderation: Ang social platforms na gumagamit ng AI para mag-filter ng harmful content ay maaaring ma-manipulate para pumayagang dumaan ang ilang categories ng abuse nang consistent, samantalang nagmumukhang normal na gumagana sa surface.
Autonomous Vehicles: Ang self-driving system na napoison habang nagti-training ay maaaring hindi makilala ang isang specific na road sign sa ilang lighting conditions. Theoretically, maaaring i-tie ang backdoor sa custom visual trigger na nagdudulot ng dangerous behavior on demand.
Hindi ito hypothetical worst cases. Habang lumalapit ang AI sa mas maraming critical systems, patuloy na lumalawak ang attack surface. Mas nasa posisyon ang mga negosyong nakaka-unawa kung paano binubuo at i-deploy ang AI features para makilala kung saan nakatira ang poisoning risks sa sarili nilang stack.
Mga Bagay na Dapat Malaman
- Hindi pareho ang model poisoning sa adversarial attacks. Nangyayari ang adversarial attacks sa inference time sa pamamagitan ng pagma-manipulate ng inputs. Nangyayari ang poisoning habang nagti-training, kaya mas mahirap i-detect after the fact.
- May inherited risk ang open-source models. Ang pag-download at pag-deploy ng pre-trained model nang hindi inaaudit ang training history nito ay ibig sabihin tinatanggap mo ang kahit anumang naka-bake dito.
- Nag-iintroduce ng bagong attack surfaces ang federated learning. Kapag tina-train ang models sa distributed devices o organizations, ang data contribution ng bawat participant ay potential entry point para sa poisoning.
- Maaaring makapasa sa standard tests ang poisoned models. Madalas idina-design ng mga attackers ang poisoning attacks para mapreserve ang overall accuracy sa benchmark datasets, kaya hindi mahuhuli ng routine testing ang problema.
- Real ang regulatory exposure. Sa regulated industries, ang pag-deploy ng model na gumagawa ng discriminatory o incorrect outputs, kahit hindi sinasadya, ay maaaring magresulta sa serious compliance consequences.
- Mas mahalaga ang data provenance kaysa sa iniisip ng karamihan ng mga teams. Ang pag-alam kung saan galing ang bawat piraso ng training data, at ang kakayahang ma-verify ito, ay isa sa pinakamga underused defenses laban sa class na ito ng attack.
Paano Lumalaban ang mga Organisasyon
Ang pagdepensa laban sa kung ano ang AI model poisoning ay nangangailangan ng layered approach. Walang single solution na nakakapigil sa bawat variant ng attack na ito. Pero ang mga organisasyong sineseryoso ang AI security ay bumubuo ng habits at systems na ginagawang mas mahirap maisagawa ang poisoning at mas madaling mahuli.
Data Auditing at Provenance Tracking: Ang pinakaepektibong starting point ay alamin ang data mo. Dapat i-document ng mga teams kung saan galing ang training data, sino ang nag-contribute nito, paano ito nilabel, at kung may naintroduce na anomalies sa daan. Ang mga tools na nagfa-flag ng statistical outliers sa datasets ay maaaring makahuli ng poisoned batches bago pa man marating ang training pipeline.
Model Behavior Monitoring: Sa sandaling i-deploy ang isang model, critical na i-monitor ang outputs nito para sa mga unexpected patterns. Kung biglang nag-start na mag-approve ang fraud detection model ng isang category ng transaction na dati nilang consistent na nilalagyan ng flag, worth investigating yun. Ang behavioral drift ay maaaring symptom ng poisoning na nakalusot habang nagti-training.
Adversarial Testing: Ang pagrun ng deliberate stress tests laban sa deployed models, kasama ang mga scenarios na designed para mai-expose ang hidden triggers, ay tumutulong na mahanap ang backdoor attacks bago pa man mahanap ng real-world adversaries.
Third-Party Audits: Para sa mga organisasyong gumagamit ng externally sourced models, ang independent audits ng architecture at training history ng model ay nag-prprovide ng additional layer ng confidence. Lalong importante ito kapag papunta sa high-stakes applications ang mga modelong iyon.
Ang pag-unawa kung paano nakakaapekto ang AI architecture sa vulnerability ay tumutulong sa technical teams na gumawa ng mas magagandang decisions tungkol sa kung saan magdagdag ng controls at kung paano i-structure ang defenses laban sa supply chain attacks.
Ano ang Nagiging Dahilan na Mas Vulnerable ang Ilang AI Systems
Hindi lahat ng AI system ay parehong na-eexpose. Maraming factors ang may tendency na palakasin ang susceptibility ng model sa poisoning.
| Risk Factor | Bakit Pinapalakas Nito ang Vulnerability |
|---|---|
| Reliance sa third-party data | Mas konting control sa kung ano ang pumapasok sa training pipeline |
| Malalaking, hindi-naaudit na datasets | Mas mahirap mahuli ang individual corrupted samples sa scale |
| Continuous learning setups | Ang ongoing data ingestion ay ibig sabihin ay ongoing exposure |
| Limitadong monitoring post-deployment | Maaaring hindi mapansin ang poisoned behavior sa loob ng buwan |
| Paggamit ng pre-trained open-source foundations | Inherited poisoning mula sa upstream sources |
Ano ang Sinasabi sa Atin ng Mas Malaking Pag-uusap
Hindi nag-iisa sa vacuum ang concern tungkol sa AI model poisoning. Nakapasok ito sa mas malaking conversation na ilang taon nang ina-raise ng mga seryosong thinkers.
Famous na nagbabala si Stephen Hawking na maaaring maging best o worst na nangyari sa sangkatauhan ang AI, depende kung sino-develop natin ito nang may responsibility. Hindi lang concern niya ang superintelligent systems na nag-going rogue. Tungkol ito sa structural risks na lumalabas kapag ang powerful tools ay binubuo nang walang adequate safeguards sa bawat layer.
Repeatedly na ginagawa rin ni Elon Musk ang mga ganito ring points, dinedescribe ang uncontrolled AI development bilang isa sa pinakamga seryosong civilizational risks na kinakaharap natin. Anuman ang view mo sa scale ng mga warnings na iyon, ang underlying logic ay direkta nang applies sa model poisoning: ang powerful systems na binuo sa corrupted foundations ay gumagawa ng compounding harm na mas nagiging mahirap i-reverse over time.
Hindi ito mga argumento para slow down ang AI. Mga argumento ito para itayo ito nang tama. At ang "building it right" ay absolutely includes ang pag-treat sa training pipeline mo bilang security surface na worth protecting.

Pag-unawa sa Kung Ano ang AI Model Poisoning: Ang Bottom Line
Ano ang AI model poisoning? Isa ito sa pinakamga tahimik, pinakamga underappreciated threats sa enterprise AI ngayon. Hindi ito nag-trigger ng alarms. Hindi ito nagpapakita sa penetration test results. Nagtatago ito sa loob ng mismong bagay na pinagkakatiwalaan ng mga organisasyon: ang data kung saan natuto ang kanilang models.
Habang mas lumalalim ang pagka-embed ng AI sa business decisions, financial systems, healthcare tools, at security infrastructure, patuloy na tumataas ang stakes na nakakabit sa model integrity. Ang poisoned model ay hindi lang technical problem. Liability ito, compliance risk, at depende sa deployment context, safety issue.
Ang magandang balita ay exist ang mga defenses at nag-iimprove. Ang data provenance tools, behavioral monitoring, adversarial testing, at architecture-level controls ay lahat nag-coccontribute sa stronger posture. Pero gumagana lang ang mga defenses na iyon kapag inaccept muna ng mga organisasyon na real ang risk.
Kung gusto mong mag-go deeper sa pagprotekta sa iyong AI systems, ang full guide to AI risk and architecture ay solid next step para sa mga teams sa kahit anong stage ng kanilang AI security journey.
Mga Madalas na Tanong
Ano ang mga halimbawa ng AI poisoning?
Kasama sa mga halimbawa ang pag-inject ng mislabeled spam sa email filters, pagtatanim ng corrupted images sa facial recognition datasets, at pag-embed ng hidden triggers sa autonomous vehicle training data. Anumang system na nakadepende sa external o crowdsourced training data ay candidate para sa ganitong klaseng attack.
Ano ang toxicity sa AI models?
Ang toxicity sa AI ay tumutukoy sa outputs na mapaminsala, biased, offensive, o mapanganib, na kadalasang dulot ng pag-train sa unfiltered o sinasadya na corrupted data. Nag-ooverlap ito sa poisoning kapag ang toxic behavior ay intentionally engineered sa halip na accidental by-product ng messy data.
Ano ang model poisoning?
Ang model poisoning ay kapag sinisira ng attacker ang training data o process ng isang AI system para magkilos ito sa harmful o incorrect na paraan. Maaari nitong i-target ang classification accuracy, mag-introduce ng backdoors, o magdulot ng specific failure modes na nag-aactivate sa controlled conditions.
Ano ang warning ni Stephen Hawking tungkol sa AI?
Nagbabala si Hawking na maaaring maging best o worst development ang AI sa human history, depende kung idi-develop ito nang may proper safeguards. Bigyang-diin niya na nag-coccompound ang risks kapag ang powerful systems ay binubuo nang walang adequate controls sa bawat layer.
Ano ang sinabi ni Elon Musk tungkol sa mga danger ng AI?
Tinawag ni Musk ang uncontrolled AI development bilang isa sa pinakamga seryosong risks sa civilization, nagpu-push para sa regulatory oversight at responsible development standards. Ang concern niya ay centered sa compounding nature ng AI risks kapag hindi nako-check ang foundational problems.