
RAG AIとは何でしょうか。Retrieval-Augmented Generationは、large language modelが応答を生成する瞬間に外部の知識ソースに接続する技術であり、これによりモデルは訓練中に学習した内容だけに頼るのではなく、最新で具体的かつ検証可能な情報を取り込むことができます。その結果として、一般化された近似値ではなく実データで質問に答えるAIシステムが実現します。
標準的なAIアシスタントに自社の社内プロセスについて質問し、もっともらしく聞こえるものの完全に作り話の回答を受け取った経験がおありなら、RAGが解決するために設計された中核的な制約を体験されたことになります。言語モデルは、ある固定された時点までのデータで訓練されています。それらは、貴社の独自ドキュメント、現在の在庫、最新のポリシー、または訓練のカットオフ以降に起こったあらゆることについて何も知りません。RAGは、モデルに回答前に情報を検索するメカニズムを与えることで、この根本的な制約を変えます。これは、十分に準備されたアナリストが、完全に記憶だけで作業するのではなく、助言をする前に原典資料を参照するのと同じやり方です。正確性と具体性が重要な状況でAIを展開する企業にとって、RAG AIとは何でありどのように機能するかを理解することは、技術的な細部の問題ではありません。それは、実際に役立つAIと、自信を持ってもっともらしいナンセンスを生み出すAIとの違いです。

標準的な言語モデルが根本的な知識問題を抱える理由
訓練カットオフという制約
今日存在するすべてのlarge language modelは、明確な終了日を持つデータセットで訓練されています。その日付以降に起こったすべて、つまりすべてのポリシー変更、すべての製品アップデート、すべての規制動向、モデル訓練以降に作成されたすべての組織知識は、モデルにとって見えません。一般的な知識タスクではこの制約は管理可能です。基礎的な知識は緩やかにしか変化しないからです。最新かつ具体的な情報に対する正確性が目的のすべてとなるビジネス用途では、これは深刻な運用上の問題となります。
第二の制約はスコープです。可能な限り広範なデータセットで訓練された最大規模の言語モデルでさえ、訓練データに一度も含まれなかった情報については何も知りません。貴社の社内ナレッジベース、顧客契約、技術ドキュメント、価格構造、運用手順は、ほぼ確実にどの公開訓練データセットにも含まれていませんでした。これらのトピックに関する質問に答えるモデルは、自身が知っている情報を取り出しているのではありません。訓練のパターンに基づいて回答らしく聞こえるテキストを生成しているのであり、このプロセスは、流暢で自信に満ちた応答を生み出しますが、実際の事実とは何の関係もない可能性があります。
この現象にはAI研究上の名前があります。hallucinationです。これは、言語モデルが事実として誤った情報を、正確な情報と同じ自信に満ちた口調で提示する傾向を表現します。カジュアルなユースケースでは、hallucinationは不便さに過ぎません。法務、医療、財務、または運用の場でのビジネス用途では、それは責任問題です。
RAGがいかにして両方の問題を同時に解決するか
RAG AIが具体的に何を解決するかというと、単一のアーキテクチャ追加によって、カットオフ問題とスコープ問題の両方に対処します。訓練データだけからモデルに回答させるのではなく、RAGシステムはクエリ時に外部ソースから関連するドキュメントやデータを取得し、その取得したコンテンツをモデルが応答を生成するために使用するコンテキストに含めます。
モデルは、貴社の返金ポリシーが何を述べているかを推測しているのではありません。応答前に実際のポリシー文書を取得したのです。第3四半期の収益数値を推定しているのではありません。回答前に貴社の財務システムから実際の数値を引き出したのです。モデルの役割は、唯一の知識ソースから、取得された情報の知的な統合者へと移行し、これは言語モデルが極めて得意とするタスクです。
このアーキテクチャの移行は、hallucinationの修正をはるかに超える意味合いを持ちます。それは、AIシステムが、モデルを再訓練するのではなく、その知識ソースを更新することで更新可能になることを意味します。応答が情報源を引用できるため、検証が容易になることを意味します。そして、組織が、その知識を訓練データセットに含める必要なく、真に機密性の高い社内知識にアクセスできるAIシステムを構築できることを意味します。
RAG AIが実際にどのように機能するか
Retrievalパイプラインの解説
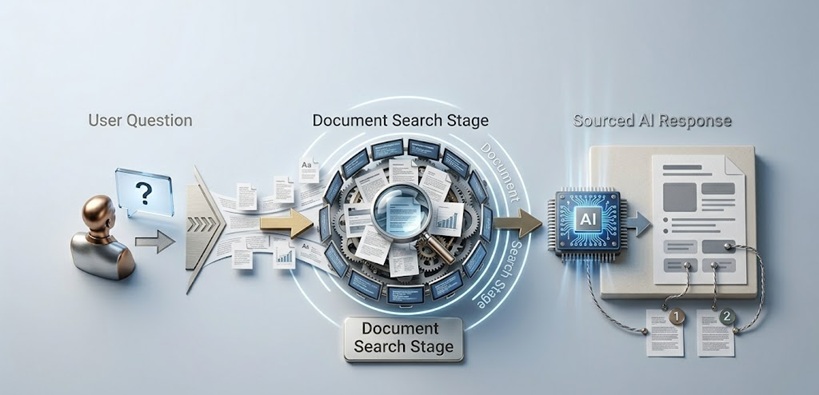
RAGシステムには、言語モデルが応答の一語を生成する前に、順次動作する2つの主要なコンポーネントがあります。
第一のコンポーネントは、ナレッジベースとそのインデックス化インフラストラクチャです。AIが参照できるようにすべきドキュメント、レコード、ウェブページ、データベースエントリ、その他あらゆる情報が処理され、キーワードだけでなく意味によって検索可能な形で保存されます。これには通常、テキストをembeddingsと呼ばれる数値表現に変換することが含まれます。embeddingsは、数学的に類似したコンテンツが一緒に取得できる形で意味を捉えます。顧客返金プロセスに関する質問は、返品、交換、満足保証に関するコンテンツを取得します。たとえそれらの正確な単語がクエリに現れなくてもです。
第二のコンポーネントは、ユーザーがクエリを送信したときに有効化されるretrievalメカニズムです。クエリは、保存されたドキュメントと同じembedding形式に変換され、システムはクエリと意味的に最も類似した保存コンテンツを特定します。その取得されたコンテンツ、つまり質問されている内容に最も関連する文章、ドキュメント、レコードが集約され、元のクエリと一緒に言語モデルに渡されます。
その後、言語モデルは、必要とされる特定の事実について訓練データに頼るのではなく、その取得されたコンテキストに基づいて応答を生成します。訓練データは、モデルの言語能力、推論能力、一般的な世界知識のためには引き続き重要です。しかし、応答の具体的な事実的内容は、取得された材料から得られます。
| RAGシステムのコンポーネント | 役割 | 重要性 |
|---|---|---|
| Document Ingestion | ソースドキュメントをインデックス化のために処理しチャンク化する | システムがアクセスできる知識を決定する |
| Embedding Model | テキストを意味的なベクトル表現に変換する | キーワードマッチングではなく意味ベースのretrievalを可能にする |
| Vector Database | 高速な類似性検索のためにembeddingsを保存する | retrievalをリアルタイム使用に十分な速さにする |
| Retrievalメカニズム | 各クエリに対して最も関連するコンテンツを特定する | 取得されたコンテキストの精度を決定する |
| Language Model | 取得されたコンテンツに基づいて応答を生成する | 取得された事実から一貫した統合済み出力を生成する |
| ソース帰属 | 各応答に情報を与えたドキュメントを追跡する | 検証を可能にしユーザーの信頼を構築する |
RAGパイプラインにおける AI architectureの決定が、retrieval品質と応答精度の両方にどう影響するかを理解することは、デモでは良好で本番では一貫性のない動作ではなく、信頼性高く機能するシステムを組織が構築する助けとなります。
RAG対標準LLM:実務で違いが現れる場所
RAG AIとは何か、そして標準LLMが何をするかの区別は、標準モデルが失敗しRAGシステムが成功する具体的なシナリオで最も顕著になります。
組織の現行データ保持ポリシーについて尋ねられた標準LLMは、訓練データからの一般的なデータ保持慣行に基づいて応答を生成します。それはまさに正しいように聞こえるかもしれません。それはほぼ確実に貴社の実際のポリシーを記述してはいません。同じ質問を受けたRAGシステムは、貴社の実際のポリシー文書を取得し、その文書が述べていることに基づいて応答を生成します。言語は似ています。精度はカテゴリーレベルで異なります。
昨日提出された顧客の苦情について尋ねられた標準LLMは、あなたが何について話しているのか見当もつきません。その苦情は訓練後のものです。CRMに接続されたRAGシステムは、苦情レコードを取得し、その特定の顧客の状況の実際の詳細を反映した応答を生成します。
アップロードした研究レポートからの主要な発見をまとめるよう求められた標準LLMは、もっともらしく聞こえる要約を生成するかもしれませんが、重要な発見を省いたり、結論を誤って表現したり、ドキュメントの異なる部分からの詳細を不正確に組み合わせたりする可能性があります。RAGシステムは、要約リクエストに最も関連する特定のセクションを取得し、実際のテキストに基づいた出力を生成します。
| シナリオ | 標準LLMの応答 | RAG AIの応答 |
|---|---|---|
| 社内ポリシーの質問 | 貴社のポリシーに特化しないもっともらしい汎用回答を生成 | 実際のポリシー文書を取得しその内容から回答 |
| 最近の出来事に関する質問 | 情報がないと述べるか古い回答を生成 | 接続されたナレッジベースから現行情報を取得 |
| 顧客固有の問い合わせ | 個別の顧客データにアクセスできない | 関連する顧客レコードを取得し正確に応答 |
| 技術ドキュメントのクエリ | 技術的詳細をhallucinateする可能性 | 具体的なドキュメントセクションを取得し引用 |
| 競合インテリジェンス | 訓練データに限定され、しばしば古い | 接続されたソースから現行情報を取得 |
| コンプライアンスの質問 | 一般的な規制知識から回答 | 適用ルールと組織固有の手順を取得 |
企業がRAG AIを最も効果的に展開している場所
社内ナレッジマネジメント
社内ナレッジマネジメントのユースケースは、RAG AIが最も明確なビジネス価値を提供する領域です。ほとんどの組織には、ドキュメントリポジトリ、wiki、過去のプロジェクトファイル、ポリシー文書、コミュニケーションにわたって分散した相当な制度的知識があり、従業員はそれらを手動で検索することにかなりの時間を費やしています。そのナレッジベース上のRAGシステムは、それを、スタッフが自然言語でクエリでき、ソース付きの正確な回答を受け取れる、会話可能なリソースに変えます。
ここでの累積価値は実質的です。組織知識を頭に持っている経験豊富な従業員は、最終的には去っていきます。存在するけれど見つけにくいドキュメントは、機能的には存在しないドキュメントとほぼ同じくらいアクセス不可能です。RAGシステムは、勤続年数に関係なくすべてのスタッフに組織知識をアクセス可能にし、情報を検索する時間を削減し、従業員にどこを見るかを知ることを要求するのではなく、必要なコンテキストで関連知識を表面化させます。
エンタープライズRAGプラットフォームにおける AI featuresが取得されたコンテンツへのアクセス制御をどう扱うかを検討することは、このユースケースに不可欠です。組織のすべての知識がすべての従業員に等しくアクセス可能であるべきではないからです。適切に構成されたRAGシステムは、ナレッジベース内のすべてではなく、クエリを行うユーザーがアクセス権限を持つコンテンツのみを取得します。
顧客向けサポートとサービス
RAG搭載の顧客サービスアプリケーションは、この技術の最も商業的にインパクトのある展開の1つを表します。製品ドキュメント、トラブルシューティングガイド、注文管理システム、ポリシーデータベース上のRAGパイプラインに支えられた顧客サービスAIは、必要だった具体的な情報のために顧客を人間のエージェントに送る汎用応答を生成するのではなく、顧客の実際の状況についての具体的で正確な質問に答えることができます。
ビジネスケースは明快です。正確な初回接触解決は、サポートコストを削減し、人間のエージェントへのエスカレーションを削減し、より良い顧客アウトカムを生み出します。AIシステムにとって正確な初回接触解決を可能にする技術的基盤は、ほぼ常にRAGです。retrievalなしでは、モデルは、正確なサポート応答が必要とする現行の顧客固有情報にアクセスできません。
コンプライアンスおよび規制アプリケーション
金融サービス、ヘルスケア、法務、その他の高度に規制された業界は、コンプライアンスチームが複雑で頻繁に更新されるルールセットをより効率的にナビゲートできるよう、規制文書セット上にRAG AIを展開しています。適用される規制、ガイダンス文書、社内ポリシーフレームワークの全文上でRAGシステムにクエリでき、具体的なコンプライアンスの質問に対する正確でソース付きの回答を受け取れるコンプライアンス担当者は、記憶や手動の文書レビューに頼る人よりも効率的かつ自信を持って働きます。
RAGシステムの引用機能は、コンプライアンスの文脈で特に価値があります。引用元の特定の規制段落を引用する回答は、ソースなしのAI生成回答にはない方法で検証可能かつ防御可能です。その違いは、回答が規制上の結果をもたらす決定に情報を与える場合に、絶大な意味を持ちます。
機密性の高い規制およびコンプライアンスデータに接続されたRAGシステムに AI security要件がどう適用されるかを理解することは、組織がインデックス化するドキュメント全体にわたって適切なアクセス制御を維持するretrievalパイプラインを構築する助けとなります。

実際に機能するRAGシステムの構築
ほとんどのプロジェクトが過小評価するデータ品質問題
RAGシステムは、それが取得するコンテンツに見合った品質しか持ちません。データ品質評価を急ぎ足で済ませてAIインターフェース構築の刺激的な部分に進む組織は、一貫して、retrieval品質が言語モデルの選択以上に応答品質を決定することを発見します。質の低いソースドキュメント、古いコンテンツ、フォーマットが一貫しない情報、メンテナンスされていないナレッジベースは、誤ったコンテンツを取得し、情報なしではなく悪い情報に基づいた応答を生成するRAGシステムを生み出します。
実務上の含意は、ナレッジベース準備は、本格的な作業が始まる前に素早く完了させるべき予備ステップではないということです。それは、展開されたシステムが有用かどうかを決定するプロジェクトのコア部分です。ドキュメント品質レビュー、コンテンツの新しさの評価、矛盾するバージョンの重複排除、アクセス制御マッピングは、すべてインデックス化インフラストラクチャが構築される前に行われる必要があります。
Chunking戦略は下流のすべてに影響する
ソースドキュメントがインデックス化前にどのように取得可能な単位に分割されるかは、RAGシステムを構築し始めたときにほとんどのチームが気づくよりも、retrieval品質に大きな影響を与えます。小さすぎるchunkは、内容を意味のあるものにする文脈情報を失います。大きすぎるchunkは、関連する以上のものを取得し、言語モデルが正確な応答を生成するために使用するシグナルを希釈します。最適なchunking戦略は、ナレッジベース内のドキュメントタイプ、典型的なクエリの性質、使用される言語モデルのコンテキストウィンドウに依存します。
代表的なクエリでretrieval品質をテストしてからユーザーに展開することで、ユーザーが応答品質の不一致を経験した後ではなく、まだ対処できるうちにchunkingの問題が表面化します。
RAG実装方法論に関する包括的な AI guideは、組織が、開発中に最も技術的に興味深い決定ではなく、本番品質に最も影響する決定を中心に構築プロセスを構造化する助けとなります。
知っておくべきこと
組織が最初の展開中または後に通常発見するRAG AIに関するいくつかの重要な現実:
retrieval品質と生成品質は、別々の評価を必要とする別々の問題です。RAGシステムは、正しいコンテンツを取得して下手に統合された応答を生成することも、誤ったコンテンツを取得して正確に聞こえるが実はそうではない流暢な応答を生成することもあります。エンドツーエンドのシステム性能を評価する前に両方のコンポーネントを独立してテストすることで、問題が実際にどこにあるかが特定されます。
RAGはhallucinationを排除するのではなく、減らします。取得されたコンテキストから応答を生成する言語モデルは、依然として、取得された材料を誤解したり、情報を誤って組み合わせたり、取得されたコンテキストに存在しない詳細を生成したりすることで、不正確なコンテンツを生み出す可能性があります。hallucinationリスクは、良いretrievalがあれば、それなしの場合よりも実質的に低くなりますが、高リスクの用途では人間によるレビューが依然として重要です。
Embeddingモデルの選択はretrieval品質に大きく影響します。異なるembeddingモデルは、異なるタイプのコンテンツで異なるパフォーマンスを示します。汎用テキストretrievalに最適化されたモデルは、技術ドキュメント、法律言語、ドメイン固有の用語では性能が低い可能性があります。embeddingモデルにコミットする前に、実際のドキュメントタイプとクエリパターンでretrieval品質をテストすることが、後の高価な再アーキテクチャを防ぎます。
ナレッジベースのメンテナンスは、1回限りのセットアップタスクではなく、継続的な運用機能です。ソースドキュメントが更新され、新しいコンテンツが追加され、古いコンテンツが誤解を招くようになるにつれ、RAGナレッジベースは相応に更新される必要があります。最初のインデックス化をナレッジベース作業の完了と扱う組織は、インデックス化されたコンテンツと現在の現実との間のギャップが広がるにつれて精度が低下するシステムに行き着きます。
アクセス制御は、ナレッジベースの取り込み時だけでなく、retrieval時に強制される必要があります。特定のドキュメントを見るべきでないユーザーは、そのドキュメントがシステムにインデックス化されていても、そのドキュメントに基づく応答を受け取るべきではありません。Retrieval時の権限強制は、オプションの拡張機能ではなく、セキュリティ要件です。
30%ルールはRAG展開計画に有用に適用されます。AI retrievalと統合は知識作業の約30%、つまり検索と統合のコンポーネントを担当すべきであり、人間の専門知識が残りの70%を構成する判断、解釈、結果を伴う意思決定を担当します。このバランスを中心にRAG展開を設計することで、人々に残るべき判断を置き換えようとするのではなく、人間の知識作業を真に増強するシステムが作られます。
RAG AIがビジネスAIの標準アーキテクチャになりつつある理由
エンタープライズAI導入のより広い文脈におけるRAG AIとは何でしょうか。それは、ビジネスが実際にAIに処理させる必要のある、具体的で現行の組織知識タスクに対して言語モデルを実用的に有用にするアーキテクチャパターンです。推論し、統合し、自然言語でコミュニケーションする言語モデルの能力と、現行で具体的かつ検証可能な情報へのretrievalシステムのアクセスとの組み合わせは、どちらのコンポーネントも単独では提供しないものを生み出します。
標準的な言語モデルを展開し、hallucination、古い知識、企業固有の質問を処理できないことに失望した組織は、しばしば正しい技術を誤ったアーキテクチャで展開しています。よく維持されたナレッジベース上のよく構築されたretrievalパイプラインに接続された同じモデルは、劇的に異なり、劇的により有用な結果を生み出します。
RAGシステムを構築する技術的障壁は、過去2年間で大幅に低下しました。RAGを実用的にするフレームワーク、vector database、ホストされたretrievalインフラストラクチャは、成熟し、よく文書化され、専門的なAI研究背景のないエンジニアリングチームにとってアクセス可能です。成功するRAG展開を失望するものから分けるのは、技術的洗練度ではなく、ナレッジベースを適切に準備し、retrieval品質を厳密に評価し、システムを完了したプロジェクトではなく生きた運用資産として維持する組織的規律です。
よくあるご質問
GPTとRAGの違いは何ですか?
GPTは、訓練中に学習したパターンに完全に基づいて応答を生成するlarge language modelの一種である一方、RAGは、GPTを含むあらゆる言語モデルを、応答時にモデルのコンテキストに取得され含められる外部知識ソースに接続するアーキテクチャ的アプローチです。 retrievalなしのGPTは訓練データだけから回答する一方、GPTベースのRAGシステムは応答を生成する前に関連する現行情報を取得し、訓練データの一般化ではなく具体的で検証可能なソースに基づいた回答を生み出します。
RAGと生成AIの違いは何ですか?
生成AIは、テキスト、画像、音声を含む新しいコンテンツを生成するAIシステムの広いカテゴリーである一方、RAGは、モデルが応答を生成する前に外部ソースから関連情報を引き出すretrievalステップで生成を強化する、テキスト生成AIに適用される具体的な技術です。 すべてのRAGシステムは生成AIですが、ほとんどの生成AIシステムはRAGシステムではありません。RAGは、知識集約的タスクに対して生成AIをより正確かつ現行のものにするアーキテクチャ的拡張です。
RAG対LLMとは?
LLMは訓練データに基づいてテキストを生成する言語モデルである一方、RAGは、モデルが訓練データだけではなく取得されたドキュメントに基づいて応答を生成するように、LLMをretrievalシステムと組み合わせるアーキテクチャです。 RAGシステム内のLLMは言語理解と生成を担当する一方、retrievalコンポーネントは各クエリに関連する現行で具体的な情報の検索を担当します。一緒に、どちらのコンポーネントも独立して生み出すよりも、より正確で、検証可能で、組織的に関連性のある出力を生み出します。
RAGはどのような問題を解決しますか?
RAGは主に3つの問題を解決します。標準LLMが最近の出来事や現行情報に関する質問に答えられないようにする訓練カットオフの制約、モデルが公開訓練データになかった独自の組織知識について知ることを妨げるスコープの制約、そして、質問が要求する具体的な知識を欠くときにモデルがもっともらしいが不正確な応答を生成するhallucination問題です。 応答を生成する前に関連コンテンツを取得することで、RAGはAI出力を統計パターンではなく検証可能なソースに基づかせ、ビジネスクリティカルなアプリケーションのために確認、引用、信頼できる回答を生み出します。
AIから生き残る3つの仕事は何ですか?
AIによる代替に最も耐性のある3つの仕事カテゴリーは、非構造化環境での物理世界の相互作用と器用さを必要とする役割、複雑な人間の判断、倫理的推論、結果を伴う意思決定への責任を中心とする役割、そして、対人信頼、感情的知性、人間関係管理を中心に構築された役割です。 RAG AIや類似のシステムは知識retrievalと統合を高度に自動化可能にしており、これは、AIが現在より効率的に処理する情報処理タスクではなく、これらの役割が依存する明確に人間的な能力の価値を強化します。