
RAG AI क्या है? रिट्रीवल-ऑगमेंटेड जनरेशन एक ऐसी तकनीक है जो उस क्षण में एक बड़े भाषा मॉडल को एक बाहरी ज्ञान स्रोत से जोड़ती है जब वह प्रतिक्रिया उत्पन्न करता है, जिससे मॉडल को प्रशिक्षण के दौरान जो कुछ भी सीखा है उस पर पूरी तरह से निर्भर रहने के बजाय वर्तमान, विशिष्ट और सत्यापन योग्य जानकारी प्राप्त करने की अनुमति मिलती है। परिणाम एक AI प्रणाली है जो सामान्यीकृत अनुमानों के बजाय वास्तविक डेटा के साथ प्रश्नों का उत्तर देती है।
यदि आपने कभी एक मानक AI सहायक से अपनी कंपनी की आंतरिक प्रक्रियाओं के बारे में एक प्रश्न पूछा है और एक ऐसा उत्तर प्राप्त किया है जो उचित लगता था लेकिन पूरी तरह से मनगढ़ंत था, तो आपने उस मूल सीमा का अनुभव किया है जिसे RAG ने हल करने के लिए डिज़ाइन किया गया था। भाषा मॉडल को समय में एक निश्चित बिंदु तक के डेटा पर प्रशिक्षित किया जाता है। वे आपके स्वामित्व वाले प्रलेखन, आपकी वर्तमान सूची, आपकी नवीनतम नीतियों, या उनके प्रशिक्षण कटऑफ के बाद हुई किसी भी चीज़ के बारे में कुछ भी नहीं जानते हैं। RAG उस मूलभूत सीमा को बदलता है, मॉडल को उत्तर देने से पहले चीजों को देखने का एक तंत्र देकर, उसी तरह जैसे एक अच्छी तरह से तैयार विश्लेषक सलाह देने से पहले स्रोत दस्तावेजों से परामर्श करता है, न कि पूरी तरह से स्मृति से काम करता है। उन व्यवसायों के लिए जो ऐसे संदर्भों में AI तैनात कर रहे हैं जहाँ सटीकता और विशिष्टता महत्वपूर्ण हैं, यह समझना कि RAG AI क्या है और यह कैसे काम करता है, कोई तकनीकी बारीकी नहीं है। यह एक ऐसी AI के बीच का अंतर है जो वास्तव में मदद करती है और एक ऐसी जो आत्मविश्वास से प्रशंसनीय बकवास उत्पन्न करती है।

मानक भाषा मॉडलों में एक मौलिक ज्ञान समस्या क्यों है
प्रशिक्षण कटऑफ सीमा
आज मौजूद हर बड़े भाषा मॉडल को एक परिभाषित समाप्ति तिथि वाले डेटासेट पर प्रशिक्षित किया गया था। उस तिथि के बाद हुई हर चीज़, हर नीति परिवर्तन, हर उत्पाद अद्यतन, हर नियामक विकास, मॉडल के प्रशिक्षण के बाद से बनाए गए संगठनात्मक ज्ञान का हर टुकड़ा, उसके लिए अदृश्य है। सामान्य ज्ञान कार्यों के लिए यह सीमा प्रबंधनीय है क्योंकि मूलभूत ज्ञान धीरे-धीरे बदलता है। व्यावसायिक अनुप्रयोगों के लिए जहाँ वर्तमान, विशिष्ट जानकारी पर सटीकता पूरा बिंदु है, यह एक गंभीर परिचालन समस्या है।
दूसरी सीमा दायरा है। यहाँ तक कि सबसे व्यापक संभव डेटासेट पर प्रशिक्षित सबसे बड़े भाषा मॉडलों को भी ऐसी जानकारी का कोई ज्ञान नहीं है जो कभी उनके प्रशिक्षण डेटा में नहीं थी। आपकी कंपनी का आंतरिक ज्ञान आधार, आपके ग्राहक अनुबंध, आपका तकनीकी प्रलेखन, आपकी मूल्य निर्धारण संरचनाएँ, और आपकी परिचालन प्रक्रियाएँ लगभग निश्चित रूप से कभी किसी सार्वजनिक प्रशिक्षण डेटासेट में नहीं थीं। इन विषयों के बारे में प्रश्नों का उत्तर देने वाला एक मॉडल वह जानकारी पुनः प्राप्त नहीं कर रहा है जिसे वह जानता है। यह अपने प्रशिक्षण में पैटर्न के आधार पर एक उत्तर की तरह दिखने वाला पाठ उत्पन्न कर रहा है, एक ऐसी प्रक्रिया जो धाराप्रवाह, आत्मविश्वासी प्रतिक्रियाएँ उत्पन्न करती है जिनका वास्तविक तथ्यों से कोई संबंध नहीं हो सकता है।
इस घटना का AI अनुसंधान में एक नाम है: मतिभ्रम। यह भाषा मॉडलों की तथ्यात्मक रूप से गलत जानकारी को उसी आत्मविश्वासी स्वर में प्रस्तुत करने की प्रवृत्ति का वर्णन करता है जैसे सटीक जानकारी। आकस्मिक उपयोग के मामलों के लिए, मतिभ्रम एक असुविधा है। कानूनी, चिकित्सा, वित्तीय या परिचालन संदर्भों में व्यावसायिक अनुप्रयोगों के लिए, यह एक देयता है।
RAG दोनों समस्याओं को एक साथ कैसे संबोधित करता है
RAG AI विशेष रूप से क्या हल कर रहा है? यह एकल वास्तुकला जोड़ के साथ कटऑफ समस्या और दायरे की समस्या दोनों को संबोधित करता है। मॉडल को केवल प्रशिक्षण डेटा से उत्तर देने के लिए कहने के बजाय, RAG सिस्टम क्वेरी समय पर एक बाहरी स्रोत से प्रासंगिक दस्तावेज़ या डेटा पुनः प्राप्त करते हैं और उस पुनः प्राप्त सामग्री को उस संदर्भ में शामिल करते हैं जिसका उपयोग मॉडल अपनी प्रतिक्रिया उत्पन्न करने के लिए करता है।
मॉडल अनुमान नहीं लगा रहा है कि आपकी रिफंड नीति क्या कहती है। उसने जवाब देने से पहले वास्तविक नीति दस्तावेज़ को पुनः प्राप्त किया। यह अनुमान नहीं लगा रहा है कि आपके Q3 राजस्व आंकड़े क्या थे। उसने उत्तर देने से पहले आपकी वित्तीय प्रणाली से वास्तविक आंकड़े निकाले। मॉडल की भूमिका एकमात्र ज्ञान स्रोत से पुनः प्राप्त जानकारी के बुद्धिमान संश्लेषक में बदल जाती है, जो एक ऐसा कार्य है जो भाषा मॉडल असाधारण रूप से अच्छी तरह से करते हैं।
इस वास्तुशिल्प बदलाव का प्रभाव मतिभ्रम को ठीक करने से कहीं अधिक है। इसका मतलब है कि AI सिस्टम को उनके मॉडलों को फिर से प्रशिक्षित करने के बजाय उनके ज्ञान स्रोतों को अद्यतन करके अद्यतन किया जा सकता है। इसका मतलब है कि प्रतिक्रियाएँ अपने स्रोतों का हवाला दे सकती हैं, जिससे सत्यापन सीधा हो जाता है। और इसका मतलब है कि संगठन ऐसे AI सिस्टम का निर्माण कर सकते हैं जिन्हें वास्तविक रूप से संवेदनशील आंतरिक ज्ञान तक पहुँच हो, बिना उस ज्ञान को कभी प्रशिक्षण डेटासेट में शामिल करने की आवश्यकता हो।
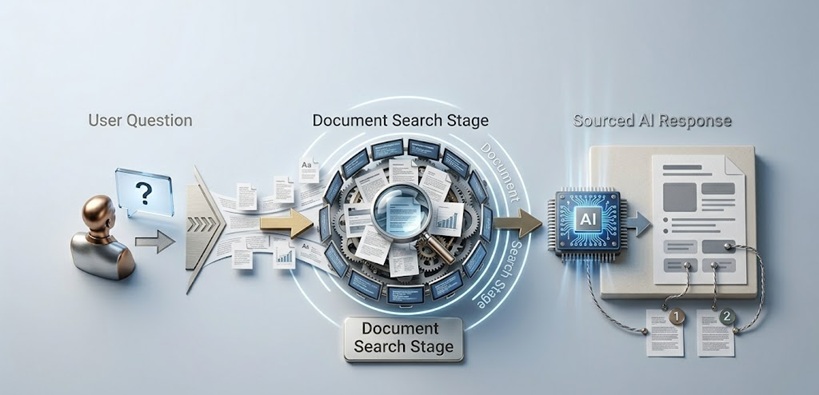
RAG AI वास्तव में कैसे काम करता है
पुनर्प्राप्ति पाइपलाइन की व्याख्या
एक RAG सिस्टम में दो प्रमुख घटक होते हैं जो भाषा मॉडल द्वारा अपनी प्रतिक्रिया का एक शब्द उत्पन्न करने से पहले अनुक्रम में काम करते हैं।
पहला घटक ज्ञान आधार और इसकी अनुक्रमण अवसंरचना है। दस्तावेज़, रिकॉर्ड, वेब पेज, डेटाबेस प्रविष्टियाँ, या कोई भी अन्य जानकारी जिसका AI को उपयोग करने में सक्षम होना चाहिए, ऐसे तरीके से संसाधित और संग्रहीत की जाती है जो उन्हें केवल कीवर्ड के बजाय अर्थ से खोजने योग्य बनाता है। इसमें आम तौर पर पाठ को एम्बेडिंग नामक संख्यात्मक प्रतिनिधित्व में परिवर्तित करना शामिल है, जो शब्दार्थ अर्थ को एक ऐसे रूप में पकड़ता है जो गणितीय रूप से समान सामग्री को एक साथ पुनः प्राप्त करने की अनुमति देता है। ग्राहक रिफंड प्रक्रियाओं के बारे में एक प्रश्न रिटर्न, एक्सचेंज और संतुष्टि गारंटी के बारे में सामग्री प्राप्त करता है, भले ही वे सटीक शब्द क्वेरी में दिखाई न दें।
दूसरा घटक पुनर्प्राप्ति तंत्र है जो तब सक्रिय होता है जब कोई उपयोगकर्ता एक क्वेरी सबमिट करता है। क्वेरी को संग्रहीत दस्तावेज़ों के समान एम्बेडिंग प्रारूप में परिवर्तित किया जाता है, और सिस्टम क्वेरी के सबसे शब्दार्थ रूप से समान संग्रहीत सामग्री की पहचान करता है। वह पुनः प्राप्त सामग्री, पूछे जा रहे प्रश्न के लिए सबसे प्रासंगिक मार्ग, दस्तावेज़ या रिकॉर्ड, मूल क्वेरी के साथ इकट्ठा किया जाता है और भाषा मॉडल को पास किया जाता है।
फिर भाषा मॉडल आवश्यक विशिष्ट तथ्यों के लिए अपने प्रशिक्षण डेटा पर निर्भर रहने के बजाय उस पुनः प्राप्त संदर्भ में आधारित एक प्रतिक्रिया उत्पन्न करता है। प्रशिक्षण डेटा अभी भी मॉडल की भाषा क्षमता, उसकी तर्क क्षमता और उसके सामान्य विश्व ज्ञान के लिए मायने रखता है। लेकिन प्रतिक्रिया की विशिष्ट तथ्यात्मक सामग्री पुनः प्राप्त सामग्री से आती है।
| RAG सिस्टम घटक | यह क्या करता है | यह क्यों मायने रखता है |
|---|---|---|
| दस्तावेज़ इनजेशन | अनुक्रमण के लिए स्रोत दस्तावेज़ों को संसाधित और खंडित करता है | निर्धारित करता है कि सिस्टम किस ज्ञान तक पहुँच सकता है |
| एम्बेडिंग मॉडल | पाठ को शब्दार्थ वेक्टर प्रतिनिधित्व में परिवर्तित करता है | कीवर्ड मिलान के बजाय अर्थ-आधारित पुनर्प्राप्ति को सक्षम करता है |
| वेक्टर डेटाबेस | त्वरित समानता खोज के लिए एम्बेडिंग संग्रहीत करता है | वास्तविक समय के उपयोग के लिए पुनर्प्राप्ति को तेज़ बनाता है |
| पुनर्प्राप्ति तंत्र | प्रत्येक क्वेरी के लिए सबसे प्रासंगिक सामग्री की पहचान करता है | पुनः प्राप्त संदर्भ की सटीकता निर्धारित करता है |
| भाषा मॉडल | पुनः प्राप्त सामग्री में आधारित प्रतिक्रिया उत्पन्न करता है | पुनः प्राप्त तथ्यों से सुसंगत, संश्लेषित आउटपुट का उत्पादन करता है |
| स्रोत श्रेय | ट्रैक करता है कि किन दस्तावेज़ों ने प्रत्येक प्रतिक्रिया को सूचित किया | सत्यापन सक्षम करता है और उपयोगकर्ता का विश्वास बनाता है |
यह समझना कि RAG पाइपलाइनों में AI आर्किटेक्चर निर्णय पुनर्प्राप्ति गुणवत्ता और प्रतिक्रिया सटीकता दोनों को कैसे प्रभावित करते हैं, संगठनों को ऐसे सिस्टम बनाने में मदद करता है जो प्रदर्शनों में अच्छा प्रदर्शन करने और उत्पादन में असंगत होने के बजाय विश्वसनीय रूप से प्रदर्शन करते हैं।
RAG बनाम मानक LLM: व्यवहार में अंतर कहाँ दिखाई देता है
RAG AI क्या है और एक मानक LLM क्या करता है, इसके बीच का अंतर उन विशिष्ट परिदृश्यों में सबसे अधिक दिखाई देता है जहाँ मानक मॉडल विफल होते हैं और RAG सिस्टम सफल होते हैं।
आपके संगठन की वर्तमान डेटा अवधारण नीति के बारे में पूछा गया एक मानक LLM अपने प्रशिक्षण डेटा से सामान्य डेटा अवधारण प्रथाओं के आधार पर एक प्रतिक्रिया उत्पन्न करता है। यह बिल्कुल सही लग सकता है। यह लगभग निश्चित रूप से आपकी वास्तविक नीति का वर्णन नहीं कर रहा है। उसी प्रश्न से पूछा गया एक RAG सिस्टम आपके वास्तविक नीति दस्तावेज़ को पुनः प्राप्त करता है और उस दस्तावेज़ के कथन में आधारित एक प्रतिक्रिया उत्पन्न करता है। भाषा समान है। सटीकता श्रेणीगत रूप से भिन्न है।
कल प्रस्तुत एक ग्राहक शिकायत के बारे में पूछा गया एक मानक LLM को पता नहीं है कि आप किस बारे में बात कर रहे हैं। शिकायत उसके प्रशिक्षण के बाद की है। आपके CRM से जुड़ा एक RAG सिस्टम शिकायत रिकॉर्ड पुनः प्राप्त करता है और एक प्रतिक्रिया उत्पन्न करता है जो उस विशिष्ट ग्राहक की स्थिति के वास्तविक विवरण को दर्शाती है।
आपके द्वारा अपलोड की गई शोध रिपोर्ट से प्रमुख निष्कर्षों को सारांशित करने के लिए कहा गया एक मानक LLM एक प्रशंसनीय-ध्वनि वाला सारांश उत्पन्न कर सकता है जो महत्वपूर्ण निष्कर्षों को छोड़ देता है, निष्कर्षों को गलत प्रस्तुत करता है, या दस्तावेज़ के विभिन्न हिस्सों से विवरण को गलत तरीके से जोड़ता है। एक RAG सिस्टम सारांश अनुरोध के लिए सबसे प्रासंगिक विशिष्ट अनुभागों को पुनः प्राप्त करता है और वास्तविक पाठ में आधारित आउटपुट उत्पन्न करता है।
| परिदृश्य | मानक LLM प्रतिक्रिया | RAG AI प्रतिक्रिया |
|---|---|---|
| आंतरिक नीति प्रश्न | आपकी नीतियों के लिए विशिष्ट नहीं एक प्रशंसनीय सामान्य उत्तर उत्पन्न करता है | वास्तविक नीति दस्तावेज़ पुनः प्राप्त करता है, इसकी सामग्री से उत्तर देता है |
| हाल की घटना के बारे में प्रश्न | बताता है कि उसके पास कोई जानकारी नहीं है या पुराना उत्तर उत्पन्न करता है | जुड़े ज्ञान आधार से वर्तमान जानकारी पुनः प्राप्त करता है |
| ग्राहक-विशिष्ट पूछताछ | व्यक्तिगत ग्राहक डेटा तक नहीं पहुँच सकता | प्रासंगिक ग्राहक रिकॉर्ड पुनः प्राप्त करता है और सटीक रूप से प्रतिक्रिया देता है |
| तकनीकी दस्तावेज़ क्वेरी | तकनीकी विवरणों का मतिभ्रम कर सकता है | विशिष्ट प्रलेखन अनुभाग पुनः प्राप्त करता है और उनका हवाला देता है |
| प्रतिस्पर्धी खुफिया | प्रशिक्षण डेटा तक सीमित, अक्सर पुराना | जुड़े स्रोतों से वर्तमान जानकारी पुनः प्राप्त करता है |
| अनुपालन प्रश्न | सामान्य नियामक ज्ञान से उत्तर देता है | लागू नियम और संगठन-विशिष्ट प्रक्रियाएँ पुनः प्राप्त करता है |
जहाँ व्यवसाय सबसे प्रभावी ढंग से RAG AI को तैनात कर रहे हैं
आंतरिक ज्ञान प्रबंधन
आंतरिक ज्ञान प्रबंधन उपयोग का मामला वह स्थान है जहाँ RAG AI अपने कुछ सबसे स्पष्ट व्यावसायिक मूल्य प्रदान करता है। अधिकांश संगठनों के पास प्रलेखन रिपॉजिटरी, विकी, पिछले प्रोजेक्ट फ़ाइलों, नीति दस्तावेज़ों और संचारों में वितरित पर्याप्त संस्थागत ज्ञान है, जिसके माध्यम से कर्मचारी मैन्युअल रूप से खोज करने में महत्वपूर्ण समय व्यतीत करते हैं। उस ज्ञान आधार पर एक RAG सिस्टम इसे एक संवादात्मक संसाधन में बदल देता है जिससे कर्मचारी प्राकृतिक भाषा में क्वेरी कर सकते हैं और सटीक, स्रोतित उत्तर प्राप्त कर सकते हैं।
यहाँ का संयोजित मूल्य पर्याप्त है। अनुभवी कर्मचारी जो अपने सिर में संगठनात्मक ज्ञान रखते हैं, अंततः चले जाते हैं। ऐसा प्रलेखन जो मौजूद है लेकिन खोजना कठिन है, कार्यात्मक रूप से लगभग उतना ही दुर्गम है जितना कि ऐसा प्रलेखन जो मौजूद नहीं है। RAG सिस्टम संगठनात्मक ज्ञान को कार्यकाल की परवाह किए बिना सभी कर्मचारियों के लिए सुलभ बनाते हैं, जानकारी खोजने में बिताए गए समय को कम करते हैं, और कर्मचारियों को यह जानने की आवश्यकता के बजाय कि कहाँ देखना है, प्रासंगिक ज्ञान को उस संदर्भ में सामने लाते हैं जहाँ इसकी आवश्यकता है।
एंटरप्राइज़ RAG प्लेटफ़ॉर्म में AI विशेषताएँ पुनः प्राप्त सामग्री पर एक्सेस नियंत्रण को कैसे संभालती हैं, इसकी समीक्षा करना इस उपयोग के मामले के लिए आवश्यक है क्योंकि सभी संगठनात्मक ज्ञान सभी कर्मचारियों के लिए समान रूप से सुलभ नहीं होना चाहिए। एक अच्छी तरह से कॉन्फ़िगर किया गया RAG सिस्टम केवल वह सामग्री पुनः प्राप्त करता है जिसे क्वेरी करने वाला उपयोगकर्ता एक्सेस करने के लिए अधिकृत है, ज्ञान आधार में सब कुछ नहीं।
ग्राहक-सामना समर्थन और सेवा
RAG-संचालित ग्राहक सेवा अनुप्रयोग इस तकनीक की सबसे व्यावसायिक रूप से प्रभावी तैनातियों में से एक का प्रतिनिधित्व करते हैं। आपके उत्पाद प्रलेखन, समस्या निवारण गाइड, ऑर्डर प्रबंधन प्रणाली और नीति डेटाबेस पर एक RAG पाइपलाइन द्वारा समर्थित एक ग्राहक सेवा AI सामान्य प्रतिक्रियाएँ उत्पन्न करने के बजाय एक ग्राहक की वास्तविक स्थिति के बारे में विशिष्ट, सटीक प्रश्नों का उत्तर दे सकती है जो ग्राहकों को विशिष्ट जानकारी के लिए मानव एजेंटों को भेजती हैं जिसकी उन्हें आवश्यकता थी।
व्यावसायिक मामला सीधा है। सटीक प्रथम-संपर्क समाधान समर्थन लागत कम करता है, मानव एजेंटों के लिए वृद्धि को कम करता है, और बेहतर ग्राहक परिणाम उत्पन्न करता है। तकनीकी आधार जो AI सिस्टम के लिए सटीक प्रथम-संपर्क समाधान को संभव बनाता है, लगभग हमेशा RAG है। पुनर्प्राप्ति के बिना, मॉडल वर्तमान, ग्राहक-विशिष्ट जानकारी तक नहीं पहुँच सकता जो सटीक समर्थन प्रतिक्रियाओं के लिए आवश्यक है।
अनुपालन और नियामक अनुप्रयोग
वित्तीय सेवाएँ, स्वास्थ्य देखभाल, कानूनी और अन्य भारी रूप से विनियमित उद्योग अनुपालन टीमों को जटिल, अक्सर अद्यतन किए गए नियम सेटों को अधिक कुशलता से नेविगेट करने में मदद करने के लिए नियामक दस्तावेज़ सेटों पर RAG AI तैनात कर रहे हैं। एक अनुपालन अधिकारी जो लागू विनियमों, मार्गदर्शन दस्तावेज़ों और आंतरिक नीति ढाँचों के पूर्ण पाठ पर एक RAG सिस्टम को क्वेरी कर सकता है और विशिष्ट अनुपालन प्रश्नों के सटीक, स्रोतित उत्तर प्राप्त कर सकता है, स्मृति या मैन्युअल दस्तावेज़ समीक्षा पर निर्भर एक व्यक्ति की तुलना में अधिक कुशलता और अधिक आत्मविश्वास के साथ काम करता है।
अनुपालन संदर्भों में RAG सिस्टम की उद्धरण क्षमता विशेष रूप से मूल्यवान है। एक उत्तर जो उस विशिष्ट नियामक पैराग्राफ का हवाला देता है जिससे वह आकर्षित होता है, उस तरह से सत्यापन योग्य और बचाव योग्य है जैसे बिना स्रोत के AI-उत्पन्न उत्तर नहीं है। यह अंतर अत्यंत महत्वपूर्ण होता है जब उत्तर नियामक परिणामों वाले निर्णय को सूचित करता है।
संवेदनशील नियामक और अनुपालन डेटा से जुड़े RAG सिस्टम पर AI सुरक्षा आवश्यकताएँ कैसे लागू होती हैं, इसे समझने से संगठनों को ऐसे पुनर्प्राप्ति पाइपलाइन बनाने में मदद मिलती है जो वे अनुक्रमित दस्तावेज़ों में उचित एक्सेस नियंत्रण बनाए रखते हैं।

एक RAG सिस्टम बनाना जो वास्तव में काम करता है
डेटा गुणवत्ता समस्या जिसे अधिकांश प्रोजेक्ट कम आँकते हैं
RAG सिस्टम केवल उतने ही अच्छे हैं जितनी वे सामग्री से पुनः प्राप्त करते हैं। AI इंटरफ़ेस के निर्माण के रोमांचक हिस्से तक पहुँचने के लिए डेटा गुणवत्ता मूल्यांकन के पार दौड़ने वाले संगठन लगातार पाते हैं कि पुनर्प्राप्ति गुणवत्ता प्रतिक्रिया गुणवत्ता को भाषा मॉडल की पसंद की तुलना में कहीं अधिक निर्धारित करती है। खराब स्रोत दस्तावेज़, पुरानी सामग्री, असंगत रूप से स्वरूपित जानकारी, और ज्ञान आधार जिनका रखरखाव नहीं किया गया है, RAG सिस्टम उत्पन्न करते हैं जो गलत सामग्री पुनः प्राप्त करते हैं और ऐसी प्रतिक्रियाएँ उत्पन्न करते हैं जो कोई जानकारी नहीं के बजाय बुरी जानकारी में आधारित हैं।
व्यावहारिक निहितार्थ यह है कि ज्ञान आधार तैयारी एक प्रारंभिक चरण नहीं है जिसे वास्तविक कार्य शुरू होने से पहले जल्दी से पूरा किया जाना चाहिए। यह परियोजना का एक मुख्य हिस्सा है जो यह निर्धारित करता है कि तैनात सिस्टम उपयोगी है या नहीं। दस्तावेज़ गुणवत्ता समीक्षा, सामग्री वर्तमानता मूल्यांकन, परस्पर विरोधी संस्करणों का डुप्लीकेशन हटाना, और एक्सेस नियंत्रण मानचित्रण सभी अनुक्रमण अवसंरचना के निर्माण से पहले होने चाहिए।
खंडन रणनीति डाउनस्ट्रीम हर चीज़ को प्रभावित करती है
अनुक्रमण से पहले स्रोत दस्तावेज़ों को पुनर्प्राप्ति योग्य इकाइयों में कैसे विभाजित किया जाता है, इसका पुनर्प्राप्ति गुणवत्ता पर एक बड़ा प्रभाव पड़ता है जब अधिकांश टीमें RAG सिस्टम बनाना शुरू करती हैं। ऐसे खंड जो बहुत छोटे हैं, संदर्भ संबंधी जानकारी खो देते हैं जो उनकी सामग्री को सार्थक बनाती है। ऐसे खंड जो बहुत बड़े हैं, प्रासंगिक से अधिक पुनः प्राप्त करते हैं और भाषा मॉडल द्वारा सटीक प्रतिक्रियाएँ उत्पन्न करने के लिए उपयोग किए जाने वाले संकेत को पतला करते हैं। इष्टतम खंडन रणनीति ज्ञान आधार में दस्तावेज़ प्रकारों, विशिष्ट क्वेरी की प्रकृति और उपयोग किए जा रहे भाषा मॉडल की संदर्भ विंडो पर निर्भर करती है।
उपयोगकर्ताओं को तैनात करने से पहले प्रतिनिधि क्वेरी के साथ पुनर्प्राप्ति गुणवत्ता का परीक्षण करना खंडन समस्याओं को सामने लाता है जब उन्हें अभी भी संबोधित किया जा सकता है, उपयोगकर्ताओं द्वारा असंगत प्रतिक्रिया गुणवत्ता का अनुभव करने के बाद नहीं।
RAG कार्यान्वयन कार्यप्रणाली पर एक व्यापक AI गाइड संगठनों को विकास के दौरान सबसे तकनीकी रूप से दिलचस्प निर्णयों के बजाय उत्पादन गुणवत्ता को सबसे अधिक प्रभावित करने वाले निर्णयों के आसपास अपनी निर्माण प्रक्रिया की संरचना करने में मदद करता है।
जानने योग्य बातें
संगठन आमतौर पर अपनी पहली तैनाती के दौरान या उसके बाद RAG AI के बारे में कुछ महत्वपूर्ण वास्तविकताओं की खोज करते हैं:
पुनर्प्राप्ति गुणवत्ता और जनरेशन गुणवत्ता अलग समस्याएँ हैं जिनके लिए अलग मूल्यांकन की आवश्यकता है। एक RAG सिस्टम सही सामग्री पुनः प्राप्त कर सकता है और एक खराब संश्लेषित प्रतिक्रिया उत्पन्न कर सकता है, या गलत सामग्री पुनः प्राप्त कर सकता है और एक धाराप्रवाह प्रतिक्रिया उत्पन्न कर सकता है जो सटीक लगती है लेकिन नहीं है। एंड-टू-एंड सिस्टम प्रदर्शन का मूल्यांकन करने से पहले दोनों घटकों का स्वतंत्र रूप से परीक्षण करना यह पहचानता है कि समस्याएँ वास्तव में कहाँ हैं।
RAG मतिभ्रम को समाप्त नहीं करता है, यह इसे कम करता है। एक भाषा मॉडल जो पुनः प्राप्त संदर्भ से एक प्रतिक्रिया उत्पन्न कर रहा है, अभी भी पुनः प्राप्त सामग्री की गलत व्याख्या करके, जानकारी को गलत तरीके से जोड़कर, या पुनः प्राप्त संदर्भ में मौजूद नहीं विवरण उत्पन्न करके गलत सामग्री उत्पन्न कर सकता है। अच्छे पुनर्प्राप्ति के बिना मतिभ्रम जोखिम अच्छे पुनर्प्राप्ति के साथ काफी कम होता है, लेकिन उच्च-दांव वाले अनुप्रयोगों के लिए मानव समीक्षा महत्वपूर्ण बनी हुई है।
एम्बेडिंग मॉडल की पसंद पुनर्प्राप्ति गुणवत्ता को महत्वपूर्ण रूप से प्रभावित करती है। विभिन्न एम्बेडिंग मॉडल विभिन्न प्रकार की सामग्री पर बेहतर प्रदर्शन करते हैं। सामान्य पाठ पुनर्प्राप्ति के लिए अनुकूलित एक मॉडल तकनीकी प्रलेखन, कानूनी भाषा या डोमेन-विशिष्ट शब्दावली पर खराब प्रदर्शन कर सकता है। एम्बेडिंग मॉडल के लिए प्रतिबद्ध होने से पहले अपने वास्तविक दस्तावेज़ प्रकारों और क्वेरी पैटर्न के साथ पुनर्प्राप्ति गुणवत्ता का परीक्षण करना बाद में महंगे पुनर्निर्माण को रोकता है।
ज्ञान आधार रखरखाव एक चालू परिचालन कार्य है, एक-समय सेटअप कार्य नहीं। जैसे-जैसे स्रोत दस्तावेज़ अद्यतन किए जाते हैं, नई सामग्री जोड़ी जाती है, और पुरानी सामग्री भ्रामक हो जाती है, RAG ज्ञान आधार को तदनुसार अद्यतन किया जाना चाहिए। ऐसे संगठन जो प्रारंभिक अनुक्रमण को ज्ञान आधार कार्य के पूरा होने के रूप में मानते हैं, ऐसे सिस्टम के साथ समाप्त होते हैं जिनकी सटीकता बिगड़ती है क्योंकि अनुक्रमित सामग्री और वर्तमान वास्तविकता के बीच की खाई बढ़ती है।
एक्सेस नियंत्रण को पुनर्प्राप्ति समय पर लागू किया जाना चाहिए, न केवल ज्ञान आधार इनजेशन पर। एक उपयोगकर्ता जिसे कुछ दस्तावेज़ नहीं देखने चाहिए, उसे उन दस्तावेज़ों में आधारित प्रतिक्रियाएँ प्राप्त नहीं होनी चाहिए, भले ही दस्तावेज़ सिस्टम में अनुक्रमित हों। पुनर्प्राप्ति-समय अनुमति प्रवर्तन एक सुरक्षा आवश्यकता है, एक वैकल्पिक संवर्द्धन नहीं।
30% नियम RAG तैनाती योजना पर उपयोगी रूप से लागू होता है। AI पुनर्प्राप्ति और संश्लेषण को मोटे तौर पर 30% ज्ञान कार्य, खोज और संश्लेषण घटक को संभालना चाहिए, जबकि मानव विशेषज्ञता निर्णय, व्याख्या और परिणामी निर्णय लेने को संभालती है जो शेष 70% का गठन करती है। इस संतुलन के आसपास RAG तैनाती डिज़ाइन करना ऐसे सिस्टम बनाता है जो वास्तव में मानव ज्ञान कार्य को बढ़ाते हैं, उस निर्णय को बदलने की कोशिश करने के बजाय जिसे अभी भी लोगों के पास रहना चाहिए।
RAG AI व्यवसाय AI के लिए मानक वास्तुकला क्यों बन रहा है
एंटरप्राइज़ AI अपनाने के व्यापक संदर्भ में RAG AI क्या है? यह वह वास्तुशिल्प पैटर्न है जो भाषा मॉडलों को विशिष्ट, वर्तमान, संगठनात्मक ज्ञान कार्यों के लिए व्यावहारिक रूप से उपयोगी बनाता है जिन्हें व्यवसायों को वास्तव में AI को संभालने की आवश्यकता होती है। एक भाषा मॉडल की तर्क करने, संश्लेषित करने और प्राकृतिक भाषा में संवाद करने की क्षमता का संयोजन और एक पुनर्प्राप्ति प्रणाली की वर्तमान, विशिष्ट, सत्यापन योग्य जानकारी तक पहुँच कुछ ऐसा उत्पन्न करता है जो कोई भी घटक अकेले प्रदान नहीं करता।
ऐसे संगठन जिन्होंने मानक भाषा मॉडल तैनात किए हैं और मतिभ्रम, पुराने ज्ञान और कंपनी-विशिष्ट प्रश्नों को संभालने में असमर्थता से निराश हो गए हैं, अक्सर सही तकनीक को गलत वास्तुकला में तैनात कर रहे हैं। समान मॉडल, अच्छी तरह से बनाए गए ज्ञान आधारों पर अच्छी तरह से निर्मित पुनर्प्राप्ति पाइपलाइनों से जुड़े, नाटकीय रूप से भिन्न और नाटकीय रूप से अधिक उपयोगी परिणाम उत्पन्न करते हैं।
RAG सिस्टम बनाने की तकनीकी बाधा पिछले दो वर्षों में काफी कम हो गई है। फ्रेमवर्क, वेक्टर डेटाबेस और होस्टेड पुनर्प्राप्ति अवसंरचना जो RAG को व्यावहारिक बनाते हैं, परिपक्व हैं, अच्छी तरह से प्रलेखित हैं, और बिना विशेष AI अनुसंधान पृष्ठभूमि वाली इंजीनियरिंग टीमों के लिए सुलभ हैं। जो सफल RAG तैनातियों को निराशाजनक तैनातियों से अलग करता है वह तकनीकी परिष्कार से कम और ज्ञान आधारों को ठीक से तैयार करने, पुनर्प्राप्ति गुणवत्ता का कठोरता से मूल्यांकन करने और सिस्टम को एक पूर्ण परियोजना के बजाय एक जीवित परिचालन संपत्ति के रूप में बनाए रखने के संगठनात्मक अनुशासन के बारे में अधिक है।
अक्सर पूछे जाने वाले प्रश्न
GPT और RAG के बीच क्या अंतर है?
GPT एक प्रकार का बड़ा भाषा मॉडल है जो पूरी तरह से प्रशिक्षण के दौरान सीखे गए पैटर्न के आधार पर प्रतिक्रियाएँ उत्पन्न करता है, जबकि RAG एक वास्तुशिल्प दृष्टिकोण है जो GPT सहित किसी भी भाषा मॉडल को बाहरी ज्ञान स्रोतों से जोड़ता है जो प्रतिक्रिया समय पर मॉडल के संदर्भ में पुनः प्राप्त और शामिल किए जाते हैं। बिना पुनर्प्राप्ति के GPT केवल प्रशिक्षण डेटा से उत्तर देता है, जबकि एक GPT-आधारित RAG सिस्टम अपनी प्रतिक्रिया उत्पन्न करने से पहले प्रासंगिक वर्तमान जानकारी पुनः प्राप्त करता है, ऐसे उत्तर उत्पन्न करता है जो प्रशिक्षण डेटा सामान्यीकरण के बजाय विशिष्ट, सत्यापन योग्य स्रोतों में आधारित हैं।
RAG और जनरेटिव AI के बीच क्या अंतर है?
जनरेटिव AI AI सिस्टम की व्यापक श्रेणी है जो पाठ, छवियों और ऑडियो सहित नई सामग्री का उत्पादन करते हैं, जबकि RAG पाठ-उत्पन्न करने वाले AI पर लागू एक विशिष्ट तकनीक है जो एक पुनर्प्राप्ति चरण के साथ जनरेशन को बढ़ाती है जो मॉडल द्वारा अपनी प्रतिक्रिया उत्पन्न करने से पहले बाहरी स्रोतों से प्रासंगिक जानकारी खींचती है। सभी RAG सिस्टम जनरेटिव AI हैं, लेकिन अधिकांश जनरेटिव AI सिस्टम RAG सिस्टम नहीं हैं। RAG एक वास्तुशिल्प संवर्द्धन है जो जनरेटिव AI को ज्ञान-गहन कार्यों के लिए अधिक सटीक और वर्तमान बनाता है।
RAG बनाम LLM क्या है?
एक LLM एक भाषा मॉडल है जो प्रशिक्षण डेटा के आधार पर पाठ उत्पन्न करता है, जबकि RAG एक वास्तुकला है जो एक LLM को एक पुनर्प्राप्ति प्रणाली के साथ जोड़ती है ताकि मॉडल केवल प्रशिक्षण डेटा के बजाय पुनः प्राप्त दस्तावेज़ों में आधारित प्रतिक्रियाएँ उत्पन्न करे। एक RAG सिस्टम में LLM भाषा समझ और जनरेशन को संभालता है जबकि पुनर्प्राप्ति घटक प्रत्येक क्वेरी के लिए प्रासंगिक वर्तमान, विशिष्ट जानकारी खोजने को संभालता है। एक साथ वे ऐसे आउटपुट उत्पन्न करते हैं जो किसी भी घटक के स्वतंत्र रूप से उत्पादित होने की तुलना में अधिक सटीक, सत्यापन योग्य और संगठनात्मक रूप से प्रासंगिक हैं।
RAG किन समस्याओं को हल करता है?
RAG मुख्य रूप से तीन समस्याओं को हल करता है: प्रशिक्षण कटऑफ सीमा जो मानक LLM को हाल की घटनाओं या वर्तमान जानकारी के बारे में प्रश्नों का उत्तर देने में असमर्थ बनाती है, दायरे की सीमा जो मॉडलों को मालिकाना संगठनात्मक ज्ञान के बारे में जानने से रोकती है जो कभी सार्वजनिक प्रशिक्षण डेटा में नहीं था, और मतिभ्रम समस्या जहाँ मॉडल प्रशंसनीय लेकिन गलत प्रतिक्रियाएँ उत्पन्न करते हैं जब उनके पास एक प्रश्न के लिए आवश्यक विशिष्ट ज्ञान की कमी होती है। प्रतिक्रियाएँ उत्पन्न करने से पहले प्रासंगिक सामग्री पुनः प्राप्त करके, RAG AI आउटपुट को सांख्यिकीय पैटर्न के बजाय सत्यापन योग्य स्रोतों में आधारित करता है, ऐसे उत्तर उत्पन्न करता है जिनकी जाँच की जा सकती है, उद्धृत किया जा सकता है, और व्यवसाय-महत्वपूर्ण अनुप्रयोगों के लिए विश्वास किया जा सकता है।
कौन सी 3 नौकरियाँ AI से बच जाएँगी?
AI विस्थापन के लिए सबसे लचीली काम की तीन श्रेणियाँ ऐसी भूमिकाएँ हैं जिनमें अनसंरचित वातावरण में भौतिक दुनिया की बातचीत और निपुणता की आवश्यकता होती है, ऐसी भूमिकाएँ जो जटिल मानव निर्णय, नैतिक तर्क और परिणामी निर्णयों के लिए जवाबदेही पर केंद्रित हैं, और ऐसी भूमिकाएँ जो पारस्परिक विश्वास, भावनात्मक बुद्धिमत्ता और संबंध प्रबंधन के आसपास बनी हैं। RAG AI और समान सिस्टम ज्ञान पुनर्प्राप्ति और संश्लेषण को अत्यधिक स्वचालित बना रहे हैं, जो विशिष्ट रूप से मानव क्षमताओं के मूल्य को मजबूत करता है जिन पर ये भूमिकाएँ निर्भर करती हैं, बजाय सूचना प्रसंस्करण कार्यों के जिन्हें AI अब अधिक कुशलता से संभालता है।