
RAG AI کیا ہے؟ Retrieval-Augmented Generation ایک تکنیک ہے جو ایک large language model کو جواب پیدا کرتے وقت کسی بیرونی علم کے ذریعے سے جوڑتی ہے، جس سے ماڈل تربیت کے دوران سیکھی گئی چیزوں پر مکمل انحصار کرنے کے بجائے موجودہ، مخصوص اور قابلِ تصدیق معلومات کو حاصل کرنے کے قابل ہوتا ہے۔ نتیجہ ایک AI نظام ہے جو عمومی تخمینوں کی بجائے حقیقی ڈیٹا کے ساتھ سوالات کا جواب دیتا ہے۔
اگر آپ نے کبھی کسی معیاری AI اسسٹنٹ سے اپنی کمپنی کے اندرونی عمل کے بارے میں سوال پوچھا ہو اور ایسا جواب ملا ہو جو مناسب لگتا تھا لیکن مکمل طور پر گھڑا ہوا تھا، تو آپ نے اس بنیادی حد کا تجربہ کیا ہے جسے RAG حل کرنے کے لیے ڈیزائن کیا گیا تھا۔ لینگویج ماڈلز کو ایک طے شدہ وقت تک کے ڈیٹا پر تربیت دی جاتی ہے۔ وہ آپ کی اپنی دستاویزات، آپ کے موجودہ انوینٹری، آپ کی تازہ ترین پالیسیوں، یا کسی بھی ایسی چیز کے بارے میں کچھ نہیں جانتے جو ان کی تربیتی حد کے بعد ہوئی۔ RAG اس بنیادی حد کو تبدیل کرتا ہے ماڈل کو جواب دینے سے پہلے چیزیں تلاش کرنے کا ایک طریقہ کار فراہم کر کے، اسی طرح جیسے ایک اچھی طرح تیار کردہ تجزیہ کار مشورہ دینے سے پہلے ذرائع کی دستاویزات سے رجوع کرتا ہے بجائے اس کے کہ مکمل طور پر حافظہ سے کام کرے۔ ان کاروباروں کے لیے جو ان سیاق و سباق میں AI تعینات کر رہے ہیں جہاں درستگی اور خصوصیت اہمیت رکھتی ہے، RAG AI کیا ہے اور یہ کیسے کام کرتا ہے کو سمجھنا کوئی تکنیکی شائستگی نہیں ہے۔ یہ ایک ایسے AI میں فرق ہے جو واقعی مدد کرتا ہے اور وہ جو اعتماد کے ساتھ قابلِ یقین بکواس پیدا کرتا ہے۔

معیاری لینگویج ماڈلز کو بنیادی علم کا مسئلہ کیوں ہے
تربیتی کٹ آف کی حد
آج موجود ہر large language model کو ایک متعین اختتامی تاریخ کے ساتھ ایک ڈیٹا سیٹ پر تربیت دی گئی تھی۔ اس تاریخ کے بعد جو کچھ بھی ہوا، ہر پالیسی تبدیلی، ہر پروڈکٹ اپڈیٹ، ہر ریگولیٹری ترقی، تنظیمی علم کا ہر ٹکڑا جو ماڈل کی تربیت کے بعد سے بنایا گیا، اس کے لیے پوشیدہ ہے۔ عمومی علم کے کاموں کے لیے یہ حد قابلِ انتظام ہے کیونکہ بنیادی علم آہستہ آہستہ تبدیل ہوتا ہے۔ ان کاروباری ایپلی کیشنز کے لیے جہاں موجودہ، مخصوص معلومات پر درستگی پورا نکتہ ہے، یہ ایک سنگین آپریشنل مسئلہ ہے۔
دوسری حد دائرہ کار ہے۔ یہاں تک کہ سب سے بڑے لینگویج ماڈلز جو ممکنہ طور پر سب سے وسیع ڈیٹا سیٹس پر تربیت یافتہ ہیں، ان کے پاس ان معلومات کا کوئی علم نہیں ہے جو ان کے تربیتی ڈیٹا میں کبھی نہیں تھیں۔ آپ کی کمپنی کا اندرونی علم کا ڈیٹا بیس، آپ کے کسٹمر کنٹریکٹس، آپ کی تکنیکی دستاویزات، آپ کے قیمتوں کے ڈھانچے، اور آپ کے آپریشنل طریقہ کار تقریباً یقینی طور پر کسی عوامی تربیتی ڈیٹا سیٹ میں کبھی نہیں تھے۔ ان موضوعات پر سوالات کا جواب دینے والا ماڈل وہ معلومات حاصل نہیں کر رہا جو وہ جانتا ہے۔ یہ اپنی تربیت میں موجود نمونوں کی بنیاد پر جواب کی طرح آواز نکالنے والا متن پیدا کر رہا ہے، ایک ایسا عمل جو روان، اعتماد سے بھرپور جوابات پیدا کرتا ہے جن کا اصل حقائق سے کوئی تعلق نہیں ہو سکتا۔
اس رجحان کا AI ریسرچ میں ایک نام ہے: hallucination۔ یہ لینگویج ماڈلز کے اس رجحان کی وضاحت کرتا ہے کہ وہ درست معلومات کی طرح اعتماد سے بھرپور لہجے کے ساتھ پیش کی گئی حقائق کے لحاظ سے غلط معلومات پیدا کرتے ہیں۔ غیر رسمی استعمال کے معاملات کے لیے، hallucination ایک تکلیف ہے۔ قانونی، طبی، مالی، یا آپریشنل سیاق و سباق میں کاروباری ایپلی کیشنز کے لیے، یہ ایک ذمہ داری ہے۔
RAG دونوں مسائل کو ایک ساتھ کیسے حل کرتا ہے
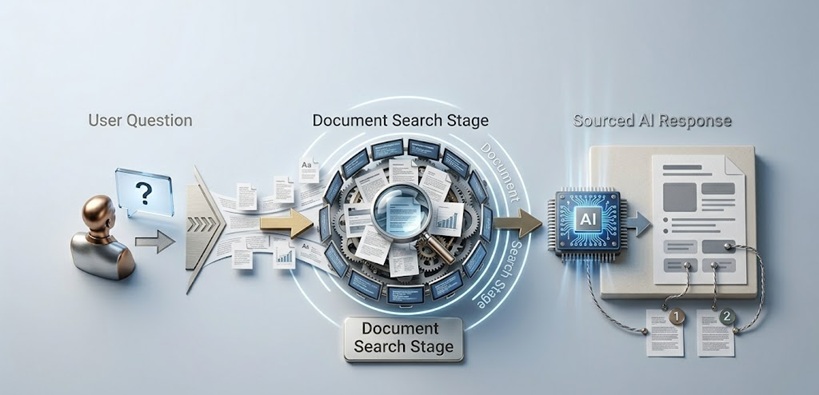
RAG AI خاص طور پر کیا حل کر رہا ہے؟ یہ ایک ہی آرکیٹیکچرل اضافے کے ساتھ کٹ آف کے مسئلے اور دائرہ کار کے مسئلے دونوں کو حل کرتا ہے۔ ماڈل سے صرف تربیتی ڈیٹا سے جواب دینے کو کہنے کے بجائے، RAG سسٹمز کوئری کے وقت بیرونی ذریعے سے متعلقہ دستاویزات یا ڈیٹا حاصل کرتے ہیں اور اس حاصل کردہ مواد کو سیاق و سباق میں شامل کرتے ہیں جسے ماڈل اپنا جواب پیدا کرنے کے لیے استعمال کرتا ہے۔
ماڈل اندازہ نہیں لگا رہا کہ آپ کی واپسی کی پالیسی کیا کہتی ہے۔ اس نے جواب دینے سے پہلے اصل پالیسی دستاویز حاصل کی۔ یہ اندازہ نہیں لگا رہا کہ آپ کے Q3 ریونیو کے اعداد و شمار کیا تھے۔ اس نے جواب دینے سے پہلے آپ کے مالیاتی نظام سے اصل اعداد و شمار حاصل کیے۔ ماڈل کا کردار واحد علم کے ذریعے سے ذہین حاصل شدہ معلومات کے ترکیب کار میں تبدیل ہو جاتا ہے، جو ایک ایسا کام ہے جو لینگویج ماڈلز غیر معمولی طور پر اچھی طرح کرتے ہیں۔
اس آرکیٹیکچرل تبدیلی کے اثرات hallucinations کو ٹھیک کرنے سے کہیں زیادہ ہیں۔ اس کا مطلب ہے کہ AI سسٹمز کو اپنے ماڈلز کو دوبارہ تربیت دینے کے بجائے اپنے علم کے ذرائع کو اپڈیٹ کر کے اپڈیٹ کیا جا سکتا ہے۔ اس کا مطلب ہے کہ جوابات اپنے ذرائع کا حوالہ دے سکتے ہیں، جس سے تصدیق کا عمل سادہ ہو جاتا ہے۔ اور اس کا مطلب ہے کہ تنظیمیں واقعی حساس اندرونی علم تک رسائی کے ساتھ AI سسٹمز بنا سکتی ہیں بغیر اس علم کے کبھی تربیتی ڈیٹا سیٹ میں شامل کیے جانے کی ضرورت کے۔
RAG AI دراصل کیسے کام کرتا ہے
Retrieval Pipeline کی وضاحت
ایک RAG سسٹم میں دو بڑے اجزاء ہوتے ہیں جو لینگویج ماڈل کے اپنے جواب کا ایک لفظ بھی پیدا کرنے سے پہلے ترتیب میں کام کرتے ہیں۔
پہلا جزو علم کا ڈیٹا بیس اور اس کا انڈیکسنگ انفراسٹرکچر ہے۔ دستاویزات، ریکارڈز، ویب پیجز، ڈیٹا بیس کے اندراجات، یا کوئی بھی دوسری معلومات جس پر AI کو انحصار کرنے کے قابل ہونا چاہیے، اس طرح پروسیس اور اسٹور کی جاتی ہیں جو انہیں صرف کلیدی الفاظ کے بجائے معنی کے لحاظ سے قابلِ تلاش بناتا ہے۔ اس میں عام طور پر متن کو embeddings نامی عددی نمائندگیوں میں تبدیل کرنا شامل ہوتا ہے، جو معنوی معنی کو ایسی شکل میں پکڑتے ہیں جو ریاضیاتی طور پر ملتے جلتے مواد کو ایک ساتھ حاصل کرنے کی اجازت دیتا ہے۔ کسٹمر کی واپسی کے عمل کے بارے میں ایک سوال واپسی، تبادلے، اور اطمینان کی ضمانتوں کے بارے میں مواد حاصل کرتا ہے یہاں تک کہ اگر وہ صحیح الفاظ کوئری میں ظاہر نہ ہوں۔
دوسرا جزو retrieval میکانزم ہے جو جب صارف کوئری جمع کراتا ہے تو فعال ہوتا ہے۔ کوئری کو محفوظ شدہ دستاویزات کی طرح اسی embedding فارمیٹ میں تبدیل کیا جاتا ہے، اور سسٹم اس محفوظ شدہ مواد کی شناخت کرتا ہے جو کوئری سے سب سے زیادہ معنوی طور پر ملتا جلتا ہے۔ وہ حاصل کردہ مواد، گزرگاہیں، دستاویزات، یا ریکارڈز جو پوچھے گئے سوال سے سب سے زیادہ متعلقہ ہیں، اصل کوئری کے ساتھ لینگویج ماڈل کو جمع کر کے پاس کیا جاتا ہے۔
پھر لینگویج ماڈل اس حاصل کردہ سیاق و سباق پر مبنی ایک جواب پیدا کرتا ہے بجائے اس کے کہ مطلوبہ مخصوص حقائق کے لیے اپنے تربیتی ڈیٹا پر انحصار کرے۔ تربیتی ڈیٹا اب بھی ماڈل کی زبان کی صلاحیت، اس کی استدلال کی صلاحیت، اور اس کے عمومی دنیاوی علم کے لیے اہم ہے۔ لیکن جواب کا مخصوص حقیقی مواد حاصل کردہ مواد سے آتا ہے۔
| RAG System Component | یہ کیا کرتا ہے | یہ کیوں اہم ہے |
|---|---|---|
| Document Ingestion | انڈیکسنگ کے لیے ذرائع کی دستاویزات کو پروسیس اور chunks میں تقسیم کرتا ہے | یہ طے کرتا ہے کہ سسٹم کس علم تک رسائی حاصل کر سکتا ہے |
| Embedding Model | متن کو معنوی ویکٹر نمائندگیوں میں تبدیل کرتا ہے | کلیدی لفظ ملاپ کی بجائے معنی پر مبنی retrieval کو ممکن بناتا ہے |
| Vector Database | تیز مماثلت کی تلاش کے لیے embeddings کو اسٹور کرتا ہے | retrieval کو حقیقی وقت کے استعمال کے لیے کافی تیز بناتا ہے |
| Retrieval Mechanism | ہر کوئری کے لیے سب سے زیادہ متعلقہ مواد کی شناخت کرتا ہے | حاصل کردہ سیاق و سباق کی درستگی کا تعین کرتا ہے |
| Language Model | حاصل کردہ مواد پر مبنی جواب پیدا کرتا ہے | حاصل کردہ حقائق سے مربوط، ترکیب شدہ آؤٹ پٹ پیدا کرتا ہے |
| Source Attribution | ٹریک کرتا ہے کہ کن دستاویزات نے ہر جواب کو مطلع کیا | تصدیق کو ممکن بناتا ہے اور صارف کے اعتماد کو بناتا ہے |
یہ سمجھنا کہ RAG pipelines میں AI architecture کے فیصلے retrieval کے معیار اور جواب کی درستگی دونوں کو کیسے متاثر کرتے ہیں، تنظیموں کو ایسے سسٹمز بنانے میں مدد دیتا ہے جو مظاہروں میں اچھے اور پروڈکشن میں متضاد کی بجائے قابلِ اعتماد طور پر کارکردگی دکھائیں۔
RAG بمقابلہ معیاری LLM: عمل میں فرق کہاں ظاہر ہوتا ہے
RAG AI کیا ہے اور معیاری LLM کیا کرتا ہے کے درمیان فرق ان مخصوص منظرناموں میں سب سے زیادہ نظر آتا ہے جہاں معیاری ماڈلز ناکام ہوتے ہیں اور RAG سسٹمز کامیاب ہوتے ہیں۔
آپ کی تنظیم کی موجودہ ڈیٹا برقرار رکھنے کی پالیسی کے بارے میں پوچھا گیا ایک معیاری LLM اپنے تربیتی ڈیٹا سے عمومی ڈیٹا برقرار رکھنے کی پریکٹسز کی بنیاد پر جواب پیدا کرتا ہے۔ یہ بالکل صحیح لگ سکتا ہے۔ یہ تقریباً یقینی طور پر آپ کی اصل پالیسی کو بیان نہیں کر رہا ہے۔ ایک RAG سسٹم جسے یہی سوال پوچھا گیا ہے وہ آپ کی اصل پالیسی دستاویز حاصل کرتا ہے اور اس بات پر مبنی جواب پیدا کرتا ہے کہ وہ دستاویز کیا کہتی ہے۔ زبان ملتی جلتی ہے۔ درستگی کیٹیگری کے لحاظ سے مختلف ہے۔
کل جمع کرائی گئی کسٹمر شکایت کے بارے میں پوچھا گیا ایک معیاری LLM کو اندازہ نہیں ہے کہ آپ کس بارے میں بات کر رہے ہیں۔ شکایت اس کی تربیت کے بعد کی ہے۔ آپ کے CRM سے منسلک ایک RAG سسٹم شکایت کا ریکارڈ حاصل کرتا ہے اور ایک ایسا جواب پیدا کرتا ہے جو اس مخصوص کسٹمر کی صورتحال کی اصل تفصیلات کو ظاہر کرتا ہے۔
آپ نے اپ لوڈ کی گئی ایک تحقیقی رپورٹ سے کلیدی نتائج کا خلاصہ کرنے کے لیے کہا گیا ایک معیاری LLM ایک قابلِ یقین خلاصہ پیدا کر سکتا ہے جو اہم نتائج کو چھوڑ دیتا ہے، نتائج کو غلط طریقے سے پیش کرتا ہے، یا دستاویز کے مختلف حصوں سے تفصیلات کو غلط طریقے سے جوڑتا ہے۔ ایک RAG سسٹم خلاصہ درخواست کے لیے سب سے زیادہ متعلقہ مخصوص حصوں کو حاصل کرتا ہے اور اصل متن پر مبنی آؤٹ پٹ پیدا کرتا ہے۔
| منظرنامہ | معیاری LLM کا جواب | RAG AI کا جواب |
|---|---|---|
| اندرونی پالیسی کا سوال | قابلِ یقین عمومی جواب پیدا کرتا ہے جو آپ کی پالیسیوں کے لیے مخصوص نہیں | اصل پالیسی دستاویز حاصل کرتا ہے، اس کے مواد سے جواب دیتا ہے |
| حالیہ واقعہ کے بارے میں سوال | کہتا ہے کہ اس کے پاس کوئی معلومات نہیں ہے یا فرسودہ جواب پیدا کرتا ہے | منسلک علم کے ڈیٹا بیس سے موجودہ معلومات حاصل کرتا ہے |
| کسٹمر مخصوص استفسار | انفرادی کسٹمر ڈیٹا تک رسائی حاصل نہیں کر سکتا | متعلقہ کسٹمر ریکارڈز حاصل کرتا ہے اور درستگی سے جواب دیتا ہے |
| تکنیکی دستاویزات کا سوال | تکنیکی تفصیلات کو hallucinate کر سکتا ہے | مخصوص دستاویزات کے حصوں کو حاصل کرتا ہے اور ان کا حوالہ دیتا ہے |
| مسابقتی انٹیلیجنس | تربیتی ڈیٹا تک محدود، اکثر فرسودہ | منسلک ذرائع سے موجودہ معلومات حاصل کرتا ہے |
| تعمیل کا سوال | عمومی ریگولیٹری علم سے جواب دیتا ہے | قابلِ اطلاق قوانین اور تنظیم مخصوص طریقہ کار حاصل کرتا ہے |
کاروبار RAG AI کو سب سے زیادہ مؤثر طریقے سے کہاں تعینات کر رہے ہیں
اندرونی علم کا انتظام
اندرونی علم کے انتظام کا استعمال کا معاملہ وہ ہے جہاں RAG AI اپنی سب سے واضح کاروباری قدر کا کچھ حصہ فراہم کرتا ہے۔ زیادہ تر تنظیموں کے پاس دستاویزات کے مخازن، wikis، ماضی کی پروجیکٹ فائلز، پالیسی دستاویزات، اور مواصلات میں تقسیم شدہ کافی ادارہ جاتی علم ہوتا ہے جس میں ملازمین دستی طور پر تلاش کرنے میں کافی وقت گزارتے ہیں۔ اس علم کے ڈیٹا بیس پر ایک RAG سسٹم اسے ایک گفتگو کی وسیلہ میں بدل دیتا ہے جس سے عملہ قدرتی زبان میں استفسار کر سکتا ہے اور درست، ماخذ شدہ جوابات حاصل کر سکتا ہے۔
یہاں مرکب قدر کافی ہے۔ تجربہ کار ملازمین جو اپنے ذہنوں میں تنظیمی علم رکھتے ہیں آخر کار چلے جاتے ہیں۔ دستاویزات جو موجود ہیں لیکن تلاش کرنا مشکل ہیں عملی طور پر تقریباً اتنی ہی ناقابلِ رسائی ہیں جتنی دستاویزات جو موجود نہیں ہیں۔ RAG سسٹمز تنظیمی علم کو تمام عملے کے لیے قابلِ رسائی بناتے ہیں چاہے ان کا مدت ملازمت کچھ بھی ہو، معلومات تلاش کرنے میں صرف کیا گیا وقت کم کرتے ہیں، اور متعلقہ علم کو اس سیاق و سباق میں سامنے لاتے ہیں جہاں اس کی ضرورت ہے بجائے اس کے کہ ملازمین کو معلوم ہو کہ کہاں دیکھنا ہے۔
یہ جائزہ لینا کہ enterprise RAG پلیٹ فارمز میں AI features حاصل کردہ مواد پر رسائی کنٹرول کو کیسے سنبھالتا ہے، اس استعمال کے معاملے کے لیے ضروری ہے کیونکہ تمام تنظیمی علم کو تمام ملازمین کے لیے یکساں طور پر قابلِ رسائی نہیں ہونا چاہیے۔ ایک اچھی طرح کنفیگر کیا گیا RAG سسٹم صرف وہ مواد حاصل کرتا ہے جس تک استفسار کرنے والے صارف کو رسائی کی اجازت ہے، علم کے ڈیٹا بیس میں موجود سب کچھ نہیں۔
کسٹمر کا سامنا کرنے والی سپورٹ اور سروس
RAG سے چلنے والی کسٹمر سروس ایپلی کیشنز اس ٹیکنالوجی کی سب سے زیادہ تجارتی طور پر اثر انگیز تعیناتیوں میں سے ایک کی نمائندگی کرتی ہیں۔ آپ کی پروڈکٹ دستاویزات، ٹربل شوٹنگ گائیڈز، آرڈر مینجمنٹ سسٹم، اور پالیسی ڈیٹا بیس پر ایک RAG pipeline کی پشت پناہی والی کسٹمر سروس AI کسٹمر کی اصل صورتحال کے بارے میں مخصوص، درست سوالات کا جواب دے سکتی ہے بجائے اس کے کہ عمومی جوابات پیدا کرے جو کسٹمرز کو اس مخصوص معلومات کے لیے انسانی ایجنٹس کے پاس بھیج دیتے ہیں جس کی انہیں ضرورت تھی۔
کاروباری معاملہ سیدھا ہے۔ درست پہلے رابطے کا حل سپورٹ کے اخراجات کو کم کرتا ہے، انسانی ایجنٹس کو escalations کو کم کرتا ہے، اور بہتر کسٹمر کے نتائج پیدا کرتا ہے۔ تکنیکی بنیاد جو AI سسٹمز کے لیے درست پہلے رابطے کے حل کو ممکن بناتی ہے تقریباً ہمیشہ RAG ہے۔ retrieval کے بغیر، ماڈل اس موجودہ، کسٹمر مخصوص معلومات تک رسائی حاصل نہیں کر سکتا جس کی درست سپورٹ جوابات کو ضرورت ہوتی ہے۔
تعمیل اور ریگولیٹری ایپلی کیشنز
مالیاتی خدمات، صحت کی دیکھ بھال، قانون، اور دیگر بھاری ریگولیٹڈ صنعتیں ریگولیٹری دستاویزات کے سیٹس پر RAG AI تعینات کر رہی ہیں تاکہ تعمیل کی ٹیموں کو پیچیدہ، اکثر اپڈیٹ ہونے والے قواعد کے سیٹس کو زیادہ مؤثر طریقے سے نیویگیٹ کرنے میں مدد ملے۔ ایک تعمیل افسر جو قابلِ اطلاق ریگولیشنز، رہنمائی کی دستاویزات، اور اندرونی پالیسی فریم ورک کے پورے متن پر ایک RAG سسٹم سے استفسار کر سکتا ہے اور مخصوص تعمیل سوالات کے درست، ماخذ شدہ جوابات حاصل کر سکتا ہے، حافظہ یا دستی دستاویز جائزے پر انحصار کرنے والے کے مقابلے میں زیادہ مؤثر طریقے سے اور زیادہ اعتماد کے ساتھ کام کرتا ہے۔
RAG سسٹمز کی حوالہ جات کی صلاحیت تعمیل کے سیاق و سباق میں خاص طور پر قیمتی ہے۔ ایک جواب جو اس مخصوص ریگولیٹری پیراگراف کا حوالہ دیتا ہے جس سے یہ اخذ کیا گیا ہے، قابلِ تصدیق اور قابلِ دفاع ہے اس طرح جیسے بغیر ماخذ کے AI سے پیدا کردہ جواب نہیں ہے۔ یہ فرق بہت زیادہ اہمیت رکھتا ہے جب جواب ریگولیٹری نتائج کے ساتھ ایک فیصلے کو مطلع کرتا ہے۔
یہ سمجھنا کہ AI security کی ضروریات حساس ریگولیٹری اور تعمیل کے ڈیٹا سے منسلک RAG سسٹمز پر کیسے لاگو ہوتی ہیں، تنظیموں کو ایسے retrieval pipelines بنانے میں مدد دیتا ہے جو ان دستاویزات میں مناسب رسائی کنٹرولز کو برقرار رکھیں جنہیں وہ انڈیکس کرتے ہیں۔

ایک RAG سسٹم بنانا جو واقعی کام کرتا ہے
ڈیٹا کوالٹی کا مسئلہ جسے زیادہ تر پروجیکٹس کم سمجھتے ہیں
RAG سسٹمز صرف اتنے اچھے ہیں جتنا کہ وہ مواد جس سے وہ حاصل کرتے ہیں۔ تنظیمیں جو AI انٹرفیس بنانے کے دلچسپ حصے تک پہنچنے کے لیے ڈیٹا کوالٹی کی تشخیص کو چھوڑ دیتی ہیں مسلسل دریافت کرتی ہیں کہ retrieval کا معیار جواب کے معیار کو لینگویج ماڈل کے انتخاب سے کہیں زیادہ متعین کرتا ہے۔ ناقص ذرائع کی دستاویزات، فرسودہ مواد، متضاد طور پر فارمیٹڈ معلومات، اور علم کے ڈیٹا بیسز جنہیں برقرار نہیں رکھا گیا، ایسے RAG سسٹمز پیدا کرتے ہیں جو غلط مواد حاصل کرتے ہیں اور ایسے جوابات پیدا کرتے ہیں جو معلومات نہ ہونے کی بجائے خراب معلومات پر مبنی ہوتے ہیں۔
عملی مضمر یہ ہے کہ علم کے ڈیٹا بیس کی تیاری حقیقی کام شروع ہونے سے پہلے جلدی سے مکمل ہونے والا ابتدائی قدم نہیں ہے۔ یہ پروجیکٹ کا ایک بنیادی حصہ ہے جو طے کرتا ہے کہ آیا تعینات کیا گیا سسٹم مفید ہے۔ دستاویز کی کوالٹی کا جائزہ، مواد کی موجودگی کی تشخیص، متضاد ورژنز کی deduplication، اور رسائی کنٹرول کی میپنگ سب کو انڈیکسنگ انفراسٹرکچر کی تعمیر سے پہلے ہونا چاہیے۔
Chunking کی حکمت عملی ہر چیز کو نیچے کی طرف متاثر کرتی ہے
انڈیکسنگ سے پہلے ذرائع کی دستاویزات کو حاصل کرنے کے قابل اکائیوں میں کیسے تقسیم کیا جاتا ہے، اس کا retrieval کے معیار پر زیادہ تر ٹیموں کے مقابلے میں زیادہ اثر ہوتا ہے جو RAG سسٹمز بنانا شروع کرتے وقت احساس کرتے ہیں۔ جو chunks بہت چھوٹے ہوتے ہیں وہ سیاق و سباق کی معلومات کھو دیتے ہیں جو ان کے مواد کو بامعنی بناتی ہیں۔ جو chunks بہت بڑے ہوتے ہیں وہ متعلقہ سے زیادہ حاصل کرتے ہیں اور اس سگنل کو پتلا کر دیتے ہیں جسے لینگویج ماڈل درست جوابات پیدا کرنے کے لیے استعمال کرتا ہے۔ بہترین chunking کی حکمت عملی علم کے ڈیٹا بیس میں دستاویز کی اقسام، عام کوئریز کی نوعیت، اور استعمال ہو رہے لینگویج ماڈل کے context window پر منحصر ہوتی ہے۔
صارفین کو تعینات کرنے سے پہلے نمائندہ کوئریز کے ساتھ retrieval کے معیار کی جانچ کرنا chunking کے مسائل کو اس وقت سامنے لاتا ہے جب وہ ابھی بھی حل کیے جا سکتے ہیں بجائے اس کے کہ صارفین نے متضاد جواب کے معیار کا تجربہ کیا ہو۔
RAG نفاذ کے طریقہ کار پر ایک جامع AI guide تنظیموں کو اپنے تعمیراتی عمل کو ان فیصلوں کے گرد ترتیب دینے میں مدد دیتی ہے جو ترقی کے دوران تکنیکی طور پر سب سے زیادہ دلچسپ ہونے کی بجائے پروڈکشن کے معیار کو سب سے زیادہ متاثر کرتے ہیں۔
جاننے کی چیزیں
RAG AI کے بارے میں کئی اہم حقائق جنہیں تنظیمیں عام طور پر اپنی پہلی تعیناتی کے دوران یا بعد میں دریافت کرتی ہیں:
Retrieval کا معیار اور پیداوار کا معیار الگ الگ مسائل ہیں جن کو الگ تشخیص کی ضرورت ہوتی ہے۔ ایک RAG سسٹم صحیح مواد حاصل کر سکتا ہے اور ایک ناقص ترکیب شدہ جواب پیدا کر سکتا ہے، یا غلط مواد حاصل کر سکتا ہے اور ایک روان جواب پیدا کر سکتا ہے جو درست لگتا ہے لیکن نہیں ہے۔ end-to-end سسٹم کی کارکردگی کی تشخیص سے پہلے دونوں اجزاء کو آزادانہ طور پر ٹیسٹ کرنا یہ شناخت کرتا ہے کہ مسائل واقعی کہاں رہتے ہیں۔
RAG hallucination کو ختم نہیں کرتا، اسے کم کرتا ہے۔ حاصل کردہ سیاق و سباق سے جواب پیدا کرنے والا ایک لینگویج ماڈل اب بھی حاصل کردہ مواد کی غلط تشریح کر کے، معلومات کو غلط طریقے سے جوڑ کر، یا حاصل کردہ سیاق و سباق میں موجود نہ ہونے والی تفصیلات پیدا کر کے غلط مواد پیدا کر سکتا ہے۔ اچھے retrieval کے ساتھ Hallucination کا خطرہ اس کے بغیر سے کافی کم ہے، لیکن انسانی جائزہ اعلی داؤ والی ایپلی کیشنز کے لیے اہم ہے۔
Embedding ماڈل کا انتخاب retrieval کے معیار کو نمایاں طور پر متاثر کرتا ہے۔ مختلف embedding ماڈلز مختلف قسم کے مواد پر بہتر کارکردگی دکھاتے ہیں۔ عمومی متن retrieval کے لیے بہتر ایک ماڈل تکنیکی دستاویزات، قانونی زبان، یا ڈومین مخصوص اصطلاحات پر ناقص کارکردگی دکھا سکتا ہے۔ embedding ماڈل کے لیے عہد کرنے سے پہلے اپنی اصل دستاویز کی اقسام اور کوئری کے نمونوں کے ساتھ retrieval کے معیار کی جانچ کرنا بعد میں مہنگی دوبارہ آرکیٹیکچرنگ کو روکتا ہے۔
علم کے ڈیٹا بیس کی دیکھ بھال ایک جاری آپریشنل فنکشن ہے، ایک بار سیٹ اپ کا کام نہیں۔ جیسے جیسے ذرائع کی دستاویزات اپڈیٹ ہوتی ہیں، نیا مواد شامل ہوتا ہے، اور فرسودہ مواد گمراہ کن ہو جاتا ہے، RAG علم کے ڈیٹا بیس کو اسی طرح اپڈیٹ کرنے کی ضرورت ہوتی ہے۔ تنظیمیں جو ابتدائی انڈیکسنگ کو علم کے ڈیٹا بیس کے کام کی تکمیل سمجھتی ہیں ان کے سسٹمز کے ساتھ ختم ہوتی ہیں جن کی درستگی کم ہوتی ہے جیسے جیسے انڈیکس شدہ مواد اور موجودہ حقیقت کے درمیان فرق وسیع ہوتا ہے۔
رسائی کنٹرولز کو retrieval کے وقت لاگو کرنے کی ضرورت ہے، صرف علم کے ڈیٹا بیس کے انڈیکسنگ پر نہیں۔ ایک صارف جسے کچھ مخصوص دستاویزات نہیں دیکھنی چاہئیں اسے ان دستاویزات پر مبنی جوابات نہیں ملنے چاہئیں چاہے دستاویزات سسٹم میں انڈیکس ہوں۔ Retrieval کے وقت اجازت کا نفاذ ایک سیکیورٹی کی ضرورت ہے، اختیاری اضافہ نہیں۔
30% کا اصول مفید طور پر RAG تعیناتی کی منصوبہ بندی پر لاگو ہوتا ہے۔ AI retrieval اور ترکیب کو تقریباً 30% علم کے کام، تلاش اور ترکیب کے جزو کو سنبھالنا چاہیے، جبکہ انسانی مہارت فیصلے، تشریح، اور نتیجہ خیز فیصلہ سازی کو سنبھالتی ہے جو باقی 70% پر مشتمل ہے۔ اس توازن کے گرد RAG تعیناتیوں کو ڈیزائن کرنا ایسے سسٹمز بناتا ہے جو انسانی علم کے کام کو حقیقی طور پر بڑھاتے ہیں بجائے اس فیصلے کو تبدیل کرنے کی کوشش کرنے کے جسے ابھی بھی لوگوں کے ساتھ رہنے کی ضرورت ہے۔
RAG AI کاروباری AI کے لیے معیاری آرکیٹیکچر کیوں بن رہا ہے
enterprise AI اپنانے کے وسیع تر سیاق و سباق میں RAG AI کیا ہے؟ یہ وہ آرکیٹیکچرل نمونہ ہے جو لینگویج ماڈلز کو ان مخصوص، موجودہ، تنظیمی علم کے کاموں کے لیے عملی طور پر مفید بناتا ہے جنہیں کاروباروں کو واقعی AI سے سنبھالنے کی ضرورت ہے۔ قدرتی زبان میں استدلال، ترکیب، اور بات چیت کرنے کی لینگویج ماڈل کی صلاحیت کا موجودہ، مخصوص، قابلِ تصدیق معلومات تک retrieval سسٹم کی رسائی کے ساتھ امتزاج کچھ ایسا پیدا کرتا ہے جو کوئی بھی جزو اکیلے فراہم نہیں کرتا۔
تنظیمیں جنہوں نے معیاری لینگویج ماڈلز تعینات کیے ہیں اور hallucinations، فرسودہ علم، اور کمپنی مخصوص سوالات کو سنبھالنے کی نااہلی سے مایوس ہیں، اکثر صحیح ٹیکنالوجی کو غلط آرکیٹیکچر میں تعینات کر رہی ہیں۔ وہی ماڈلز، اچھی طرح برقرار رکھے گئے علم کے ڈیٹا بیسز پر اچھی طرح بنائے گئے retrieval pipelines سے جڑے ہوئے، ڈرامائی طور پر مختلف اور ڈرامائی طور پر زیادہ مفید نتائج پیدا کرتے ہیں۔
RAG سسٹمز بنانے کی تکنیکی رکاوٹ پچھلے دو سالوں میں نمایاں طور پر کم ہو گئی ہے۔ frameworks، vector databases، اور ہوسٹ کیا گیا retrieval انفراسٹرکچر جو RAG کو عملی بناتا ہے، پختہ، اچھی طرح دستاویز شدہ، اور بغیر مخصوص AI ریسرچ پس منظر کے انجینئرنگ ٹیموں کے لیے قابلِ رسائی ہیں۔ جو چیز کامیاب RAG تعیناتیوں کو مایوس کن سے الگ کرتی ہے وہ تکنیکی پختگی کے بارے میں کم اور علم کے ڈیٹا بیسز کو صحیح طریقے سے تیار کرنے، retrieval کے معیار کا سختی سے جائزہ لینے، اور سسٹم کو ایک مکمل پروجیکٹ کی بجائے ایک زندہ آپریشنل اثاثہ کے طور پر برقرار رکھنے کے لیے تنظیمی ضبط کے بارے میں زیادہ ہے۔
اکثر پوچھے جانے والے سوالات
GPT اور RAG کے درمیان کیا فرق ہے؟
GPT ایک قسم کا large language model ہے جو تربیت کے دوران سیکھے گئے نمونوں کی بنیاد پر مکمل طور پر جوابات پیدا کرتا ہے، جبکہ RAG ایک آرکیٹیکچرل نقطہ نظر ہے جو کسی بھی لینگویج ماڈل، بشمول GPT، کو بیرونی علم کے ذرائع سے جوڑتا ہے جو حاصل کیے جاتے ہیں اور جواب کے وقت ماڈل کے سیاق و سباق میں شامل کیے جاتے ہیں۔ retrieval کے بغیر GPT صرف تربیتی ڈیٹا سے جواب دیتا ہے، جبکہ GPT پر مبنی RAG سسٹم اپنا جواب پیدا کرنے سے پہلے متعلقہ موجودہ معلومات حاصل کرتا ہے، ایسے جوابات پیدا کرتا ہے جو تربیتی ڈیٹا کی عمومیات کی بجائے مخصوص، قابلِ تصدیق ذرائع پر مبنی ہوتے ہیں۔
RAG اور generative AI کے درمیان کیا فرق ہے؟
Generative AI AI سسٹمز کی وسیع کیٹیگری ہے جو متن، تصاویر، اور آڈیو سمیت نیا مواد پیدا کرتی ہے، جبکہ RAG متن پیدا کرنے والی AI پر لاگو ہونے والی ایک مخصوص تکنیک ہے جو ماڈل کے اپنا جواب پیدا کرنے سے پہلے بیرونی ذرائع سے متعلقہ معلومات حاصل کرنے والے retrieval قدم کے ساتھ پیداوار کو بڑھاتی ہے۔ تمام RAG سسٹمز generative AI ہیں، لیکن زیادہ تر generative AI سسٹمز RAG سسٹمز نہیں ہیں۔ RAG ایک آرکیٹیکچرل اضافہ ہے جو generative AI کو علم سے بھرپور کاموں کے لیے زیادہ درست اور موجودہ بناتا ہے۔
RAG بمقابلہ LLM کیا ہے؟
LLM ایک لینگویج ماڈل ہے جو تربیتی ڈیٹا کی بنیاد پر متن پیدا کرتا ہے، جبکہ RAG ایک آرکیٹیکچر ہے جو LLM کو retrieval سسٹم کے ساتھ جوڑتا ہے تاکہ ماڈل صرف تربیتی ڈیٹا کی بجائے حاصل کردہ دستاویزات پر مبنی جوابات پیدا کرے۔ RAG سسٹم میں LLM زبان کی تفہیم اور پیداوار کو سنبھالتا ہے جبکہ retrieval کا جزو ہر کوئری کے لیے متعلقہ موجودہ، مخصوص معلومات تلاش کرنے کو سنبھالتا ہے۔ ایک ساتھ وہ ایسے آؤٹ پٹ پیدا کرتے ہیں جو کسی بھی جزو کے آزادانہ طور پر پیدا کرنے سے زیادہ درست، قابلِ تصدیق، اور تنظیمی طور پر متعلقہ ہوتے ہیں۔
RAG کن مسائل کو حل کرتا ہے؟
RAG بنیادی طور پر تین مسائل حل کرتا ہے: تربیتی کٹ آف کی حد جو معیاری LLMs کو حالیہ واقعات یا موجودہ معلومات کے بارے میں سوالات کا جواب دینے سے قاصر بناتی ہے، دائرہ کار کی حد جو ماڈلز کو ان کے اپنے تنظیمی علم کے بارے میں جاننے سے روکتی ہے جو کبھی عوامی تربیتی ڈیٹا میں نہیں تھا، اور hallucination کا مسئلہ جہاں ماڈلز قابلِ یقین لیکن غلط جوابات پیدا کرتے ہیں جب ان کے پاس وہ مخصوص علم نہیں ہوتا جس کی ایک سوال کو ضرورت ہوتی ہے۔ جوابات پیدا کرنے سے پہلے متعلقہ مواد حاصل کرنے سے، RAG شماریاتی نمونوں کی بجائے قابلِ تصدیق ذرائع میں AI آؤٹ پٹس کو زمین فراہم کرتا ہے، ایسے جوابات پیدا کرتا ہے جنہیں کاروباری اہم ایپلی کیشنز کے لیے چیک، حوالہ، اور بھروسہ کیا جا سکتا ہے۔
AI سے کون سے 3 ملازمتیں بچ جائیں گی؟
AI کی نقل مکانی کے لیے سب سے زیادہ لچکدار کام کی تین کیٹیگریز وہ کردار ہیں جنہیں غیر منظم ماحول میں جسمانی دنیا کے تعامل اور مہارت کی ضرورت ہوتی ہے، پیچیدہ انسانی فیصلے، اخلاقی استدلال، اور نتیجہ خیز فیصلوں کی جوابدہی پر مرکوز کردار، اور باہمی اعتماد، جذباتی ذہانت، اور تعلقات کے انتظام کے گرد بنائے گئے کردار۔ RAG AI اور اسی طرح کے سسٹمز علم کی retrieval اور ترکیب کو انتہائی خود کار بنا رہے ہیں، جو ان کرداروں کے انحصار کرنے والی واضح طور پر انسانی صلاحیتوں کی قدر کو تقویت دیتا ہے بجائے ان معلومات کی پروسیسنگ کے کاموں کے جنہیں AI اب زیادہ مؤثر طریقے سے سنبھالتا ہے۔