
RAG AI ಎಂದರೇನು? Retrieval-Augmented Generation ಎಂಬುದು large language modelಅನ್ನು ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ರಚಿಸುವ ಕ್ಷಣದಲ್ಲಿ ಬಾಹ್ಯ ಜ್ಞಾನ ಮೂಲಕ್ಕೆ ಸಂಪರ್ಕಿಸುವ ತಂತ್ರವಾಗಿದೆ, ಇದು ತರಬೇತಿಯ ಸಮಯದಲ್ಲಿ ಕಲಿತದ್ದನ್ನು ಮಾತ್ರ ಅವಲಂಬಿಸುವ ಬದಲು ಪ್ರಸ್ತುತ, ನಿರ್ದಿಷ್ಟ ಮತ್ತು ಪರಿಶೀಲನಾರ್ಹ ಮಾಹಿತಿಯನ್ನು ಸೆಳೆದುಕೊಳ್ಳಲು ಮಾದರಿಗೆ ಅವಕಾಶ ನೀಡುತ್ತದೆ. ಪರಿಣಾಮವಾಗಿ ಸಾಮಾನ್ಯೀಕರಿಸಿದ ಅಂದಾಜುಗಳಿಗಿಂತ ನಿಜವಾದ ಡೇಟಾದೊಂದಿಗೆ ಪ್ರಶ್ನೆಗಳಿಗೆ ಉತ್ತರಿಸುವ AI ವ್ಯವಸ್ಥೆ ಸಿಗುತ್ತದೆ.
ನೀವು ಎಂದಾದರೂ ಸ್ಟ್ಯಾಂಡರ್ಡ್ AI ಸಹಾಯಕರಿಗೆ ನಿಮ್ಮ ಕಂಪನಿಯ ಆಂತರಿಕ ಪ್ರಕ್ರಿಯೆಗಳ ಬಗ್ಗೆ ಪ್ರಶ್ನೆ ಕೇಳಿ, ಸಮಂಜಸವಾಗಿ ತೋರಿದರೂ ಸಂಪೂರ್ಣವಾಗಿ ಸೃಷ್ಟಿಸಿದ ಉತ್ತರವನ್ನು ಪಡೆದಿದ್ದರೆ, RAG ಪರಿಹರಿಸಲು ವಿನ್ಯಾಸಗೊಳಿಸಲಾದ ಮುಖ್ಯ ಮಿತಿಯನ್ನು ನೀವು ಅನುಭವಿಸಿದ್ದೀರಿ. ಭಾಷಾ ಮಾದರಿಗಳನ್ನು ನಿರ್ದಿಷ್ಟ ಸಮಯದವರೆಗಿನ ಡೇಟಾದ ಮೇಲೆ ತರಬೇತಿ ನೀಡಲಾಗಿದೆ. ನಿಮ್ಮ ಸ್ವಂತ ದಸ್ತಾವೇಜು, ನಿಮ್ಮ ಪ್ರಸ್ತುತ ದಾಸ್ತಾನು, ನಿಮ್ಮ ಇತ್ತೀಚಿನ ನೀತಿಗಳು ಅಥವಾ ಅವುಗಳ ತರಬೇತಿ ಕಟ್ಆಫ್ ನಂತರ ಸಂಭವಿಸಿದ ಯಾವುದರ ಬಗ್ಗೆಯೂ ಅವಕ್ಕೆ ಗೊತ್ತಿಲ್ಲ. ಚೆನ್ನಾಗಿ ಸಿದ್ಧಗೊಂಡ ವಿಶ್ಲೇಷಕನು ಸಂಪೂರ್ಣವಾಗಿ ನೆನಪಿನಿಂದ ಕೆಲಸ ಮಾಡುವ ಬದಲು ಸಲಹೆ ನೀಡುವ ಮುನ್ನ ಮೂಲ ದಾಖಲೆಗಳನ್ನು ಸಮಾಲೋಚಿಸುವ ರೀತಿಯಲ್ಲಿ, RAG ಮಾದರಿಗೆ ಉತ್ತರಿಸುವ ಮುನ್ನ ವಿಷಯಗಳನ್ನು ನೋಡಲು ಒಂದು ಯಂತ್ರೋಪಾಯವನ್ನು ನೀಡುವ ಮೂಲಕ ಆ ಮೂಲಭೂತ ಮಿತಿಯನ್ನು ಬದಲಾಯಿಸುತ್ತದೆ. ನಿಖರತೆ ಮತ್ತು ನಿರ್ದಿಷ್ಟತೆ ಮುಖ್ಯವಾಗಿರುವ ಸನ್ನಿವೇಶಗಳಲ್ಲಿ AI ನಿಯೋಜಿಸುವ ವ್ಯವಹಾರಗಳಿಗೆ, RAG AI ಎಂದರೇನು ಮತ್ತು ಅದು ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು ತಾಂತ್ರಿಕ ಸೂಕ್ಷ್ಮತೆಯಲ್ಲ. ಇದು ನಿಜವಾಗಿ ಸಹಾಯ ಮಾಡುವ AI ಮತ್ತು ವಿಶ್ವಾಸದಿಂದ ಸಮಂಜಸವಾದ ಅಸಂಬದ್ಧತೆಯನ್ನು ಉತ್ಪಾದಿಸುವ AIಯ ನಡುವಿನ ವ್ಯತ್ಯಾಸವಾಗಿದೆ.

ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಭಾಷಾ ಮಾದರಿಗಳಿಗೆ ಮೂಲಭೂತ ಜ್ಞಾನ ಸಮಸ್ಯೆ ಇರುವುದೇಕೆ
ತರಬೇತಿ ಕಟ್ಆಫ್ ಮಿತಿ
ಇಂದು ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಪ್ರತಿಯೊಂದು large language modelಅನ್ನೂ ನಿರ್ದಿಷ್ಟ ಅಂತ್ಯ ದಿನಾಂಕದ ಡೇಟಾಸೆಟ್ನಲ್ಲಿ ತರಬೇತಿ ನೀಡಲಾಗಿದೆ. ಆ ದಿನಾಂಕದ ನಂತರ ಸಂಭವಿಸಿದ ಎಲ್ಲವೂ, ಪ್ರತಿ ನೀತಿ ಬದಲಾವಣೆ, ಪ್ರತಿ ಉತ್ಪನ್ನ ನವೀಕರಣ, ಪ್ರತಿ ನಿಯಂತ್ರಕ ಬೆಳವಣಿಗೆ, ಮಾದರಿಯನ್ನು ತರಬೇತಿ ನೀಡಿದ ನಂತರ ಸೃಷ್ಟಿಸಿದ ಪ್ರತಿ ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನದ ತುಣುಕು, ಅದಕ್ಕೆ ಗೋಚರಿಸುವುದಿಲ್ಲ. ಸಾಮಾನ್ಯ ಜ್ಞಾನ ಕಾರ್ಯಗಳಿಗೆ ಈ ಮಿತಿಯನ್ನು ನಿಭಾಯಿಸಬಹುದು, ಏಕೆಂದರೆ ಮೂಲಭೂತ ಜ್ಞಾನ ನಿಧಾನವಾಗಿ ಬದಲಾಗುತ್ತದೆ. ಪ್ರಸ್ತುತ, ನಿರ್ದಿಷ್ಟ ಮಾಹಿತಿಯಲ್ಲಿ ನಿಖರತೆಯೇ ಸಂಪೂರ್ಣ ಗುರಿಯಾಗಿರುವ ವ್ಯವಹಾರ ಅನ್ವಯಿಕೆಗಳಿಗೆ, ಇದು ಗಂಭೀರ ಕಾರ್ಯಾಚರಣಾ ಸಮಸ್ಯೆಯಾಗಿದೆ.
ಎರಡನೇ ಮಿತಿಯು ವ್ಯಾಪ್ತಿ. ಸಾಧ್ಯವಾದಷ್ಟು ವಿಶಾಲ ಡೇಟಾಸೆಟ್ಗಳ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ ದೊಡ್ಡ ಭಾಷಾ ಮಾದರಿಗಳಿಗೂ, ಎಂದಿಗೂ ಅವುಗಳ ತರಬೇತಿ ಡೇಟಾದಲ್ಲಿಲ್ಲದ ಮಾಹಿತಿಯ ಬಗ್ಗೆ ಜ್ಞಾನವಿಲ್ಲ. ನಿಮ್ಮ ಕಂಪನಿಯ ಆಂತರಿಕ ಜ್ಞಾನ ಬೇಸ್, ನಿಮ್ಮ ಗ್ರಾಹಕ ಒಪ್ಪಂದಗಳು, ನಿಮ್ಮ ತಾಂತ್ರಿಕ ದಸ್ತಾವೇಜು, ನಿಮ್ಮ ಬೆಲೆ ರಚನೆಗಳು, ಮತ್ತು ನಿಮ್ಮ ಕಾರ್ಯಾಚರಣಾ ಕಾರ್ಯವಿಧಾನಗಳು ಯಾವುದೇ ಸಾರ್ವಜನಿಕ ತರಬೇತಿ ಡೇಟಾಸೆಟ್ನಲ್ಲಿ ಎಂದಿಗೂ ಇರಲಿಲ್ಲ ಎಂದು ಬಹುತೇಕ ಖಚಿತ. ಈ ವಿಷಯಗಳ ಬಗ್ಗೆ ಪ್ರಶ್ನೆಗಳಿಗೆ ಉತ್ತರಿಸುವ ಮಾದರಿಯು ತಿಳಿದಿರುವ ಮಾಹಿತಿಯನ್ನು ಮರುಪಡೆಯುತ್ತಿಲ್ಲ. ಅದು ತನ್ನ ತರಬೇತಿಯ ಮಾದರಿಗಳ ಆಧಾರದ ಮೇಲೆ ಉತ್ತರದಂತೆ ತೋರುವ ಪಠ್ಯವನ್ನು ಉತ್ಪಾದಿಸುತ್ತಿದೆ, ಈ ಪ್ರಕ್ರಿಯೆಯು ನಿರರ್ಗಳ, ಆತ್ಮವಿಶ್ವಾಸದ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ, ಇದು ನಿಜವಾದ ಸತ್ಯಗಳಿಗೆ ಯಾವುದೇ ಸಂಬಂಧವಿಲ್ಲದಿರಬಹುದು.
ಈ ಪ್ರಕ್ರಿಯೆಗೆ AI ಸಂಶೋಧನೆಯಲ್ಲಿ ಒಂದು ಹೆಸರಿದೆ: hallucination. ಇದು ಭಾಷಾ ಮಾದರಿಗಳು ತಪ್ಪಾದ ಮಾಹಿತಿಯನ್ನು ನಿಖರ ಮಾಹಿತಿಯಂತೆಯೇ ಆತ್ಮವಿಶ್ವಾಸದ ಧ್ವನಿಯಲ್ಲಿ ಪ್ರಸ್ತುತಪಡಿಸುವ ಪ್ರವೃತ್ತಿಯನ್ನು ವಿವರಿಸುತ್ತದೆ. ಸಾಂದರ್ಭಿಕ ಬಳಕೆ ಪ್ರಕರಣಗಳಿಗೆ, hallucination ಒಂದು ಅನಾನುಕೂಲತೆ. ಕಾನೂನು, ವೈದ್ಯಕೀಯ, ಹಣಕಾಸು ಅಥವಾ ಕಾರ್ಯಾಚರಣೆಯ ಸಂದರ್ಭಗಳಲ್ಲಿ ವ್ಯವಹಾರ ಅನ್ವಯಿಕೆಗಳಿಗೆ, ಇದು ಒಂದು ಹೊಣೆಗಾರಿಕೆ.
RAG ಎರಡೂ ಸಮಸ್ಯೆಗಳನ್ನು ಒಂದೇ ಬಾರಿಗೆ ಹೇಗೆ ಪರಿಹರಿಸುತ್ತದೆ
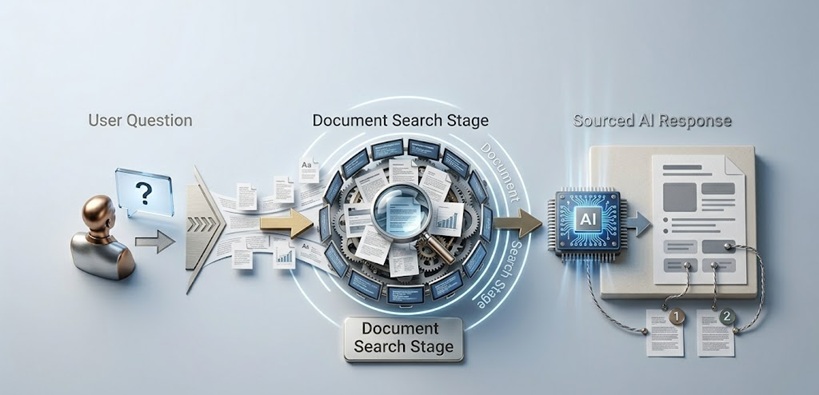
RAG AI ನಿರ್ದಿಷ್ಟವಾಗಿ ಏನನ್ನು ಪರಿಹರಿಸುತ್ತಿದೆ? ಇದು ಕಟ್ಆಫ್ ಸಮಸ್ಯೆ ಮತ್ತು ವ್ಯಾಪ್ತಿ ಸಮಸ್ಯೆ ಎರಡನ್ನೂ ಒಂದೇ ವಾಸ್ತುಶಿಲ್ಪೀಯ ಸೇರ್ಪಡೆಯೊಂದಿಗೆ ಪರಿಹರಿಸುತ್ತದೆ. ಕೇವಲ ತರಬೇತಿ ಡೇಟಾದಿಂದ ಉತ್ತರಿಸಲು ಮಾದರಿಯನ್ನು ಕೇಳುವ ಬದಲು, RAG ವ್ಯವಸ್ಥೆಗಳು ಪ್ರಶ್ನೆಯ ಸಮಯದಲ್ಲಿ ಬಾಹ್ಯ ಮೂಲದಿಂದ ಸಂಬಂಧಿತ ದಾಖಲೆಗಳು ಅಥವಾ ಡೇಟಾವನ್ನು ಮರುಪಡೆಯುತ್ತವೆ ಮತ್ತು ಆ ಮರುಪಡೆದ ವಿಷಯವನ್ನು ಮಾದರಿಯು ತನ್ನ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸಲು ಬಳಸುವ ಸಂದರ್ಭದಲ್ಲಿ ಸೇರಿಸುತ್ತವೆ.
ಮಾದರಿಯು ನಿಮ್ಮ ಮರುಪಾವತಿ ನೀತಿ ಏನು ಹೇಳುತ್ತದೆ ಎಂಬುದನ್ನು ಊಹಿಸುತ್ತಿಲ್ಲ. ಪ್ರತಿಕ್ರಿಯಿಸುವ ಮುನ್ನ ನಿಜವಾದ ನೀತಿ ದಾಖಲೆಯನ್ನು ಮರುಪಡೆದಿದೆ. ನಿಮ್ಮ Q3 ಆದಾಯದ ಅಂಕಿಗಳನ್ನು ಅಂದಾಜು ಮಾಡುತ್ತಿಲ್ಲ. ಉತ್ತರಿಸುವ ಮುನ್ನ ನಿಮ್ಮ ಹಣಕಾಸು ವ್ಯವಸ್ಥೆಯಿಂದ ನಿಜವಾದ ಅಂಕಿಗಳನ್ನು ಎಳೆದಿದೆ. ಮಾದರಿಯ ಪಾತ್ರವು ಏಕೈಕ ಜ್ಞಾನ ಮೂಲದಿಂದ ಮರುಪಡೆದ ಮಾಹಿತಿಯ ಬುದ್ಧಿವಂತ ಸಂಯೋಜಕನಿಗೆ ಬದಲಾಗುತ್ತದೆ, ಇದು ಭಾಷಾ ಮಾದರಿಗಳು ಅಸಾಮಾನ್ಯವಾಗಿ ಚೆನ್ನಾಗಿ ನಿರ್ವಹಿಸುವ ಕಾರ್ಯ.
ಈ ವಾಸ್ತುಶಿಲ್ಪೀಯ ಬದಲಾವಣೆಯು hallucinationಗಳನ್ನು ಸರಿಪಡಿಸುವುದನ್ನು ಮೀರಿ ಪರಿಣಾಮಗಳನ್ನು ಹೊಂದಿದೆ. ಇದರ ಅರ್ಥ AI ವ್ಯವಸ್ಥೆಗಳನ್ನು ಅವುಗಳ ಮಾದರಿಗಳನ್ನು ಮರು-ತರಬೇತಿ ನೀಡುವ ಬದಲು ಅವುಗಳ ಜ್ಞಾನ ಮೂಲಗಳನ್ನು ನವೀಕರಿಸುವ ಮೂಲಕ ನವೀಕರಿಸಬಹುದು. ಇದರ ಅರ್ಥ ಪ್ರತಿಕ್ರಿಯೆಗಳು ತಮ್ಮ ಮೂಲಗಳನ್ನು ಉಲ್ಲೇಖಿಸಬಹುದು, ಪರಿಶೀಲನೆಯನ್ನು ಸರಳಗೊಳಿಸುತ್ತದೆ. ಮತ್ತು ಇದರ ಅರ್ಥ ಸಂಸ್ಥೆಗಳು ಆ ಜ್ಞಾನವನ್ನು ತರಬೇತಿ ಡೇಟಾಸೆಟ್ನಲ್ಲಿ ಸೇರಿಸದೆಯೇ ನಿಜವಾಗಿಯೂ ಸೂಕ್ಷ್ಮ ಆಂತರಿಕ ಜ್ಞಾನಕ್ಕೆ ಪ್ರವೇಶವಿರುವ AI ವ್ಯವಸ್ಥೆಗಳನ್ನು ನಿರ್ಮಿಸಬಹುದು.
RAG AI ನಿಜವಾಗಿ ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ
Retrieval ಪೈಪ್ಲೈನ್ ವಿವರಣೆ
ಭಾಷಾ ಮಾದರಿಯು ತನ್ನ ಪ್ರತಿಕ್ರಿಯೆಯ ಒಂದು ಪದವನ್ನು ಸಹ ಉತ್ಪಾದಿಸುವ ಮುನ್ನ ಅನುಕ್ರಮವಾಗಿ ಕೆಲಸ ಮಾಡುವ ಎರಡು ಪ್ರಮುಖ ಘಟಕಗಳು RAG ವ್ಯವಸ್ಥೆಗೆ ಇರುತ್ತವೆ.
ಮೊದಲ ಘಟಕ ಜ್ಞಾನ ಬೇಸ್ ಮತ್ತು ಅದರ ಸೂಚಿಕರಣ ಮೂಲಸೌಕರ್ಯ. ದಾಖಲೆಗಳು, ರೆಕಾರ್ಡ್ಗಳು, ವೆಬ್ ಪುಟಗಳು, ಡೇಟಾಬೇಸ್ ನಮೂದುಗಳು ಅಥವಾ AI ಸೆಳೆಯಬೇಕಾದ ಯಾವುದೇ ಇತರ ಮಾಹಿತಿಯನ್ನು ಸಂಸ್ಕರಿಸಿ, ಕೇವಲ ಪದಗಳಿಂದ ಅಲ್ಲದೆ ಅರ್ಥದಿಂದ ಹುಡುಕಬಹುದಾದ ರೀತಿಯಲ್ಲಿ ಸಂಗ್ರಹಿಸಲಾಗುತ್ತದೆ. ಇದು ಸಾಮಾನ್ಯವಾಗಿ ಪಠ್ಯವನ್ನು embeddings ಎಂದು ಕರೆಯಲಾಗುವ ಸಂಖ್ಯಾತ್ಮಕ ಪ್ರತಿನಿಧಾನಗಳಾಗಿ ಪರಿವರ್ತಿಸುವುದನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ, ಇದು ಗಣಿತೀಯವಾಗಿ ಸಮಾನವಾದ ವಿಷಯವನ್ನು ಒಟ್ಟಿಗೆ ಮರುಪಡೆಯಲು ಅವಕಾಶ ನೀಡುವ ರೂಪದಲ್ಲಿ ಅರ್ಥವನ್ನು ಹಿಡಿದಿಡುತ್ತದೆ. ಗ್ರಾಹಕ ಮರುಪಾವತಿ ಪ್ರಕ್ರಿಯೆಗಳ ಬಗ್ಗೆ ಪ್ರಶ್ನೆಯು ಆ ನಿಖರ ಪದಗಳು ಪ್ರಶ್ನೆಯಲ್ಲಿ ಕಾಣಿಸದಿದ್ದರೂ ಮರಳುವಿಕೆಗಳು, ವಿನಿಮಯಗಳು ಮತ್ತು ತೃಪ್ತಿ ಖಾತರಿಗಳ ಬಗ್ಗೆ ವಿಷಯವನ್ನು ಮರುಪಡೆಯುತ್ತದೆ.
ಎರಡನೇ ಘಟಕ ಒಬ್ಬ ಬಳಕೆದಾರನು ಪ್ರಶ್ನೆಯನ್ನು ಸಲ್ಲಿಸಿದಾಗ ಸಕ್ರಿಯವಾಗುವ retrieval ಯಂತ್ರೋಪಾಯ. ಪ್ರಶ್ನೆಯನ್ನು ಸಂಗ್ರಹಿಸಿದ ದಾಖಲೆಗಳಂತೆಯೇ ಅದೇ embedding ರೂಪಕ್ಕೆ ಪರಿವರ್ತಿಸಲಾಗುತ್ತದೆ, ಮತ್ತು ಪ್ರಶ್ನೆಗೆ ಶಬ್ದಾರ್ಥವಾಗಿ ಅತ್ಯಂತ ಸಮಾನವಾದ ಸಂಗ್ರಹಿಸಿದ ವಿಷಯವನ್ನು ವ್ಯವಸ್ಥೆಯು ಗುರುತಿಸುತ್ತದೆ. ಆ ಮರುಪಡೆದ ವಿಷಯ, ಅಂದರೆ ಕೇಳಲಾದ ಪ್ರಶ್ನೆಗೆ ಹೆಚ್ಚು ಸಂಬಂಧಿತವಾದ ಪಠ್ಯಭಾಗಗಳು, ದಾಖಲೆಗಳು ಅಥವಾ ರೆಕಾರ್ಡ್ಗಳನ್ನು ಒಟ್ಟುಗೂಡಿಸಿ ಮೂಲ ಪ್ರಶ್ನೆಯೊಂದಿಗೆ ಭಾಷಾ ಮಾದರಿಗೆ ರವಾನಿಸಲಾಗುತ್ತದೆ.
ನಂತರ ಭಾಷಾ ಮಾದರಿಯು ಅಗತ್ಯವಿರುವ ನಿರ್ದಿಷ್ಟ ಸತ್ಯಗಳಿಗಾಗಿ ತನ್ನ ತರಬೇತಿ ಡೇಟಾವನ್ನು ಅವಲಂಬಿಸುವ ಬದಲು ಆ ಮರುಪಡೆದ ಸಂದರ್ಭದಲ್ಲಿ ಆಧಾರಿತವಾಗಿ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. ಮಾದರಿಯ ಭಾಷಾ ಸಾಮರ್ಥ್ಯ, ಅದರ ತಾರ್ಕಿಕ ಸಾಮರ್ಥ್ಯ ಮತ್ತು ಅದರ ಸಾಮಾನ್ಯ ವಿಶ್ವ ಜ್ಞಾನಕ್ಕೆ ತರಬೇತಿ ಡೇಟಾ ಇನ್ನೂ ಮಹತ್ವದ್ದು. ಆದರೆ ಪ್ರತಿಕ್ರಿಯೆಯ ನಿರ್ದಿಷ್ಟ ವಾಸ್ತವಿಕ ವಿಷಯವು ಮರುಪಡೆದ ವಸ್ತುಗಳಿಂದ ಬರುತ್ತದೆ.
| RAG ವ್ಯವಸ್ಥೆಯ ಘಟಕ | ಅದು ಏನು ಮಾಡುತ್ತದೆ | ಏಕೆ ಮುಖ್ಯ |
|---|---|---|
| Document Ingestion | ಸೂಚಿಕರಣಕ್ಕಾಗಿ ಮೂಲ ದಾಖಲೆಗಳನ್ನು ಸಂಸ್ಕರಿಸಿ chunk ಮಾಡುತ್ತದೆ | ವ್ಯವಸ್ಥೆಯು ಯಾವ ಜ್ಞಾನವನ್ನು ಪ್ರವೇಶಿಸಬಹುದು ಎಂಬುದನ್ನು ನಿರ್ಧರಿಸುತ್ತದೆ |
| Embedding Model | ಪಠ್ಯವನ್ನು ಶಬ್ದಾರ್ಥ ವೆಕ್ಟರ್ ಪ್ರತಿನಿಧಾನಗಳಿಗೆ ಪರಿವರ್ತಿಸುತ್ತದೆ | ಕೀವರ್ಡ್ ಹೊಂದಾಣಿಕೆಯ ಬದಲು ಅರ್ಥ-ಆಧಾರಿತ retrievalಗೆ ಅವಕಾಶ ನೀಡುತ್ತದೆ |
| Vector Database | ತ್ವರಿತ ಸಾಮ್ಯತಾ ಹುಡುಕಾಟಕ್ಕಾಗಿ embeddingsಗಳನ್ನು ಸಂಗ್ರಹಿಸುತ್ತದೆ | ರಿಯಲ್-ಟೈಮ್ ಬಳಕೆಗೆ ಸಾಕಷ್ಟು ವೇಗವಾಗಿ retrievalಅನ್ನು ಮಾಡುತ್ತದೆ |
| Retrieval ಯಂತ್ರೋಪಾಯ | ಪ್ರತಿ ಪ್ರಶ್ನೆಗೆ ಅತ್ಯಂತ ಸಂಬಂಧಿತ ವಿಷಯವನ್ನು ಗುರುತಿಸುತ್ತದೆ | ಮರುಪಡೆದ ಸಂದರ್ಭದ ನಿಖರತೆಯನ್ನು ನಿರ್ಧರಿಸುತ್ತದೆ |
| Language Model | ಮರುಪಡೆದ ವಿಷಯದಲ್ಲಿ ಆಧಾರಿತ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ | ಮರುಪಡೆದ ಸತ್ಯಗಳಿಂದ ಸಂಯೋಜಿತ, ಸಮನ್ವಯ ಔಟ್ಪುಟ್ ಉತ್ಪಾದಿಸುತ್ತದೆ |
| ಮೂಲ ಆಪಾದನೆ | ಪ್ರತಿ ಪ್ರತಿಕ್ರಿಯೆಗೆ ಯಾವ ದಾಖಲೆಗಳು ಮಾಹಿತಿ ನೀಡಿವೆ ಎಂದು ಟ್ರ್ಯಾಕ್ ಮಾಡುತ್ತದೆ | ಪರಿಶೀಲನೆಗೆ ಅವಕಾಶ ನೀಡುತ್ತದೆ ಮತ್ತು ಬಳಕೆದಾರ ನಂಬಿಕೆಯನ್ನು ಕಟ್ಟುತ್ತದೆ |
RAG ಪೈಪ್ಲೈನ್ಗಳಲ್ಲಿ AI architecture ನಿರ್ಧಾರಗಳು retrieval ಗುಣಮಟ್ಟ ಮತ್ತು ಪ್ರತಿಕ್ರಿಯೆ ನಿಖರತೆ ಎರಡನ್ನೂ ಹೇಗೆ ಪ್ರಭಾವಿಸುತ್ತವೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು ಪ್ರದರ್ಶನಗಳಲ್ಲಿ ಚೆನ್ನಾಗಿ ಮತ್ತು ಉತ್ಪಾದನೆಯಲ್ಲಿ ಅಸ್ಥಿರವಾಗಿ ಕೆಲಸ ಮಾಡುವ ಬದಲು ವಿಶ್ವಾಸಾರ್ಹವಾಗಿ ಕೆಲಸ ಮಾಡುವ ವ್ಯವಸ್ಥೆಗಳನ್ನು ಕಟ್ಟಲು ಸಂಸ್ಥೆಗಳಿಗೆ ಸಹಾಯ ಮಾಡುತ್ತದೆ.
RAG vs ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLM: ಪ್ರಾಯೋಗಿಕವಾಗಿ ವ್ಯತ್ಯಾಸ ಎಲ್ಲಿ ಕಾಣಿಸುತ್ತದೆ
RAG AI ಎಂದರೇನು ಮತ್ತು ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLM ಏನು ಮಾಡುತ್ತದೆ ಎಂಬುದರ ನಡುವಿನ ವ್ಯತ್ಯಾಸವು ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಮಾದರಿಗಳು ವಿಫಲವಾಗುವ ಮತ್ತು RAG ವ್ಯವಸ್ಥೆಗಳು ಯಶಸ್ವಿಯಾಗುವ ನಿರ್ದಿಷ್ಟ ಸನ್ನಿವೇಶಗಳಲ್ಲಿ ಹೆಚ್ಚು ಗೋಚರಿಸುತ್ತದೆ.
ನಿಮ್ಮ ಸಂಸ್ಥೆಯ ಪ್ರಸ್ತುತ ಡೇಟಾ ಧಾರಣ ನೀತಿಯ ಬಗ್ಗೆ ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLMಗೆ ಕೇಳಿದಾಗ ಅದು ತನ್ನ ತರಬೇತಿ ಡೇಟಾದಿಂದ ಸಾಮಾನ್ಯ ಡೇಟಾ ಧಾರಣ ಪದ್ಧತಿಗಳ ಆಧಾರದ ಮೇಲೆ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. ಅದು ಸರಿಯಾಗಿ ತೋರಬಹುದು. ಅದು ಬಹುತೇಕ ಖಚಿತವಾಗಿ ನಿಮ್ಮ ನಿಜವಾದ ನೀತಿಯನ್ನು ವಿವರಿಸುತ್ತಿಲ್ಲ. ಅದೇ ಪ್ರಶ್ನೆಯನ್ನು ಕೇಳಿದ RAG ವ್ಯವಸ್ಥೆಯು ನಿಮ್ಮ ನಿಜವಾದ ನೀತಿ ದಾಖಲೆಯನ್ನು ಮರುಪಡೆಯುತ್ತದೆ ಮತ್ತು ಆ ದಾಖಲೆಯು ಏನು ಹೇಳುತ್ತದೆ ಎಂಬುದರ ಆಧಾರದ ಮೇಲೆ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. ಭಾಷೆ ಸಮಾನ. ನಿಖರತೆ ವರ್ಗೀಯವಾಗಿ ಭಿನ್ನ.
ನಿನ್ನೆ ಸಲ್ಲಿಸಿದ ಗ್ರಾಹಕ ದೂರಿನ ಬಗ್ಗೆ ಕೇಳಿದ ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLMಗೆ ನೀವು ಏನು ಮಾತನಾಡುತ್ತಿದ್ದೀರಿ ಎಂದು ಗೊತ್ತಿಲ್ಲ. ದೂರು ಅದರ ತರಬೇತಿಯ ನಂತರ ಇದೆ. ನಿಮ್ಮ CRMಗೆ ಸಂಪರ್ಕಿತ RAG ವ್ಯವಸ್ಥೆಯು ದೂರಿನ ರೆಕಾರ್ಡ್ ಅನ್ನು ಮರುಪಡೆಯುತ್ತದೆ ಮತ್ತು ಆ ನಿರ್ದಿಷ್ಟ ಗ್ರಾಹಕನ ಪರಿಸ್ಥಿತಿಯ ನಿಜವಾದ ವಿವರಗಳನ್ನು ಪ್ರತಿಬಿಂಬಿಸುವ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ.
ನೀವು ಅಪ್ಲೋಡ್ ಮಾಡಿದ ಸಂಶೋಧನಾ ವರದಿಯಿಂದ ಪ್ರಮುಖ ಸಂಶೋಧನೆಗಳನ್ನು ಸಾರಾಂಶಗೊಳಿಸಲು ಕೇಳಿದ ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLM ಸಮಂಜಸವಾಗಿ ತೋರುವ ಸಾರಾಂಶವನ್ನು ಉತ್ಪಾದಿಸಬಹುದು, ಅದು ನಿರ್ಣಾಯಕ ಸಂಶೋಧನೆಗಳನ್ನು ಬಿಡಬಹುದು, ತೀರ್ಮಾನಗಳನ್ನು ತಪ್ಪಾಗಿ ಪ್ರತಿನಿಧಿಸಬಹುದು ಅಥವಾ ದಾಖಲೆಯ ವಿವಿಧ ಭಾಗಗಳಿಂದ ವಿವರಗಳನ್ನು ತಪ್ಪಾಗಿ ಸಂಯೋಜಿಸಬಹುದು. RAG ವ್ಯವಸ್ಥೆಯು ಸಾರಾಂಶ ವಿನಂತಿಗೆ ಹೆಚ್ಚು ಸಂಬಂಧಿತ ನಿರ್ದಿಷ್ಟ ವಿಭಾಗಗಳನ್ನು ಮರುಪಡೆಯುತ್ತದೆ ಮತ್ತು ನಿಜವಾದ ಪಠ್ಯದಲ್ಲಿ ಆಧಾರಿತ ಔಟ್ಪುಟ್ ಅನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ.
| ಸನ್ನಿವೇಶ | ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLM ಪ್ರತಿಕ್ರಿಯೆ | RAG AI ಪ್ರತಿಕ್ರಿಯೆ |
|---|---|---|
| ಆಂತರಿಕ ನೀತಿ ಪ್ರಶ್ನೆ | ನಿಮ್ಮ ನೀತಿಗಳಿಗೆ ನಿರ್ದಿಷ್ಟವಲ್ಲದ ಸಾಮಾನ್ಯ ಸಮಂಜಸ ಉತ್ತರವನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ | ನಿಜವಾದ ನೀತಿ ದಾಖಲೆಯನ್ನು ಮರುಪಡೆಯುತ್ತದೆ, ಅದರ ವಿಷಯದಿಂದ ಉತ್ತರಿಸುತ್ತದೆ |
| ಇತ್ತೀಚಿನ ಘಟನೆಯ ಬಗ್ಗೆ ಪ್ರಶ್ನೆ | ತನಗೆ ಮಾಹಿತಿ ಇಲ್ಲ ಎಂದು ಹೇಳುತ್ತದೆ ಅಥವಾ ಹಳೆಯ ಉತ್ತರವನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ | ಸಂಪರ್ಕಿತ ಜ್ಞಾನ ಬೇಸ್ನಿಂದ ಪ್ರಸ್ತುತ ಮಾಹಿತಿಯನ್ನು ಮರುಪಡೆಯುತ್ತದೆ |
| ಗ್ರಾಹಕ-ನಿರ್ದಿಷ್ಟ ವಿಚಾರಣೆ | ವೈಯಕ್ತಿಕ ಗ್ರಾಹಕ ಡೇಟಾವನ್ನು ಪ್ರವೇಶಿಸಲಾಗುವುದಿಲ್ಲ | ಸಂಬಂಧಿತ ಗ್ರಾಹಕ ರೆಕಾರ್ಡ್ಗಳನ್ನು ಮರುಪಡೆದು ನಿಖರವಾಗಿ ಪ್ರತಿಕ್ರಿಯಿಸುತ್ತದೆ |
| ತಾಂತ್ರಿಕ ದಸ್ತಾವೇಜು ಪ್ರಶ್ನೆ | ತಾಂತ್ರಿಕ ವಿವರಗಳನ್ನು hallucinate ಮಾಡಬಹುದು | ನಿರ್ದಿಷ್ಟ ದಸ್ತಾವೇಜು ವಿಭಾಗಗಳನ್ನು ಮರುಪಡೆದು ಉಲ್ಲೇಖಿಸುತ್ತದೆ |
| ಸ್ಪರ್ಧಾತ್ಮಕ ಗುಪ್ತಚರ | ತರಬೇತಿ ಡೇಟಾಕ್ಕೆ ಸೀಮಿತ, ಸಾಮಾನ್ಯವಾಗಿ ಹಳೆಯದು | ಸಂಪರ್ಕಿತ ಮೂಲಗಳಿಂದ ಪ್ರಸ್ತುತ ಮಾಹಿತಿಯನ್ನು ಮರುಪಡೆಯುತ್ತದೆ |
| ಅನುಸರಣೆ ಪ್ರಶ್ನೆ | ಸಾಮಾನ್ಯ ನಿಯಂತ್ರಕ ಜ್ಞಾನದಿಂದ ಉತ್ತರಿಸುತ್ತದೆ | ಅನ್ವಯವಾಗುವ ನಿಯಮಗಳು ಮತ್ತು ಸಂಸ್ಥೆ-ನಿರ್ದಿಷ್ಟ ಕಾರ್ಯವಿಧಾನಗಳನ್ನು ಮರುಪಡೆಯುತ್ತದೆ |
ವ್ಯವಹಾರಗಳು RAG AIಯನ್ನು ಅತ್ಯಂತ ಪರಿಣಾಮಕಾರಿಯಾಗಿ ನಿಯೋಜಿಸುತ್ತಿರುವ ಸ್ಥಳಗಳು
ಆಂತರಿಕ ಜ್ಞಾನ ನಿರ್ವಹಣೆ
ಆಂತರಿಕ ಜ್ಞಾನ ನಿರ್ವಹಣೆಯ ಬಳಕೆ ಪ್ರಕರಣವು RAG AI ತನ್ನ ಸ್ಪಷ್ಟ ವ್ಯವಹಾರ ಮೌಲ್ಯವನ್ನು ತಲುಪಿಸುವ ಸ್ಥಳವಾಗಿದೆ. ಹೆಚ್ಚಿನ ಸಂಸ್ಥೆಗಳಿಗೆ ದಾಖಲಾತಿ ಸಂಗ್ರಹಾಲಯಗಳು, wikiಗಳು, ಹಿಂದಿನ ಪ್ರಾಜೆಕ್ಟ್ ಫೈಲ್ಗಳು, ನೀತಿ ದಾಖಲೆಗಳು ಮತ್ತು ಸಂವಹನಗಳಲ್ಲಿ ವಿತರಣಗೊಂಡ ಗಣನೀಯ ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನವಿದೆ, ಇದನ್ನು ಹುಡುಕಲು ಕೈಯಿಂದ ಗಮನಾರ್ಹ ಸಮಯವನ್ನು ಉದ್ಯೋಗಿಗಳು ಕಳೆಯುತ್ತಾರೆ. ಆ ಜ್ಞಾನ ಬೇಸ್ ಮೇಲಿನ RAG ವ್ಯವಸ್ಥೆಯು ಅದನ್ನು ನೌಕರರು ಸ್ವಾಭಾವಿಕ ಭಾಷೆಯಲ್ಲಿ ಪ್ರಶ್ನಿಸಬಹುದಾದ ಮತ್ತು ನಿಖರ, ಮೂಲ-ಸಹಿತ ಉತ್ತರಗಳನ್ನು ಪಡೆಯಬಹುದಾದ ಸಂಭಾಷಣಾ ಸಂಪನ್ಮೂಲವನ್ನಾಗಿ ಪರಿವರ್ತಿಸುತ್ತದೆ.
ಇಲ್ಲಿನ ಸಂಚಿತ ಮೌಲ್ಯವು ಗಣನೀಯ. ಸಂಸ್ಥೆ ಜ್ಞಾನವನ್ನು ತಮ್ಮ ತಲೆಯಲ್ಲಿ ಹೊಂದಿರುವ ಅನುಭವಿ ನೌಕರರು ಅಂತಿಮವಾಗಿ ಬಿಟ್ಟು ಹೋಗುತ್ತಾರೆ. ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಆದರೆ ಹುಡುಕಲು ಕಠಿಣವಾದ ದಸ್ತಾವೇಜು ಇಲ್ಲದ ದಸ್ತಾವೇಜಿನಷ್ಟೇ ಕಾರ್ಯಾತ್ಮಕವಾಗಿ ಪ್ರವೇಶಿಸಲಾಗದಿರುತ್ತದೆ. RAG ವ್ಯವಸ್ಥೆಗಳು ಸೇವಾ ಅವಧಿಯನ್ನು ಲೆಕ್ಕಿಸದೆ ಎಲ್ಲ ನೌಕರರಿಗೆ ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನವನ್ನು ಪ್ರವೇಶಿಸಬಹುದಾಗಿ ಮಾಡುತ್ತವೆ, ಮಾಹಿತಿಯನ್ನು ಹುಡುಕಲು ಬಳಸುವ ಸಮಯವನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತವೆ, ಮತ್ತು ನೌಕರರಿಗೆ ಎಲ್ಲಿ ನೋಡಬೇಕು ಎಂಬುದು ತಿಳಿಯಬೇಕು ಎಂದು ಒತ್ತಾಯಿಸುವ ಬದಲು ಅಗತ್ಯವಿರುವ ಸಂದರ್ಭದಲ್ಲಿ ಸಂಬಂಧಿತ ಜ್ಞಾನವನ್ನು ಪ್ರಸ್ತುತಪಡಿಸುತ್ತವೆ.
ಎಂಟರ್ಪ್ರೈಸ್ RAG ಪ್ಲಾಟ್ಫಾರ್ಮ್ಗಳಲ್ಲಿನ AI features ಮರುಪಡೆದ ವಿಷಯದ ಮೇಲೆ ಪ್ರವೇಶ ನಿಯಂತ್ರಣವನ್ನು ಹೇಗೆ ನಿರ್ವಹಿಸುತ್ತವೆ ಎಂಬುದನ್ನು ಪರಿಶೀಲಿಸುವುದು ಈ ಬಳಕೆ ಪ್ರಕರಣಕ್ಕೆ ಅಗತ್ಯ, ಏಕೆಂದರೆ ಎಲ್ಲ ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನ ಎಲ್ಲ ನೌಕರರಿಗೆ ಸಮಾನವಾಗಿ ಪ್ರವೇಶಿಸಬಹುದಾಗಿರಬಾರದು. ಸರಿಯಾಗಿ ಕಾನ್ಫಿಗರ್ ಮಾಡಲಾದ RAG ವ್ಯವಸ್ಥೆಯು ಜ್ಞಾನ ಬೇಸ್ನಲ್ಲಿರುವ ಎಲ್ಲವನ್ನೂ ಅಲ್ಲ, ಪ್ರಶ್ನಿಸುವ ಬಳಕೆದಾರನು ಪ್ರವೇಶಿಸಲು ಅಧಿಕಾರ ಪಡೆದ ವಿಷಯವನ್ನು ಮಾತ್ರ ಮರುಪಡೆಯುತ್ತದೆ.
ಗ್ರಾಹಕ-ಎದುರಿನ ಬೆಂಬಲ ಮತ್ತು ಸೇವೆ
RAG-ಚಾಲಿತ ಗ್ರಾಹಕ ಸೇವಾ ಅಪ್ಲಿಕೇಶನ್ಗಳು ಈ ತಂತ್ರಜ್ಞಾನದ ಅತ್ಯಂತ ವಾಣಿಜ್ಯ ಪರಿಣಾಮಕಾರಿ ನಿಯೋಜನೆಗಳಲ್ಲಿ ಒಂದನ್ನು ಪ್ರತಿನಿಧಿಸುತ್ತವೆ. ನಿಮ್ಮ ಉತ್ಪನ್ನ ದಸ್ತಾವೇಜು, ಸಮಸ್ಯೆಯ ಪರಿಹಾರ ಮಾರ್ಗದರ್ಶಿಗಳು, ಆದೇಶ ನಿರ್ವಹಣಾ ವ್ಯವಸ್ಥೆ ಮತ್ತು ನೀತಿ ಡೇಟಾಬೇಸ್ ಮೇಲಿನ RAG ಪೈಪ್ಲೈನ್ನಿಂದ ಬೆಂಬಲಿತ ಗ್ರಾಹಕ ಸೇವಾ AI, ಗ್ರಾಹಕರಿಗೆ ಅಗತ್ಯವಿರುವ ನಿರ್ದಿಷ್ಟ ಮಾಹಿತಿಗಾಗಿ ಮಾನವ ಏಜೆಂಟರಿಗೆ ಕಳುಹಿಸುವ ಸಾಮಾನ್ಯ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವ ಬದಲು, ಗ್ರಾಹಕನ ನಿಜವಾದ ಪರಿಸ್ಥಿತಿಯ ಬಗ್ಗೆ ನಿರ್ದಿಷ್ಟ, ನಿಖರ ಪ್ರಶ್ನೆಗಳಿಗೆ ಉತ್ತರಿಸಬಹುದು.
ವ್ಯವಹಾರ ಪ್ರಕರಣವು ಸ್ಪಷ್ಟವಾಗಿದೆ. ನಿಖರವಾದ ಮೊದಲ-ಸಂಪರ್ಕ ಪರಿಹಾರವು ಬೆಂಬಲ ವೆಚ್ಚಗಳನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ, ಮಾನವ ಏಜೆಂಟರಿಗೆ ಎಸ್ಕಲೇಶನ್ಗಳನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ, ಮತ್ತು ಉತ್ತಮ ಗ್ರಾಹಕ ಫಲಿತಾಂಶಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. AI ವ್ಯವಸ್ಥೆಗಳಿಗೆ ನಿಖರವಾದ ಮೊದಲ-ಸಂಪರ್ಕ ಪರಿಹಾರವನ್ನು ಸಾಧ್ಯವಾಗಿಸುವ ತಾಂತ್ರಿಕ ಆಧಾರವು ಬಹುತೇಕ ಯಾವಾಗಲೂ RAG. retrieval ಇಲ್ಲದೆ, ಮಾದರಿಯು ನಿಖರವಾದ ಬೆಂಬಲ ಪ್ರತಿಕ್ರಿಯೆಗಳಿಗೆ ಅಗತ್ಯವಿರುವ ಪ್ರಸ್ತುತ, ಗ್ರಾಹಕ-ನಿರ್ದಿಷ್ಟ ಮಾಹಿತಿಯನ್ನು ಪ್ರವೇಶಿಸಲಾಗದು.
ಅನುಸರಣೆ ಮತ್ತು ನಿಯಂತ್ರಕ ಅಪ್ಲಿಕೇಶನ್ಗಳು
ಹಣಕಾಸು ಸೇವೆಗಳು, ಆರೋಗ್ಯ ರಕ್ಷಣೆ, ಕಾನೂನು, ಮತ್ತು ಇತರ ಹೆಚ್ಚು ನಿಯಂತ್ರಿತ ಉದ್ಯಮಗಳು ಅನುಸರಣಾ ತಂಡಗಳಿಗೆ ಸಂಕೀರ್ಣ, ಆಗಾಗ್ಗೆ ನವೀಕರಿಸಲಾದ ನಿಯಮ ಸೆಟ್ಗಳನ್ನು ಹೆಚ್ಚು ಪರಿಣಾಮಕಾರಿಯಾಗಿ ನಡೆಸಲು ಸಹಾಯ ಮಾಡಲು ನಿಯಂತ್ರಕ ದಸ್ತಾವೇಜು ಸೆಟ್ಗಳ ಮೇಲೆ RAG AIಯನ್ನು ನಿಯೋಜಿಸುತ್ತಿವೆ. ಅನ್ವಯವಾಗುವ ನಿಬಂಧನೆಗಳು, ಮಾರ್ಗದರ್ಶನ ದಸ್ತಾವೇಜುಗಳು ಮತ್ತು ಆಂತರಿಕ ನೀತಿ ಚೌಕಟ್ಟುಗಳ ಪೂರ್ಣ ಪಠ್ಯದ ಮೇಲೆ RAG ವ್ಯವಸ್ಥೆಯನ್ನು ಪ್ರಶ್ನಿಸಬಹುದಾದ ಮತ್ತು ನಿರ್ದಿಷ್ಟ ಅನುಸರಣಾ ಪ್ರಶ್ನೆಗಳಿಗೆ ನಿಖರ, ಮೂಲ-ಸಹಿತ ಉತ್ತರಗಳನ್ನು ಪಡೆಯಬಹುದಾದ ಅನುಸರಣಾ ಅಧಿಕಾರಿಯು ನೆನಪು ಅಥವಾ ಕೈಯಿಂದ ದಸ್ತಾವೇಜು ಪರಿಶೀಲನೆಯನ್ನು ಅವಲಂಬಿಸಿರುವವರಿಗಿಂತ ಹೆಚ್ಚು ಪರಿಣಾಮಕಾರಿಯಾಗಿ ಮತ್ತು ಹೆಚ್ಚು ವಿಶ್ವಾಸದಿಂದ ಕೆಲಸ ಮಾಡುತ್ತಾನೆ.
RAG ವ್ಯವಸ್ಥೆಗಳ ಉಲ್ಲೇಖಿಸುವ ಸಾಮರ್ಥ್ಯವು ಅನುಸರಣಾ ಸಂದರ್ಭಗಳಲ್ಲಿ ವಿಶೇಷವಾಗಿ ಮೌಲ್ಯಯುತ. ಎಳೆದ ನಿರ್ದಿಷ್ಟ ನಿಯಂತ್ರಕ ಪ್ಯಾರಾಗ್ರಾಫ್ ಅನ್ನು ಉಲ್ಲೇಖಿಸುವ ಉತ್ತರವು, ಮೂಲವಿಲ್ಲದ AI-ಉತ್ಪಾದಿತ ಉತ್ತರಕ್ಕಿಂತ ಪರಿಶೀಲಿಸಬಹುದಾದ ಮತ್ತು ಸಮರ್ಥನೀಯವಾಗಿರುತ್ತದೆ. ಆ ವ್ಯತ್ಯಾಸವು ಉತ್ತರವು ನಿಯಂತ್ರಕ ಪರಿಣಾಮಗಳೊಂದಿಗೆ ನಿರ್ಧಾರಕ್ಕೆ ಮಾಹಿತಿ ನೀಡಿದಾಗ ಅಗಾಧವಾಗಿ ಮಹತ್ವದ್ದು.
ಸೂಕ್ಷ್ಮ ನಿಯಂತ್ರಕ ಮತ್ತು ಅನುಸರಣಾ ಡೇಟಾಗೆ ಸಂಪರ್ಕಿತ RAG ವ್ಯವಸ್ಥೆಗಳಿಗೆ AI security ಅವಶ್ಯಕತೆಗಳು ಹೇಗೆ ಅನ್ವಯಿಸುತ್ತವೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು ಸಂಸ್ಥೆಗಳಿಗೆ ಸೂಚಿಕರಿಸಿದ ದಾಖಲೆಗಳಾದ್ಯಂತ ಸೂಕ್ತ ಪ್ರವೇಶ ನಿಯಂತ್ರಣಗಳನ್ನು ನಿರ್ವಹಿಸುವ retrieval ಪೈಪ್ಲೈನ್ಗಳನ್ನು ಕಟ್ಟಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ.

ನಿಜವಾಗಿಯೂ ಕೆಲಸ ಮಾಡುವ RAG ವ್ಯವಸ್ಥೆಯನ್ನು ಕಟ್ಟುವುದು
ಹೆಚ್ಚಿನ ಪ್ರಾಜೆಕ್ಟ್ಗಳು ಕಡಿಮೆ ಅಂದಾಜು ಮಾಡುವ ಡೇಟಾ ಗುಣಮಟ್ಟ ಸಮಸ್ಯೆ
RAG ವ್ಯವಸ್ಥೆಗಳು ಅವು ಮರುಪಡೆಯುವ ವಿಷಯದಷ್ಟೇ ಉತ್ತಮ. ಡೇಟಾ ಗುಣಮಟ್ಟ ಮೌಲ್ಯಮಾಪನವನ್ನು ತ್ವರಿತವಾಗಿ ದಾಟಿ AI ಇಂಟರ್ಫೇಸ್ ಕಟ್ಟುವ ಉತ್ತೇಜಕ ಭಾಗಕ್ಕೆ ಹೋಗುವ ಸಂಸ್ಥೆಗಳು ಸತತವಾಗಿ retrieval ಗುಣಮಟ್ಟವು ಭಾಷಾ ಮಾದರಿಯ ಆಯ್ಕೆಗಿಂತ ಹೆಚ್ಚು ಪ್ರತಿಕ್ರಿಯೆ ಗುಣಮಟ್ಟವನ್ನು ನಿರ್ಧರಿಸುತ್ತದೆ ಎಂದು ಕಂಡುಕೊಳ್ಳುತ್ತವೆ. ಕಳಪೆ ಮೂಲ ದಾಖಲೆಗಳು, ಹಳೆಯ ವಿಷಯ, ಅಸಮಂಜಸವಾಗಿ ಫಾರ್ಮ್ಯಾಟ್ ಮಾಡಿದ ಮಾಹಿತಿ, ಮತ್ತು ನಿರ್ವಹಿಸದ ಜ್ಞಾನ ಬೇಸ್ಗಳು ತಪ್ಪು ವಿಷಯವನ್ನು ಮರುಪಡೆಯುವ ಮತ್ತು ಯಾವುದೇ ಮಾಹಿತಿಯಿಲ್ಲದ ಬದಲು ಕೆಟ್ಟ ಮಾಹಿತಿಯಲ್ಲಿ ಆಧಾರಿತವಾದ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವ RAG ವ್ಯವಸ್ಥೆಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತವೆ.
ಪ್ರಾಯೋಗಿಕ ಪರಿಣಾಮವೆಂದರೆ ಜ್ಞಾನ ಬೇಸ್ ಸಿದ್ಧತೆಯು ನಿಜವಾದ ಕೆಲಸ ಪ್ರಾರಂಭವಾಗುವ ಮುನ್ನ ತ್ವರಿತವಾಗಿ ಪೂರ್ಣಗೊಳಿಸುವ ಪೂರ್ವಭಾವಿ ಹೆಜ್ಜೆಯಲ್ಲ. ಇದು ನಿಯೋಜಿಸಿದ ವ್ಯವಸ್ಥೆಯು ಉಪಯುಕ್ತವಾಗಿರುತ್ತದೆಯೇ ಎಂಬುದನ್ನು ನಿರ್ಧರಿಸುವ ಪ್ರಾಜೆಕ್ಟ್ನ ಕೋರ್ ಭಾಗ. ದಸ್ತಾವೇಜು ಗುಣಮಟ್ಟ ಪರಿಶೀಲನೆ, ವಿಷಯದ ಪ್ರಸ್ತುತತೆ ಮೌಲ್ಯಮಾಪನ, ಸಂಘರ್ಷಿಸುವ ಆವೃತ್ತಿಗಳ ಡಿಡ್ಯೂಪ್ಲಿಕೇಶನ್, ಮತ್ತು ಪ್ರವೇಶ ನಿಯಂತ್ರಣ ಮ್ಯಾಪಿಂಗ್ ಎಲ್ಲವೂ ಸೂಚಿಕರಣ ಮೂಲಸೌಕರ್ಯವನ್ನು ಕಟ್ಟುವ ಮುನ್ನ ಸಂಭವಿಸಬೇಕು.
Chunking ಕಾರ್ಯತಂತ್ರವು ಎಲ್ಲ ಡೌನ್ಸ್ಟ್ರೀಮ್ಗಳನ್ನು ಪ್ರಭಾವಿಸುತ್ತದೆ
ಸೂಚಿಕರಣದ ಮುನ್ನ ಮೂಲ ದಾಖಲೆಗಳನ್ನು ಮರುಪಡೆಯಬಹುದಾದ ಘಟಕಗಳಾಗಿ ಹೇಗೆ ವಿಭಜಿಸಲಾಗುತ್ತದೆ ಎಂಬುದು RAG ವ್ಯವಸ್ಥೆಗಳನ್ನು ಕಟ್ಟಲು ಪ್ರಾರಂಭಿಸಿದಾಗ ಹೆಚ್ಚಿನ ತಂಡಗಳು ಅರಿತುಕೊಳ್ಳುವುದಕ್ಕಿಂತ ದೊಡ್ಡ ಪರಿಣಾಮವನ್ನು retrieval ಗುಣಮಟ್ಟದ ಮೇಲೆ ಬೀರುತ್ತದೆ. ತುಂಬಾ ಸಣ್ಣ chunkಗಳು ತಮ್ಮ ವಿಷಯವನ್ನು ಅರ್ಥಪೂರ್ಣವಾಗಿಸುವ ಸಂದರ್ಭೋಚಿತ ಮಾಹಿತಿಯನ್ನು ಕಳೆದುಕೊಳ್ಳುತ್ತವೆ. ತುಂಬಾ ದೊಡ್ಡ chunkಗಳು ಸಂಬಂಧಿತಕ್ಕಿಂತ ಹೆಚ್ಚು ಮರುಪಡೆಯುತ್ತವೆ ಮತ್ತು ಭಾಷಾ ಮಾದರಿಯು ನಿಖರ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸಲು ಬಳಸುವ ಸಂಕೇತವನ್ನು ತೆಳುಗೊಳಿಸುತ್ತವೆ. ಅತ್ಯುತ್ತಮ chunking ಕಾರ್ಯತಂತ್ರವು ಜ್ಞಾನ ಬೇಸ್ನಲ್ಲಿರುವ ದಸ್ತಾವೇಜು ಪ್ರಕಾರಗಳು, ವಿಶಿಷ್ಟ ಪ್ರಶ್ನೆಗಳ ಸ್ವರೂಪ, ಮತ್ತು ಬಳಸುತ್ತಿರುವ ಭಾಷಾ ಮಾದರಿಯ ಸಂದರ್ಭ ಕಿಟಕಿಯನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ.
ಬಳಕೆದಾರರಿಗೆ ನಿಯೋಜಿಸುವ ಮುನ್ನ ಪ್ರತಿನಿಧಿ ಪ್ರಶ್ನೆಗಳೊಂದಿಗೆ retrieval ಗುಣಮಟ್ಟವನ್ನು ಪರೀಕ್ಷಿಸುವುದು ಬಳಕೆದಾರರು ಅಸಮಂಜಸ ಪ್ರತಿಕ್ರಿಯೆ ಗುಣಮಟ್ಟವನ್ನು ಅನುಭವಿಸಿದ ನಂತರಕ್ಕಿಂತ ಬದಲಾಗಿ ಅವುಗಳನ್ನು ಇನ್ನೂ ಪರಿಹರಿಸಬಹುದಾದಾಗ chunking ಸಮಸ್ಯೆಗಳನ್ನು ಪ್ರಸ್ತುತಪಡಿಸುತ್ತದೆ.
RAG ಅನುಷ್ಠಾನ ವಿಧಾನಶಾಸ್ತ್ರದ ಬಗ್ಗೆ ಸಮಗ್ರ AI guide ಸಂಸ್ಥೆಗಳಿಗೆ ಅಭಿವೃದ್ಧಿಯ ಸಮಯದಲ್ಲಿ ಅತ್ಯಂತ ತಾಂತ್ರಿಕವಾಗಿ ಆಸಕ್ತಿದಾಯಕವಾಗಿರುವವುಗಳಿಗಿಂತ ಉತ್ಪಾದನಾ ಗುಣಮಟ್ಟವನ್ನು ಹೆಚ್ಚು ಪ್ರಭಾವಿಸುವ ನಿರ್ಧಾರಗಳ ಸುತ್ತ ತಮ್ಮ ನಿರ್ಮಾಣ ಪ್ರಕ್ರಿಯೆಯನ್ನು ರಚಿಸಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ.
ತಿಳಿಯಬೇಕಾದ ವಿಷಯಗಳು
ಸಂಸ್ಥೆಗಳು ಸಾಮಾನ್ಯವಾಗಿ ತಮ್ಮ ಮೊದಲ ನಿಯೋಜನೆಯ ಸಮಯದಲ್ಲಿ ಅಥವಾ ನಂತರ ಕಂಡುಕೊಳ್ಳುವ RAG AI ಬಗ್ಗೆ ಹಲವಾರು ಮುಖ್ಯ ವಾಸ್ತವಗಳು:
retrieval ಗುಣಮಟ್ಟ ಮತ್ತು ಉತ್ಪಾದನಾ ಗುಣಮಟ್ಟವು ಪ್ರತ್ಯೇಕ ಮೌಲ್ಯಮಾಪನ ಅಗತ್ಯವಿರುವ ಪ್ರತ್ಯೇಕ ಸಮಸ್ಯೆಗಳು. RAG ವ್ಯವಸ್ಥೆಯು ಸರಿಯಾದ ವಿಷಯವನ್ನು ಮರುಪಡೆಯಬಹುದು ಮತ್ತು ಕಳಪೆ ಸಂಯೋಜಿತ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸಬಹುದು, ಅಥವಾ ತಪ್ಪು ವಿಷಯವನ್ನು ಮರುಪಡೆಯಬಹುದು ಮತ್ತು ನಿಖರವಾಗಿ ತೋರುವ ಆದರೆ ಅಲ್ಲದ ನಿರರ್ಗಳ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸಬಹುದು. ಎಂಡ್-ಟು-ಎಂಡ್ ವ್ಯವಸ್ಥೆ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡುವ ಮುನ್ನ ಎರಡೂ ಘಟಕಗಳನ್ನು ಸ್ವತಂತ್ರವಾಗಿ ಪರೀಕ್ಷಿಸುವುದು ಸಮಸ್ಯೆಗಳು ನಿಜವಾಗಿ ಎಲ್ಲಿವೆ ಎಂದು ಗುರುತಿಸುತ್ತದೆ.
RAG hallucinationಅನ್ನು ತೆಗೆದುಹಾಕುವುದಿಲ್ಲ, ಅದನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ. ಮರುಪಡೆದ ಸಂದರ್ಭದಿಂದ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುವ ಭಾಷಾ ಮಾದರಿಯು ಇನ್ನೂ ಮರುಪಡೆದ ವಸ್ತುಗಳನ್ನು ತಪ್ಪಾಗಿ ಅರ್ಥೈಸುವ ಮೂಲಕ, ಮಾಹಿತಿಯನ್ನು ತಪ್ಪಾಗಿ ಸಂಯೋಜಿಸುವ ಮೂಲಕ, ಅಥವಾ ಮರುಪಡೆದ ಸಂದರ್ಭದಲ್ಲಿ ಇಲ್ಲದ ವಿವರಗಳನ್ನು ಉತ್ಪಾದಿಸುವ ಮೂಲಕ ತಪ್ಪಾದ ವಿಷಯವನ್ನು ಉತ್ಪಾದಿಸಬಹುದು. hallucination ಅಪಾಯವು ಒಳ್ಳೆಯ retrievalನೊಂದಿಗೆ ಅದಿಲ್ಲದಿರುವುದಕ್ಕಿಂತ ಗಣನೀಯವಾಗಿ ಕಡಿಮೆ, ಆದರೆ ಹೆಚ್ಚಿನ ಪಾಲನ್ನು ಹೊಂದಿರುವ ಅಪ್ಲಿಕೇಶನ್ಗಳಿಗೆ ಮಾನವ ಪರಿಶೀಲನೆ ಮುಖ್ಯವಾಗಿ ಉಳಿಯುತ್ತದೆ.
Embedding ಮಾದರಿ ಆಯ್ಕೆಯು retrieval ಗುಣಮಟ್ಟವನ್ನು ಗಮನಾರ್ಹವಾಗಿ ಪ್ರಭಾವಿಸುತ್ತದೆ. ವಿವಿಧ embedding ಮಾದರಿಗಳು ವಿವಿಧ ರೀತಿಯ ವಿಷಯದಲ್ಲಿ ಉತ್ತಮವಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತವೆ. ಸಾಮಾನ್ಯ ಪಠ್ಯ retrievalಗೆ ಅತ್ಯುತ್ತಮಗೊಳಿಸಿದ ಮಾದರಿಯು ತಾಂತ್ರಿಕ ದಸ್ತಾವೇಜು, ಕಾನೂನು ಭಾಷೆ, ಅಥವಾ ಡೊಮೇನ್-ನಿರ್ದಿಷ್ಟ ಪಾರಿಭಾಷಿಕದಲ್ಲಿ ಕಳಪೆಯಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸಬಹುದು. embedding ಮಾದರಿಗೆ ಬದ್ಧವಾಗುವ ಮುನ್ನ ನಿಮ್ಮ ನಿಜವಾದ ದಸ್ತಾವೇಜು ಪ್ರಕಾರಗಳು ಮತ್ತು ಪ್ರಶ್ನೆ ಮಾದರಿಗಳೊಂದಿಗೆ retrieval ಗುಣಮಟ್ಟವನ್ನು ಪರೀಕ್ಷಿಸುವುದು ನಂತರ ದುಬಾರಿ ಮರು-ವಾಸ್ತುಶಿಲ್ಪವನ್ನು ತಡೆಯುತ್ತದೆ.
ಜ್ಞಾನ ಬೇಸ್ ನಿರ್ವಹಣೆಯು ಒಂದು-ಬಾರಿಯ ಸೆಟಪ್ ಕಾರ್ಯವಲ್ಲ, ನಿರಂತರ ಕಾರ್ಯಾಚರಣಾ ಕಾರ್ಯ. ಮೂಲ ದಾಖಲೆಗಳು ನವೀಕರಿಸಲ್ಪಡುತ್ತಿರುವಂತೆ, ಹೊಸ ವಿಷಯ ಸೇರ್ಪಡೆಯಾಗುತ್ತಿರುವಂತೆ, ಮತ್ತು ಹಳೆಯ ವಿಷಯವು ತಪ್ಪು ಮಾರ್ಗದರ್ಶನ ನೀಡುತ್ತಿರುವಂತೆ, RAG ಜ್ಞಾನ ಬೇಸ್ ಅದಕ್ಕೆ ಅನುಗುಣವಾಗಿ ನವೀಕರಿಸಬೇಕು. ಆರಂಭಿಕ ಸೂಚಿಕರಣವನ್ನು ಜ್ಞಾನ ಬೇಸ್ ಕೆಲಸದ ಪೂರ್ಣಗೊಳಿಸುವಿಕೆ ಎಂದು ಪರಿಗಣಿಸುವ ಸಂಸ್ಥೆಗಳು ಸೂಚಿಕರಿಸಿದ ವಿಷಯ ಮತ್ತು ಪ್ರಸ್ತುತ ವಾಸ್ತವದ ನಡುವಿನ ಅಂತರ ವಿಸ್ತಾರಗೊಳ್ಳುವಂತೆ ನಿಖರತೆ ಕ್ಷೀಣಿಸುವ ವ್ಯವಸ್ಥೆಗಳೊಂದಿಗೆ ಕೊನೆಗೊಳ್ಳುತ್ತವೆ.
ಪ್ರವೇಶ ನಿಯಂತ್ರಣಗಳನ್ನು ಕೇವಲ ಜ್ಞಾನ ಬೇಸ್ ಸ್ವೀಕರಣದಲ್ಲಿ ಅಲ್ಲ, retrieval ಸಮಯದಲ್ಲಿ ಜಾರಿಗೊಳಿಸಬೇಕು. ಕೆಲವು ದಾಖಲೆಗಳನ್ನು ನೋಡಬಾರದ ಬಳಕೆದಾರನು ದಾಖಲೆಗಳು ವ್ಯವಸ್ಥೆಯಲ್ಲಿ ಸೂಚಿಕರಿಸಲ್ಪಟ್ಟಿದ್ದರೂ ಸಹ ಆ ದಾಖಲೆಗಳಲ್ಲಿ ಆಧಾರಿತವಾದ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಪಡೆಯಬಾರದು. Retrieval-ಸಮಯದ ಅನುಮತಿ ಜಾರಿಯು ಸುರಕ್ಷತಾ ಅವಶ್ಯಕತೆ, ಐಚ್ಛಿಕ ವರ್ಧನೆಯಲ್ಲ.
30% ನಿಯಮವು RAG ನಿಯೋಜನಾ ಯೋಜನೆಗೆ ಉಪಯುಕ್ತವಾಗಿ ಅನ್ವಯಿಸುತ್ತದೆ. AI retrieval ಮತ್ತು ಸಂಯೋಜನೆಯು ಜ್ಞಾನ ಕೆಲಸದ ಸುಮಾರು 30%, ಲುಕಪ್ ಮತ್ತು ಸಂಯೋಜನಾ ಘಟಕವನ್ನು ನಿಭಾಯಿಸಬೇಕು, ಆದರೆ ಮಾನವ ಪರಿಣತಿಯು ಉಳಿದ 70%ಅನ್ನು ಒಳಗೊಂಡಿರುವ ತೀರ್ಪು, ಅರ್ಥವಿವರಣೆ, ಮತ್ತು ಪರಿಣಾಮಕಾರಿ ನಿರ್ಧಾರ-ತೆಗೆದುಕೊಳ್ಳುವಿಕೆಯನ್ನು ನಿಭಾಯಿಸುತ್ತದೆ. ಈ ಸಮತೋಲನದ ಸುತ್ತ RAG ನಿಯೋಜನೆಗಳನ್ನು ವಿನ್ಯಾಸಗೊಳಿಸುವುದು ಜನರೊಂದಿಗೆ ಇನ್ನೂ ಉಳಿಯಬೇಕಾದ ತೀರ್ಪನ್ನು ಬದಲಿಸಲು ಪ್ರಯತ್ನಿಸುವ ಬದಲು ನಿಜವಾಗಿ ಮಾನವ ಜ್ಞಾನ ಕೆಲಸವನ್ನು ಹೆಚ್ಚಿಸುವ ವ್ಯವಸ್ಥೆಗಳನ್ನು ಸೃಷ್ಟಿಸುತ್ತದೆ.
RAG AI ವ್ಯವಹಾರ AIಗೆ ಪ್ರಮಾಣಿತ ವಾಸ್ತುಶಿಲ್ಪವಾಗುತ್ತಿರುವುದೇಕೆ
ಎಂಟರ್ಪ್ರೈಸ್ AI ಅಳವಡಿಕೆಯ ವಿಶಾಲ ಸಂದರ್ಭದಲ್ಲಿ RAG AI ಏನು? ಇದು ವ್ಯವಹಾರಗಳಿಗೆ ನಿಜವಾಗಿ AI ನಿಭಾಯಿಸಲು ಬೇಕಾದ ನಿರ್ದಿಷ್ಟ, ಪ್ರಸ್ತುತ, ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನ ಕಾರ್ಯಗಳಿಗೆ ಭಾಷಾ ಮಾದರಿಗಳನ್ನು ಪ್ರಾಯೋಗಿಕವಾಗಿ ಉಪಯುಕ್ತವಾಗಿಸುವ ವಾಸ್ತುಶಿಲ್ಪೀಯ ಮಾದರಿ. ಭಾಷಾ ಮಾದರಿಯ ತಾರ್ಕಿಕವಾಗಿ, ಸಂಯೋಜಿಸಲು, ಮತ್ತು ಸ್ವಾಭಾವಿಕ ಭಾಷೆಯಲ್ಲಿ ಸಂವಹನ ಮಾಡುವ ಸಾಮರ್ಥ್ಯವನ್ನು ಪ್ರಸ್ತುತ, ನಿರ್ದಿಷ್ಟ, ಪರಿಶೀಲನಾರ್ಹ ಮಾಹಿತಿಗೆ retrieval ವ್ಯವಸ್ಥೆಯ ಪ್ರವೇಶದೊಂದಿಗೆ ಸಂಯೋಜಿಸುವುದು ಎರಡೂ ಘಟಕಗಳು ಒಂದೇ ತಲುಪಿಸಲಾಗದನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ.
ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಭಾಷಾ ಮಾದರಿಗಳನ್ನು ನಿಯೋಜಿಸಿ hallucinationಗಳು, ಹಳೆಯ ಜ್ಞಾನ, ಮತ್ತು ಕಂಪನಿ-ನಿರ್ದಿಷ್ಟ ಪ್ರಶ್ನೆಗಳನ್ನು ನಿಭಾಯಿಸಲು ಅಸಮರ್ಥತೆಯಿಂದ ನಿರಾಶೆಗೊಂಡ ಸಂಸ್ಥೆಗಳು ಸಾಮಾನ್ಯವಾಗಿ ಸರಿಯಾದ ತಂತ್ರಜ್ಞಾನವನ್ನು ತಪ್ಪು ವಾಸ್ತುಶಿಲ್ಪದಲ್ಲಿ ನಿಯೋಜಿಸುತ್ತಿವೆ. ಅದೇ ಮಾದರಿಗಳು, ಚೆನ್ನಾಗಿ ನಿರ್ವಹಿಸಿದ ಜ್ಞಾನ ಬೇಸ್ಗಳ ಮೇಲೆ ಚೆನ್ನಾಗಿ ಕಟ್ಟಲಾದ retrieval ಪೈಪ್ಲೈನ್ಗಳಿಗೆ ಸಂಪರ್ಕಿತವಾದಾಗ, ನಾಟಕೀಯವಾಗಿ ವಿಭಿನ್ನ ಮತ್ತು ನಾಟಕೀಯವಾಗಿ ಹೆಚ್ಚು ಉಪಯುಕ್ತ ಫಲಿತಾಂಶಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತವೆ.
RAG ವ್ಯವಸ್ಥೆಗಳನ್ನು ಕಟ್ಟಲು ತಾಂತ್ರಿಕ ತಡೆಯು ಕಳೆದ ಎರಡು ವರ್ಷಗಳಲ್ಲಿ ಗಮನಾರ್ಹವಾಗಿ ಕಡಿಮೆಯಾಗಿದೆ. RAGಅನ್ನು ಪ್ರಾಯೋಗಿಕವಾಗಿಸುವ frameworkಗಳು, vector databaseಗಳು, ಮತ್ತು ಹೋಸ್ಟ್ ಮಾಡಿದ retrieval ಮೂಲಸೌಕರ್ಯವು ಪ್ರೌಢ, ಚೆನ್ನಾಗಿ ದಾಖಲಿಸಿದ, ಮತ್ತು ವಿಶೇಷ AI ಸಂಶೋಧನಾ ಹಿನ್ನೆಲೆಯಿಲ್ಲದ ಎಂಜಿನಿಯರಿಂಗ್ ತಂಡಗಳಿಗೆ ಪ್ರವೇಶಿಸಬಹುದಾಗಿದೆ. ಯಶಸ್ವಿ RAG ನಿಯೋಜನೆಗಳನ್ನು ನಿರಾಶಾದಾಯಕವಾದವುಗಳಿಂದ ಬೇರ್ಪಡಿಸುವುದು ತಾಂತ್ರಿಕ ಸೂಕ್ಷ್ಮತೆಯಲ್ಲ ಬದಲಾಗಿ ಜ್ಞಾನ ಬೇಸ್ಗಳನ್ನು ಸರಿಯಾಗಿ ಸಿದ್ಧಪಡಿಸುವ, retrieval ಗುಣಮಟ್ಟವನ್ನು ಕಠಿಣವಾಗಿ ಮೌಲ್ಯಮಾಪನ ಮಾಡುವ, ಮತ್ತು ವ್ಯವಸ್ಥೆಯನ್ನು ಪೂರ್ಣಗೊಳಿಸಿದ ಪ್ರಾಜೆಕ್ಟ್ಗಿಂತ ಜೀವಂತ ಕಾರ್ಯಾಚರಣಾ ಸಂಪತ್ತಾಗಿ ನಿರ್ವಹಿಸುವ ಸಾಂಸ್ಥಿಕ ಶಿಸ್ತು.
ಆಗಾಗ್ಗೆ ಕೇಳುವ ಪ್ರಶ್ನೆಗಳು
GPT ಮತ್ತು RAG ನಡುವಿನ ವ್ಯತ್ಯಾಸವೇನು?
GPT ಎನ್ನುವುದು ತರಬೇತಿಯ ಸಮಯದಲ್ಲಿ ಕಲಿತ ಮಾದರಿಗಳ ಆಧಾರದ ಮೇಲೆ ಸಂಪೂರ್ಣವಾಗಿ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವ large language modelನ ಒಂದು ಪ್ರಕಾರ, ಆದರೆ RAG ಎನ್ನುವುದು ಪ್ರತಿಕ್ರಿಯೆ ಸಮಯದಲ್ಲಿ ಮಾದರಿಯ ಸಂದರ್ಭದಲ್ಲಿ ಮರುಪಡೆಯಲಾಗುವ ಮತ್ತು ಸೇರಿಸಲಾಗುವ ಬಾಹ್ಯ ಜ್ಞಾನ ಮೂಲಗಳಿಗೆ GPT ಸೇರಿದಂತೆ ಯಾವುದೇ ಭಾಷಾ ಮಾದರಿಯನ್ನು ಸಂಪರ್ಕಿಸುವ ವಾಸ್ತುಶಿಲ್ಪೀಯ ವಿಧಾನ. retrieval ಇಲ್ಲದ GPT ಕೇವಲ ತರಬೇತಿ ಡೇಟಾದಿಂದ ಉತ್ತರಿಸುತ್ತದೆ, ಆದರೆ GPT-ಆಧಾರಿತ RAG ವ್ಯವಸ್ಥೆಯು ತನ್ನ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುವ ಮುನ್ನ ಸಂಬಂಧಿತ ಪ್ರಸ್ತುತ ಮಾಹಿತಿಯನ್ನು ಮರುಪಡೆಯುತ್ತದೆ, ತರಬೇತಿ ಡೇಟಾ ಸಾಮಾನ್ಯೀಕರಣಗಳಿಗಿಂತ ನಿರ್ದಿಷ್ಟ, ಪರಿಶೀಲನಾರ್ಹ ಮೂಲಗಳಲ್ಲಿ ಆಧಾರಿತವಾದ ಉತ್ತರಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ.
RAG ಮತ್ತು generative AI ನಡುವಿನ ವ್ಯತ್ಯಾಸವೇನು?
Generative AI ಎನ್ನುವುದು ಪಠ್ಯ, ಚಿತ್ರಗಳು, ಮತ್ತು ಆಡಿಯೋ ಸೇರಿದಂತೆ ಹೊಸ ವಿಷಯವನ್ನು ಉತ್ಪಾದಿಸುವ AI ವ್ಯವಸ್ಥೆಗಳ ವಿಶಾಲ ವರ್ಗ, ಆದರೆ RAG ಎನ್ನುವುದು ಮಾದರಿಯು ತನ್ನ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಉತ್ಪಾದಿಸುವ ಮುನ್ನ ಬಾಹ್ಯ ಮೂಲಗಳಿಂದ ಸಂಬಂಧಿತ ಮಾಹಿತಿಯನ್ನು ಎಳೆಯುವ retrieval ಹೆಜ್ಜೆಯೊಂದಿಗೆ ಉತ್ಪಾದನೆಯನ್ನು ವರ್ಧಿಸುವ ಪಠ್ಯ-ಉತ್ಪಾದಿಸುವ AIಗೆ ಅನ್ವಯಿಸುವ ನಿರ್ದಿಷ್ಟ ತಂತ್ರ. ಎಲ್ಲ RAG ವ್ಯವಸ್ಥೆಗಳು generative AI, ಆದರೆ ಹೆಚ್ಚಿನ generative AI ವ್ಯವಸ್ಥೆಗಳು RAG ವ್ಯವಸ್ಥೆಗಳಲ್ಲ. RAG ಎನ್ನುವುದು ಜ್ಞಾನ-ತೀವ್ರ ಕಾರ್ಯಗಳಿಗೆ generative AIಯನ್ನು ಹೆಚ್ಚು ನಿಖರ ಮತ್ತು ಪ್ರಸ್ತುತವಾಗಿಸುವ ವಾಸ್ತುಶಿಲ್ಪೀಯ ವರ್ಧನೆ.
RAG vs LLM ಎಂದರೇನು?
LLM ಎನ್ನುವುದು ತರಬೇತಿ ಡೇಟಾದ ಆಧಾರದ ಮೇಲೆ ಪಠ್ಯವನ್ನು ಉತ್ಪಾದಿಸುವ ಭಾಷಾ ಮಾದರಿ, ಆದರೆ RAG ಎನ್ನುವುದು ಮಾದರಿಯು ಕೇವಲ ತರಬೇತಿ ಡೇಟಾದ ಬದಲು ಮರುಪಡೆದ ದಾಖಲೆಗಳಲ್ಲಿ ಆಧಾರಿತ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವಂತೆ LLM ಅನ್ನು retrieval ವ್ಯವಸ್ಥೆಯೊಂದಿಗೆ ಜೋಡಿಸುವ ವಾಸ್ತುಶಿಲ್ಪ. RAG ವ್ಯವಸ್ಥೆಯಲ್ಲಿ LLM ಭಾಷಾ ಗ್ರಹಿಕೆ ಮತ್ತು ಉತ್ಪಾದನೆಯನ್ನು ನಿಭಾಯಿಸುತ್ತದೆ, retrieval ಘಟಕವು ಪ್ರತಿ ಪ್ರಶ್ನೆಗೆ ಸಂಬಂಧಿತ ಪ್ರಸ್ತುತ, ನಿರ್ದಿಷ್ಟ ಮಾಹಿತಿಯನ್ನು ಹುಡುಕುವುದನ್ನು ನಿಭಾಯಿಸುತ್ತದೆ. ಒಟ್ಟಾಗಿ ಅವು ಪ್ರತಿ ಘಟಕ ಸ್ವತಂತ್ರವಾಗಿ ಉತ್ಪಾದಿಸುವುದಕ್ಕಿಂತ ಹೆಚ್ಚು ನಿಖರ, ಪರಿಶೀಲನಾರ್ಹ, ಮತ್ತು ಸಾಂಸ್ಥಿಕವಾಗಿ ಸಂಬಂಧಿತ ಔಟ್ಪುಟ್ಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತವೆ.
RAG ಯಾವ ಸಮಸ್ಯೆಗಳನ್ನು ಪರಿಹರಿಸುತ್ತದೆ?
RAG ಮುಖ್ಯವಾಗಿ ಮೂರು ಸಮಸ್ಯೆಗಳನ್ನು ಪರಿಹರಿಸುತ್ತದೆ: ಇತ್ತೀಚಿನ ಘಟನೆಗಳು ಅಥವಾ ಪ್ರಸ್ತುತ ಮಾಹಿತಿಯ ಬಗ್ಗೆ ಪ್ರಶ್ನೆಗಳಿಗೆ ಉತ್ತರಿಸಲು ಸ್ಟ್ಯಾಂಡರ್ಡ್ LLMಗಳನ್ನು ಅಸಮರ್ಥವಾಗಿಸುವ ತರಬೇತಿ ಕಟ್ಆಫ್ ಮಿತಿ, ಸಾರ್ವಜನಿಕ ತರಬೇತಿ ಡೇಟಾದಲ್ಲಿ ಎಂದಿಗೂ ಇಲ್ಲದ ಸ್ವಂತ ಸಾಂಸ್ಥಿಕ ಜ್ಞಾನದ ಬಗ್ಗೆ ತಿಳಿಯದಂತೆ ಮಾದರಿಗಳನ್ನು ತಡೆಯುವ ವ್ಯಾಪ್ತಿ ಮಿತಿ, ಮತ್ತು ಪ್ರಶ್ನೆಯು ಅಗತ್ಯವಿರುವ ನಿರ್ದಿಷ್ಟ ಜ್ಞಾನವನ್ನು ಹೊಂದಿಲ್ಲದಿರುವಾಗ ಮಾದರಿಗಳು ಸಮಂಜಸ ಆದರೆ ತಪ್ಪಾದ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವ hallucination ಸಮಸ್ಯೆ. ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಉತ್ಪಾದಿಸುವ ಮುನ್ನ ಸಂಬಂಧಿತ ವಿಷಯವನ್ನು ಮರುಪಡೆಯುವ ಮೂಲಕ, RAG AI ಔಟ್ಪುಟ್ಗಳನ್ನು ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ಮಾದರಿಗಳ ಬದಲು ಪರಿಶೀಲನಾರ್ಹ ಮೂಲಗಳಲ್ಲಿ ಆಧಾರಿತಗೊಳಿಸುತ್ತದೆ, ವ್ಯವಹಾರ-ನಿರ್ಣಾಯಕ ಅಪ್ಲಿಕೇಶನ್ಗಳಿಗೆ ಪರಿಶೀಲಿಸಬಹುದಾದ, ಉಲ್ಲೇಖಿಸಬಹುದಾದ, ಮತ್ತು ನಂಬಬಹುದಾದ ಉತ್ತರಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ.
AI ನಿಂದ ಯಾವ 3 ಉದ್ಯೋಗಗಳು ಉಳಿಯುತ್ತವೆ?
AI ಸ್ಥಾನಪಲ್ಲಟನೆಗೆ ಅತ್ಯಂತ ಪ್ರತಿರೋಧಕ ಮೂರು ಕೆಲಸ ವರ್ಗಗಳೆಂದರೆ ಅಸಂರಚಿತ ಪರಿಸರಗಳಲ್ಲಿ ಭೌತಿಕ ಪ್ರಪಂಚದ ಸಂವಹನ ಮತ್ತು ಕೌಶಲ್ಯ ಅಗತ್ಯವಿರುವ ಪಾತ್ರಗಳು, ಸಂಕೀರ್ಣ ಮಾನವ ತೀರ್ಪು, ನೈತಿಕ ತಾರ್ಕಿಕತೆ, ಮತ್ತು ಪರಿಣಾಮಕಾರಿ ನಿರ್ಧಾರಗಳಿಗೆ ಜವಾಬ್ದಾರಿಯನ್ನು ಕೇಂದ್ರೀಕರಿಸಿದ ಪಾತ್ರಗಳು, ಮತ್ತು ಪರಸ್ಪರ ನಂಬಿಕೆ, ಭಾವನಾತ್ಮಕ ಬುದ್ಧಿಶಕ್ತಿ, ಮತ್ತು ಸಂಬಂಧ ನಿರ್ವಹಣೆಯ ಸುತ್ತ ಕಟ್ಟಿದ ಪಾತ್ರಗಳು. RAG AI ಮತ್ತು ಸಮಾನ ವ್ಯವಸ್ಥೆಗಳು ಜ್ಞಾನ retrieval ಮತ್ತು ಸಂಯೋಜನೆಯನ್ನು ಹೆಚ್ಚು ಸ್ವಯಂಚಾಲಿತಗೊಳಿಸಬಹುದಾಗಿಸುತ್ತಿವೆ, ಇದು AI ಈಗ ಹೆಚ್ಚು ಪರಿಣಾಮಕಾರಿಯಾಗಿ ನಿಭಾಯಿಸುವ ಮಾಹಿತಿ ಪ್ರಕ್ರಿಯೆ ಕಾರ್ಯಗಳ ಬದಲು ಈ ಪಾತ್ರಗಳು ಅವಲಂಬಿಸಿರುವ ಸ್ಪಷ್ಟವಾಗಿ ಮಾನವ ಸಾಮರ್ಥ್ಯಗಳ ಮೌಲ್ಯವನ್ನು ಬಲಪಡಿಸುತ್ತದೆ.