
Ano ang RAG AI? Ang Retrieval-Augmented Generation ay isang technique na ikinokonekta ang isang large language model sa isang external knowledge source sa sandaling mag-generate ito ng sagot, na nagpapahintulot sa model na kumuha ng current, specific, at verifiable na impormasyon imbes na umasa lamang sa kung ano ang natutunan nito noong training. Ang resulta ay isang AI system na sumasagot sa mga tanong gamit ang real data imbes na mga generalized na approximation.
Kung nagtanong na kayo sa isang standard AI assistant tungkol sa internal processes ng kumpanya niyo at nakatanggap ng sagot na mukhang makatuwiran pero gawa-gawa lang lahat, naranasan niyo na ang core limitation na sinubukang lutasin ng RAG. Ang language models ay sinasanay sa data hanggang sa isang fixed point in time. Wala silang alam tungkol sa proprietary documentation niyo, current inventory, latest policies, o anumang nangyari pagkatapos ng training cutoff nila. Binabago ng RAG ang fundamental limitation na iyon sa pamamagitan ng pagbibigay sa model ng mechanism para maghanap ng impormasyon bago sumagot, katulad ng isang well-prepared analyst na kumukunsulta sa source documents bago magbigay ng payo imbes na umasa lang sa memorya. Para sa mga businesses na nag-deploy ng AI sa mga contexts kung saan ang accuracy at specificity ay mahalaga, ang pag-intindi kung ano ang RAG AI at paano ito gumagana ay hindi lang isang technical detail. Ito ay ang pagkakaiba sa pagitan ng isang AI na talagang nakakatulong at isang nagpapaltik-paltik ng plausible na kalokohan nang may confidence.

Bakit may Fundamental Knowledge Problem ang Standard Language Models
Ang Training Cutoff Limitation
Bawat large language model na existing ngayon ay sinanay sa isang dataset na may defined end date. Lahat ng nangyari pagkatapos ng petsang iyon, bawat policy change, bawat product update, bawat regulatory development, bawat piece ng organizational knowledge na nilikha mula nang sanayin ang model, ay invisible sa kanya. Para sa general knowledge tasks, manageable ang limitation na ito dahil mabagal ang pagbabago ng foundational knowledge. Para sa business applications kung saan ang accuracy sa current, specific information ang buong punto, ito ay isang seryosong operational problem.
Ang pangalawang limitation ay scope. Kahit ang pinakamalaking language models na sinanay sa pinakamalawak na possible datasets ay walang knowledge tungkol sa impormasyong hindi naging bahagi ng kanilang training data. Ang internal knowledge base ng kumpanya niyo, ang inyong customer contracts, ang inyong technical documentation, ang inyong pricing structures, at ang inyong operational procedures ay halos siguradong hindi naging bahagi ng anumang public training dataset. Isang model na sumasagot ng mga tanong tungkol sa mga paksang ito ay hindi nagre-retrieve ng impormasyong alam niya. Nag-ge-generate siya ng text na mukhang sagot batay sa patterns sa kanyang training, isang proseso na nagdudulot ng fluent, confident responses na maaaring walang kaugnayan sa actual facts.
Ang phenomenon na ito ay may pangalan sa AI research: hallucination. Inilalarawan nito ang tendency ng language models na mag-generate ng factually incorrect na impormasyon na ipinapakita sa parehong confident tone tulad ng accurate na impormasyon. Para sa casual use cases, ang hallucination ay isang inconvenience. Para sa business applications sa legal, medical, financial, o operational contexts, ito ay isang liability.
Paano Sinasagot ng RAG ang Parehong Problema sa Iisang Pagkakataon
Ano ang specifically nilulutas ng RAG AI? Sinasagot nito ang parehong cutoff problem at scope problem sa pamamagitan ng iisang architectural addition. Imbes na hilingin sa model na sumagot mula sa training data lang, ang RAG systems ay nag-re-retrieve ng relevant documents o data mula sa external source sa query time at isinasama ang retrieved content na iyon sa context na ginagamit ng model para mag-generate ng sagot.
Hindi nag-gu-guess ang model kung ano ang sinasabi ng refund policy niyo. Nag-retrieve ito ng actual policy document bago tumugon. Hindi nito tinatantsa kung ano ang Q3 revenue figures niyo. Kinuha nito ang actual figures mula sa financial system niyo bago sumagot. Lumilipat ang role ng model mula sa pagiging sole knowledge source patungo sa pagiging intelligent synthesizer ng retrieved information, isang task na ginagawa ng language models nang extraordinarily well.
Ang architectural shift na ito ay may implikasyong lampas pa sa pag-aayos ng hallucinations. Ibig sabihin nito ay maaaring i-update ang AI systems sa pamamagitan ng pag-update ng kanilang knowledge sources imbes na i-retrain ang kanilang models. Ibig sabihin nito ay maaaring i-cite ng responses ang kanilang sources, na ginagawang straightforward ang verification. At ibig sabihin nito ay maaaring magtayo ang mga organisasyon ng AI systems na may access sa genuinely sensitive na internal knowledge nang hindi kailangang isama ang knowledge na iyon sa isang training dataset.
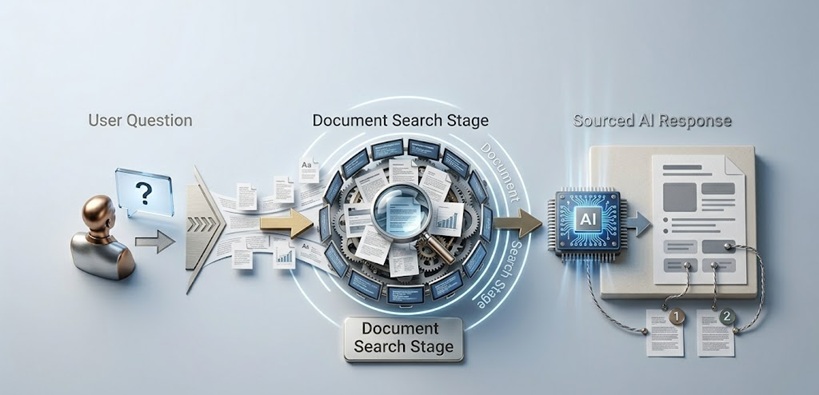
Paano Aktwal na Gumagana ang RAG AI
Ipinapaliwanag ang Retrieval Pipeline
Ang isang RAG system ay may dalawang major components na nagtatrabaho sequentially bago mag-generate ang language model ng kahit isang salita ng kanyang sagot.
Ang unang component ay ang knowledge base at ang indexing infrastructure nito. Ang mga documents, records, web pages, database entries, o anumang ibang impormasyon na dapat magamit ng AI ay pinoproseso at sino-store sa paraan na ginagawa silang searchable by meaning imbes na by keyword lang. Karaniwan itong involves ang pag-convert ng text sa mga numerical representations na tinatawag na embeddings, na kumukuha ng semantic meaning sa isang form na nagpapahintulot na mathematically similar content ay i-retrieve nang sabay-sabay. Isang tanong tungkol sa customer refund processes ay nag-re-retrieve ng content tungkol sa returns, exchanges, at satisfaction guarantees kahit hindi lumitaw ang exact words sa query.
Ang pangalawang component ay ang retrieval mechanism na nag-a-activate kapag nag-submit ang isang user ng query. Na-co-convert ang query sa parehong embedding format tulad ng stored documents, at na-i-identify ng system ang stored content na semantically most similar sa query. Ang retrieved content na iyon, ang passages, documents, o records na pinaka-relevant sa tanong na inihahain, ay tina-assemble at pinapasa sa language model kasama ang original query.
Ang language model pagkatapos ay nag-ge-generate ng sagot na nakabase sa retrieved context imbes na umasa sa training data nito para sa specific facts na kinakailangan. Ang training data ay mahalaga pa rin para sa language ability ng model, reasoning capacity nito, at general world knowledge nito. Pero ang specific factual content ng sagot ay galing sa retrieved material.
| RAG System Component | Ano ang Ginagawa Nito | Bakit ito Mahalaga |
|---|---|---|
| Document Ingestion | Pinoproseso at hinahati ang source documents para sa indexing | Tinutukoy kung anong knowledge ang ma-a-access ng system |
| Embedding Model | Kino-convert ang text sa semantic vector representations | Pinapagana ang meaning-based retrieval imbes na keyword matching |
| Vector Database | Iniimbak ang embeddings para sa mabilis na similarity search | Ginagawang mabilis ang retrieval para sa real-time use |
| Retrieval Mechanism | Inii-identify ang pinaka-relevant na content para sa bawat query | Tinutukoy ang accuracy ng retrieved context |
| Language Model | Nag-ge-generate ng sagot na nakabase sa retrieved content | Naglilikha ng coherent, synthesized na output mula sa retrieved facts |
| Source Attribution | Tina-track kung aling documents ang nag-inform sa bawat sagot | Pinapagana ang verification at nagtatatag ng user trust |
Ang pag-intindi kung paano ang AI architecture decisions sa RAG pipelines ay nakakaapekto sa parehong retrieval quality at response accuracy ay nakakatulong sa mga organisasyon na magtayo ng systems na reliable na gumagana imbes na maganda sa demonstrations at inconsistent sa production.
RAG vs Standard LLM: Saan Lumalabas ang Pagkakaiba sa Praktika
Ang distinction sa pagitan ng ano ang RAG AI at ano ang ginagawa ng standard LLM ay nagiging pinakamakikita sa mga specific scenarios kung saan nag-fa-fail ang standard models at nag-su-succeed ang RAG systems.
Isang standard LLM na tinanong tungkol sa current data retention policy ng organisasyon niyo ay nag-ge-generate ng sagot batay sa common data retention practices mula sa training data nito. Maaaring mukhang tama ito. Halos siguradong hindi nito inilalarawan ang actual policy niyo. Isang RAG system na tinanong ng parehong tanong ay nag-re-retrieve ng actual policy document niyo at nag-ge-generate ng sagot na nakabase sa kung ano ang sinasabi ng document na iyon. Magkapareho ang wika. Categorically different ang accuracy.
Isang standard LLM na tinanong tungkol sa customer complaint na isinumite kahapon ay walang ideya kung tungkol saan kayo nagsasalita. Ang complaint ay postdates ang training nito. Isang RAG system na konektado sa CRM niyo ay nag-re-retrieve ng complaint record at nag-ge-generate ng sagot na sumasalamin sa actual details ng specific situation ng customer na iyon.
Isang standard LLM na hinilingang i-summarize ang key findings mula sa isang research report na inu-upload niyo ay maaaring mag-produce ng plausible-sounding summary na nag-o-omit ng critical findings, nagmi-misrepresent ng conclusions, o nagco-combine ng details mula sa iba't ibang parts ng document nang hindi tumpak. Isang RAG system ay nag-re-retrieve ng specific sections na pinaka-relevant sa summary request at nag-ge-generate ng output na nakabase sa actual text.
| Scenario | Standard LLM Response | RAG AI Response |
|---|---|---|
| Tanong sa internal policy | Nag-ge-generate ng plausible generic answer na hindi specific sa policies niyo | Nire-retrieve ang actual policy document, sumasagot mula sa content nito |
| Tanong tungkol sa recent event | Sinasabi na walang information o nag-ge-generate ng outdated na sagot | Nire-retrieve ang current information mula sa connected knowledge base |
| Customer-specific inquiry | Hindi maa-access ang individual customer data | Nire-retrieve ang relevant customer records at tumutugon nang tumpak |
| Technical documentation query | Maaaring mag-hallucinate ng technical details | Nire-retrieve ang specific documentation sections at sinisipi ang mga ito |
| Competitive intelligence | Limited sa training data, kadalasan outdated | Nire-retrieve ang current information mula sa connected sources |
| Compliance question | Sumasagot mula sa general regulatory knowledge | Nire-retrieve ang applicable rules at organization-specific procedures |
Kung Saan Pinaka-effectively na Nag-de-deploy ng RAG AI ang mga Businesses
Internal Knowledge Management
Ang internal knowledge management use case ay kung saan naghahatid ang RAG AI ng ilan sa pinakamalinaw nitong business value. Karamihan sa mga organisasyon ay may substantial institutional knowledge na distributed sa documentation repositories, wikis, past project files, policy documents, at communications na ginugugol ng employees ng malaking oras sa manual searching. Isang RAG system sa knowledge base na iyon ay ginagawa itong isang conversational resource na maaaring i-query ng staff sa natural language at makatanggap ng tumpak, sourced na sagot mula rito.
Substantial ang compounding value dito. Ang experienced employees na may hawak ng organizational knowledge sa ulo nila ay eventually umaalis. Ang documentation na umiiral pero mahirap hanapin ay functionally halos kasing inaccessible ng documentation na hindi umiiral. Ginagawang accessible ng RAG systems ang organizational knowledge sa lahat ng staff anuman ang tenure, binabawasan ang oras na ginugugol sa paghahanap ng impormasyon, at ina-surface ang relevant knowledge sa context kung saan ito kailangan imbes na kailanganin ng employees na malaman kung saan tingnan.
Ang pagre-review kung paano hinahawakan ng AI features sa enterprise RAG platforms ang access control sa retrieved content ay essential para sa use case na ito dahil hindi lahat ng organizational knowledge ay dapat equally accessible sa lahat ng employees. Isang well-configured RAG system ay nire-retrieve lang ang content na authorized i-access ng querying user, hindi lahat ng nasa knowledge base.
Customer-Facing Support at Service
Ang RAG-powered customer service applications ay kumakatawan sa isa sa pinaka-commercially impactful na deployments ng technology na ito. Isang customer service AI na backed ng RAG pipeline sa product documentation niyo, troubleshooting guides, order management system, at policy database ay makakapag-sagot ng specific, accurate na tanong tungkol sa actual situation ng isang customer imbes na mag-generate ng generic responses na nagpapadala ng customers sa human agents para sa specific information na kailangan nila.
Straightforward ang business case. Ang tumpak na first-contact resolution ay binabawasan ang support costs, binabawasan ang escalations sa human agents, at nagdudulot ng mas magandang customer outcomes. Ang technical foundation na ginagawang posible ang accurate first-contact resolution para sa AI systems ay halos palaging RAG. Walang retrieval, hindi maa-access ng model ang current, customer-specific information na kinakailangan ng accurate support responses.
Compliance at Regulatory Applications
Ang financial services, healthcare, legal, at iba pang heavily regulated industries ay nag-de-deploy ng RAG AI sa regulatory document sets para tulungan ang compliance teams na mag-navigate sa complex, frequently updated rule sets nang mas efficiently. Isang compliance officer na maaaring mag-query sa isang RAG system sa full text ng applicable regulations, guidance documents, at internal policy frameworks at makatanggap ng tumpak, sourced na sagot sa specific compliance questions ay nagtatrabaho nang mas efficient at may mas malaking confidence kaysa sa isang umaasa sa memorya o manual document review.
Ang citation capability ng RAG systems ay particularly valuable sa compliance contexts. Isang sagot na sumisipi sa specific regulatory paragraph na pinagmumulan nito ay verifiable at defensible sa paraan na hindi kayang gawin ng isang AI-generated answer na walang sourcing. Ang pagkakaibang iyon ay enormously mahalaga kapag ang sagot ay nag-i-inform ng isang decision na may regulatory consequences.
Ang pag-intindi kung paano nag-a-apply ang AI security requirements sa RAG systems na konektado sa sensitive regulatory at compliance data ay nakakatulong sa mga organisasyon na magtayo ng retrieval pipelines na nag-mamaintain ng appropriate access controls sa mga documents na ina-index nila.

Pagtatayo ng RAG System na Aktwal na Gumagana
Ang Data Quality Problem na Karaniwang Minamaliit ng mga Projects
Ang RAG systems ay kasing-ganda lang ng content na nire-retrieve nila mula rito. Ang mga organisasyon na nagmamadali na lumampas sa data quality assessment para makarating sa exciting part ng pagtatayo ng AI interface ay consistently natutuklasan na tinutukoy ng retrieval quality ang response quality nang higit kaysa sa choice ng language model. Mahihinang source documents, outdated content, inconsistently formatted information, at knowledge bases na hindi nai-maintain ay nagdudulot ng RAG systems na nire-retrieve ang maling content at nag-ge-generate ng responses na nakabase sa masamang impormasyon imbes na walang impormasyon.
Ang practical implication ay ang knowledge base preparation ay hindi isang preliminary step na dapat tapusin agad bago magsimula ang totoong trabaho. Ito ay isang core part ng project na tumutukoy kung useful ang deployed system. Ang document quality review, content currency assessment, deduplication ng conflicting versions, at access control mapping ay lahat kailangang mangyari bago itayo ang indexing infrastructure.
Ang Chunking Strategy ay Nakakaapekto sa Lahat ng Downstream
Kung paano hinahati ang source documents sa retrievable units bago ang indexing ay may mas malaking epekto sa retrieval quality kaysa sa nare-realize ng karamihan sa teams kapag sinimulan nilang itayo ang RAG systems. Ang chunks na masyadong maliit ay nawawalan ng contextual information na nagbibigay-kahulugan sa kanilang content. Ang chunks na masyadong malaki ay nire-retrieve ng higit pa sa relevant at dini-dilute ang signal na ginagamit ng language model para mag-generate ng accurate responses. Ang optimal chunking strategy ay nakasalalay sa document types sa knowledge base, sa nature ng typical queries, at sa context window ng language model na ginagamit.
Ang pag-test ng retrieval quality sa representative queries bago mag-deploy sa users ay naglalabas ng chunking problems habang maaari pa silang matugunan imbes na pagkatapos maranasan ng users ang inconsistent response quality.
Isang comprehensive AI guide sa RAG implementation methodology ay tumutulong sa mga organisasyon na i-structure ang kanilang build process sa mga decisions na pinaka-nakakaapekto sa production quality imbes na sa mga technically pinaka-interesting habang development.
Mga Bagay na Dapat Malaman
Ilang mahalagang realities tungkol sa RAG AI na karaniwang nadi-discover ng mga organisasyon habang o pagkatapos ng kanilang first deployment:
Ang retrieval quality at generation quality ay magkahiwalay na problems na nangangailangan ng magkahiwalay na evaluation. Maaaring mag-retrieve ang RAG system ng tamang content at mag-generate ng poorly synthesized response, o mag-retrieve ng maling content at mag-generate ng fluent response na mukhang tumpak pero hindi. Ang pag-test ng parehong components independently bago i-evaluate ang end-to-end system performance ay nag-i-identify kung saan aktwal na nakatira ang problems.
Hindi inaalis ng RAG ang hallucination, binabawasan lang ito. Isang language model na nag-ge-generate ng response mula sa retrieved context ay maaari pa ring mag-produce ng inaccurate content sa pamamagitan ng misinterpreting ng retrieved material, ng pag-combine ng information nang mali, o ng pag-generate ng details na hindi present sa retrieved context. Substantially mas mababa ang hallucination risk sa magandang retrieval kaysa wala nito, pero ang human review ay nananatiling mahalaga para sa high-stakes applications.
Significantly nakakaapekto sa retrieval quality ang choice ng embedding model. Iba-ibang embedding models ay mas mahusay na nag-pe-perform sa iba't ibang types ng content. Isang model na optimized para sa general text retrieval ay maaaring mag-perform nang masama sa technical documentation, legal language, o domain-specific terminology. Ang pag-test ng retrieval quality sa actual document types at query patterns niyo bago mag-commit sa isang embedding model ay nag-prevent ng expensive rearchitecting sa kalaunan.
Ang knowledge base maintenance ay isang ongoing operational function, hindi isang one-time setup task. Habang ina-update ang source documents, idinadagdag ang new content, at nagiging misleading ang outdated content, kailangang i-update nang naaayon ang RAG knowledge base. Ang mga organisasyon na nag-tre-treat sa initial indexing bilang completion ng knowledge base work ay nagwawakas sa systems na ang accuracy ay nag-de-degrade habang lumalawak ang gap sa pagitan ng indexed content at current reality.
Kailangang i-enforce ang access controls sa retrieval time, hindi lang sa knowledge base ingestion. Isang user na hindi dapat makakita ng certain documents ay hindi dapat makatanggap ng responses na nakabase sa mga documents na iyon kahit na ang documents ay indexed sa system. Ang retrieval-time permission enforcement ay isang security requirement, hindi isang optional enhancement.
Ang 30% rule ay nag-a-apply nang usefully sa RAG deployment planning. Ang AI retrieval at synthesis ay dapat humawak ng roughly 30% ng knowledge work, ang lookup at synthesis component, habang ang human expertise ay humahawak ng judgment, interpretation, at consequential decision-making na bumubuo sa remaining 70%. Ang pag-design ng RAG deployments sa paligid ng balance na ito ay naglilikha ng systems na genuinely nag-a-augment ng human knowledge work imbes na subukan i-replace ang judgment na kailangang manatili sa mga tao.
Bakit Nagiging Standard Architecture ang RAG AI para sa Business AI
Ano ang RAG AI sa broader context ng enterprise AI adoption? Ito ang architectural pattern na ginagawang practically useful ang language models para sa specific, current, organizational knowledge tasks na aktwal na kailangan ng businesses para hawakan ng AI. Ang kombinasyon ng kakayahan ng language model na mag-reason, mag-synthesize, at mag-communicate sa natural language sa access ng isang retrieval system sa current, specific, verifiable information ay naglilikha ng isang bagay na hindi naihahatid ng kahit alin sa mga components nang mag-isa.
Ang mga organisasyon na nag-deploy ng standard language models at na-disappoint sa hallucinations, outdated knowledge, at inability na hawakan ang company-specific questions ay madalas nag-de-deploy ng tamang technology sa maling architecture. Ang parehong models, na konektado sa well-built retrieval pipelines sa well-maintained knowledge bases, ay nag-ge-generate ng dramatically different at dramatically more useful results.
Ang technical barrier sa pagtatayo ng RAG systems ay significantly bumaba sa nakalipas na dalawang taon. Ang frameworks, vector databases, at hosted retrieval infrastructure na ginagawang practical ang RAG ay mature, well-documented, at accessible sa engineering teams na walang specialized AI research backgrounds. Ang naghihiwalay sa successful RAG deployments mula sa disappointing ones ay mas hindi tungkol sa technical sophistication at mas tungkol sa organizational discipline para mag-prepare ng knowledge bases nang maayos, mag-evaluate ng retrieval quality nang rigorously, at mag-maintain ng system bilang isang living operational asset imbes na isang completed project.
Madalas Itanong
Ano ang pagkakaiba sa pagitan ng GPT at RAG?
Ang GPT ay isang type ng large language model na nag-ge-generate ng responses based entirely sa patterns na natutunan habang training, habang ang RAG ay isang architectural approach na nag-ko-connect ng kahit anong language model, kasama ang GPT, sa external knowledge sources na nire-retrieve at isinasama sa context ng model sa response time. Ang GPT na walang retrieval ay sumasagot mula sa training data lang, habang ang isang GPT-based RAG system ay nire-retrieve ang relevant current information bago mag-generate ng response nito, na nag-pro-produce ng mga sagot na nakabase sa specific, verifiable sources imbes na sa training data generalizations.
Ano ang pagkakaiba ng RAG at generative AI?
Ang generative AI ay ang broad category ng AI systems na nag-pro-produce ng bagong content kasama ang text, images, at audio, habang ang RAG ay isang specific technique na inilalapat sa text-generating AI na nag-a-augment ng generation gamit ang retrieval step na nag-pu-pull ng relevant information mula sa external sources bago mag-generate ng response ang model. Lahat ng RAG systems ay generative AI, pero karamihan sa generative AI systems ay hindi RAG systems. Ang RAG ay isang architectural enhancement na ginagawang mas tumpak at napapanahon ang generative AI para sa knowledge-intensive tasks.
Ano ang RAG vs LLM?
Ang LLM ay isang language model na nag-ge-generate ng text based sa training data, habang ang RAG ay isang architecture na nag-pa-pair ng LLM sa retrieval system para mag-generate ng responses na nakabase sa retrieved documents imbes na sa training data lang. Ang LLM sa isang RAG system ay humahawak ng language understanding at generation habang ang retrieval component ay humahawak ng paghahanap ng current, specific information na relevant sa bawat query. Sabay-sabay, naglilikha sila ng outputs na mas tumpak, verifiable, at organizationally relevant kaysa sa nilikha ng kahit alin sa mga components nang independently.
Anong problems ang nilulutas ng RAG?
Pangunahing nilulutas ng RAG ang tatlong problems: ang training cutoff limitation na ginagawang hindi kayang sagutin ng standard LLMs ang mga tanong tungkol sa recent events o current information, ang scope limitation na nagpi-prevent sa models na malaman ang proprietary organizational knowledge na hindi naging bahagi ng public training data, at ang hallucination problem kung saan nag-ge-generate ang models ng plausible pero inaccurate na responses kapag wala sila ng specific knowledge na kailangan ng isang tanong. Sa pamamagitan ng pag-retrieve ng relevant content bago mag-generate ng responses, ginagawa ng RAG na nakabase ang AI outputs sa verifiable sources imbes na sa statistical patterns, na nag-pro-produce ng mga sagot na maaaring i-check, i-cite, at pagkatiwalaan para sa business-critical applications.
Aling 3 trabaho ang makakaligtas sa AI?
Ang tatlong kategorya ng trabaho na pinaka-resilient sa AI displacement ay ang mga roles na nangangailangan ng physical world interaction at dexterity sa unstructured environments, ang mga roles na nakatuon sa complex human judgment, ethical reasoning, at accountability para sa consequential decisions, at ang mga roles na binuo sa paligid ng interpersonal trust, emotional intelligence, at relationship management. Ang RAG AI at mga katulad na systems ay ginagawang highly automatable ang knowledge retrieval at synthesis, na nagpapalakas sa value ng distinctly human capabilities na inaasahan ng mga roles na ito imbes na sa information processing tasks na hinahawakan na ng AI nang mas efficiently.