
Apakah RAG AI? Retrieval-Augmented Generation merupakan satu teknik yang menghubungkan large language model kepada sumber pengetahuan luaran pada saat ia menjana respons, membolehkan model menarik maklumat semasa, khusus dan boleh disahkan dan bukan bergantung semata-mata kepada apa yang dipelajari semasa latihan. Hasilnya ialah satu sistem AI yang menjawab soalan dengan data sebenar berbanding anggaran umum.
Jika tuan/puan pernah bertanya pembantu AI standard tentang proses dalaman syarikat anda dan menerima jawapan yang kedengaran munasabah tetapi sepenuhnya direka, anda telah mengalami batasan utama yang direka untuk diselesaikan oleh RAG. Model bahasa dilatih dengan data sehingga satu titik masa yang tetap. Mereka tidak tahu apa-apa tentang dokumentasi milik anda, inventori semasa anda, dasar terkini anda, atau apa-apa yang berlaku selepas tarikh akhir latihan mereka. RAG mengubah batasan asas itu dengan memberi model satu mekanisme untuk mencari maklumat sebelum menjawab, sama seperti seorang penganalisis yang bersedia berunding dokumen sumber sebelum memberi nasihat berbanding bekerja sepenuhnya dari ingatan. Untuk perniagaan yang menggunakan AI dalam konteks di mana ketepatan dan kekhususan penting, memahami apa itu RAG AI dan bagaimana ia berfungsi bukan satu kehalusan teknikal. Ia adalah perbezaan antara AI yang benar-benar membantu dan satu yang dengan yakin menghasilkan karut yang munasabah.

Mengapa Model Bahasa Standard Mempunyai Masalah Pengetahuan Asas
Batasan Tarikh Akhir Latihan
Setiap large language model yang wujud hari ini dilatih dengan satu set data dengan tarikh tamat yang ditetapkan. Segala-galanya yang berlaku selepas tarikh tersebut, setiap perubahan dasar, setiap kemas kini produk, setiap perkembangan kawal selia, setiap kepingan pengetahuan organisasi yang dicipta sejak model dilatih, adalah tidak kelihatan kepadanya. Untuk tugas pengetahuan am, batasan ini boleh diuruskan kerana pengetahuan asas berubah perlahan. Untuk aplikasi perniagaan di mana ketepatan terhadap maklumat semasa dan khusus adalah seluruh matlamatnya, ia merupakan satu masalah operasi yang serius.
Batasan kedua ialah skop. Walaupun model bahasa terbesar yang dilatih dengan set data terluas yang mungkin tidak mempunyai pengetahuan tentang maklumat yang tidak pernah berada dalam data latihan mereka. Pangkalan pengetahuan dalaman syarikat anda, kontrak pelanggan anda, dokumentasi teknikal anda, struktur harga anda dan prosedur operasi anda hampir pasti tidak pernah berada dalam mana-mana set data latihan awam. Model yang menjawab soalan tentang topik-topik ini bukan mendapatkan semula maklumat yang ia tahu. Ia sedang menjana teks yang kedengaran seperti jawapan berdasarkan corak dalam latihannya, satu proses yang menghasilkan respons fasih dan yakin yang mungkin tiada hubungan dengan fakta sebenar.
Fenomena ini mempunyai nama dalam penyelidikan AI: hallucination. Ia menerangkan kecenderungan model bahasa untuk menjana maklumat yang salah secara fakta yang dipersembahkan dengan nada yakin yang sama seperti maklumat yang tepat. Untuk kes penggunaan kasual, hallucination merupakan satu kesulitan. Untuk aplikasi perniagaan dalam konteks undang-undang, perubatan, kewangan atau operasi, ia adalah satu liabiliti.
Bagaimana RAG Menangani Kedua-dua Masalah Sekaligus
Apakah RAG AI selesaikan secara khusus? Ia menangani kedua-dua masalah tarikh akhir dan masalah skop dengan satu penambahan seni bina tunggal. Daripada meminta model menjawab dari data latihan sahaja, sistem RAG mendapatkan dokumen atau data yang berkaitan dari sumber luaran pada masa pertanyaan dan menyertakan kandungan yang diperolehi tersebut dalam konteks yang model gunakan untuk menjana responsnya.
Model tidak meneka apa yang dikatakan oleh dasar bayaran balik anda. Ia mendapatkan semula dokumen dasar sebenar sebelum memberi respons. Ia tidak menganggar berapa angka hasil Q3 anda. Ia menarik angka sebenar dari sistem kewangan anda sebelum menjawab. Peranan model beralih dari sumber pengetahuan tunggal kepada penyintesis pintar maklumat yang diperolehi, satu tugas yang model bahasa lakukan dengan luar biasa baik.
Peralihan seni bina ini mempunyai implikasi yang melebihi pembaikan hallucination. Ia bermakna sistem AI boleh dikemas kini dengan mengemas kini sumber pengetahuan mereka berbanding melatih semula model mereka. Ia bermakna respons boleh memetik sumbernya, menjadikan pengesahan mudah. Dan ia bermakna organisasi boleh membina sistem AI dengan akses kepada pengetahuan dalaman yang benar-benar sensitif tanpa pengetahuan itu perlu dimasukkan dalam set data latihan.
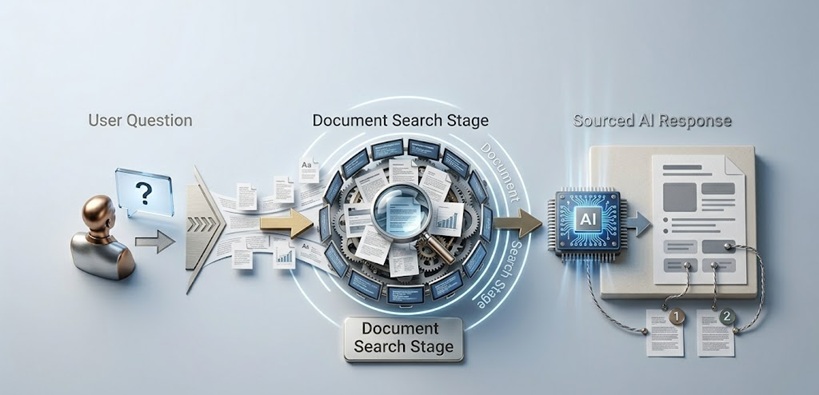
Bagaimana RAG AI Sebenarnya Berfungsi
Saluran Paip Retrieval Dijelaskan
Satu sistem RAG mempunyai dua komponen utama yang bekerja secara berurutan sebelum model bahasa pernah menjana satu perkataan responsnya.
Komponen pertama ialah pangkalan pengetahuan dan infrastruktur pengindeksannya. Dokumen, rekod, halaman web, entri pangkalan data atau apa-apa maklumat lain yang AI patut boleh menggunakan diproses dan disimpan dengan cara yang menjadikannya boleh dicari mengikut makna dan bukan sahaja mengikut kata kunci. Ini biasanya melibatkan penukaran teks kepada representasi berangka yang dipanggil embeddings, yang menangkap makna semantik dalam bentuk yang membolehkan kandungan yang serupa secara matematik untuk diperolehi bersama. Soalan tentang proses bayaran balik pelanggan mendapatkan kandungan tentang pemulangan, pertukaran dan jaminan kepuasan walaupun perkataan tepat tersebut tidak muncul dalam pertanyaan.
Komponen kedua ialah mekanisme retrieval yang diaktifkan apabila pengguna menghantar pertanyaan. Pertanyaan ditukar kepada format embedding yang sama seperti dokumen yang disimpan, dan sistem mengenal pasti kandungan disimpan yang paling serupa secara semantik dengan pertanyaan. Kandungan yang diperolehi tersebut, perenggan, dokumen atau rekod yang paling berkaitan dengan soalan yang ditanya, dikumpul dan diserahkan kepada model bahasa bersama dengan pertanyaan asal.
Model bahasa kemudian menjana respons berdasarkan konteks yang diperolehi tersebut dan bukan bergantung kepada data latihannya untuk fakta khusus yang diperlukan. Data latihan masih penting untuk keupayaan bahasa model, keupayaan penaakulannya dan pengetahuan dunia amnya. Tetapi kandungan fakta khusus respons datang dari bahan yang diperolehi.
| Komponen Sistem RAG | Apa Yang Ia Lakukan | Mengapa Ia Penting |
|---|---|---|
| Document Ingestion | Memproses dan membahagikan dokumen sumber untuk pengindeksan | Menentukan pengetahuan apa yang sistem boleh akses |
| Embedding Model | Menukar teks kepada representasi vektor semantik | Membolehkan retrieval berasaskan makna berbanding pemadanan kata kunci |
| Vector Database | Menyimpan embeddings untuk carian persamaan yang cepat | Menjadikan retrieval cukup pantas untuk kegunaan masa nyata |
| Mekanisme Retrieval | Mengenal pasti kandungan paling berkaitan untuk setiap pertanyaan | Menentukan ketepatan konteks yang diperolehi |
| Language Model | Menjana respons berdasarkan kandungan yang diperolehi | Menghasilkan output koheren dan disintesis dari fakta yang diperolehi |
| Atribusi Sumber | Menjejaki dokumen yang memaklumkan setiap respons | Membolehkan pengesahan dan membina kepercayaan pengguna |
Memahami bagaimana keputusan AI architecture dalam saluran paip RAG mempengaruhi kedua-dua kualiti retrieval dan ketepatan respons membantu organisasi membina sistem yang berfungsi dengan boleh dipercayai berbanding berfungsi dengan baik dalam demonstrasi dan tidak konsisten dalam pengeluaran.
RAG vs LLM Standard: Di Mana Perbezaannya Muncul Dalam Amalan
Perbezaan antara apa itu RAG AI dan apa yang LLM standard lakukan menjadi paling kelihatan dalam senario khusus di mana model standard gagal dan sistem RAG berjaya.
LLM standard yang ditanya tentang dasar pengekalan data semasa organisasi anda menjana respons berdasarkan amalan pengekalan data umum dari data latihannya. Ia mungkin kedengaran betul sepenuhnya. Ia hampir pasti tidak menggambarkan dasar sebenar anda. Sistem RAG yang ditanya soalan yang sama mendapatkan dokumen dasar sebenar anda dan menjana respons berdasarkan apa yang dokumen itu katakan. Bahasa adalah serupa. Ketepatan secara kategori berbeza.
LLM standard yang ditanya tentang aduan pelanggan yang dihantar semalam tidak tahu apa yang anda perkatakan. Aduan itu kemudian dari latihannya. Sistem RAG yang dihubungkan ke CRM anda mendapatkan rekod aduan dan menjana respons yang mencerminkan butiran sebenar situasi pelanggan tertentu tersebut.
LLM standard yang diminta meringkaskan penemuan utama dari laporan penyelidikan yang anda muat naik mungkin menghasilkan ringkasan yang kedengaran munasabah yang meninggalkan penemuan kritikal, salah menggambarkan kesimpulan atau menggabungkan butiran dari bahagian berbeza dokumen secara tidak tepat. Sistem RAG mendapatkan bahagian khusus yang paling berkaitan dengan permintaan ringkasan dan menjana output berdasarkan teks sebenar.
| Senario | Respons LLM Standard | Respons RAG AI |
|---|---|---|
| Soalan dasar dalaman | Menjana jawapan umum munasabah yang tidak khusus untuk dasar anda | Mendapatkan dokumen dasar sebenar, menjawab dari kandungannya |
| Soalan tentang peristiwa terkini | Menyatakan tiada maklumat atau menjana jawapan lapuk | Mendapatkan maklumat semasa dari pangkalan pengetahuan yang dihubungkan |
| Pertanyaan khusus pelanggan | Tidak boleh mengakses data pelanggan individu | Mendapatkan rekod pelanggan yang berkaitan dan memberi respons dengan tepat |
| Pertanyaan dokumentasi teknikal | Mungkin hallucinate butiran teknikal | Mendapatkan bahagian dokumentasi khusus dan memetiknya |
| Pengintipan persaingan | Terhad kepada data latihan, sering lapuk | Mendapatkan maklumat semasa dari sumber yang dihubungkan |
| Soalan pematuhan | Menjawab dari pengetahuan kawal selia umum | Mendapatkan peraturan yang berkaitan dan prosedur khusus organisasi |
Di Mana Perniagaan Menggunakan RAG AI Paling Berkesan
Pengurusan Pengetahuan Dalaman
Kes penggunaan pengurusan pengetahuan dalaman ialah di mana RAG AI menyampaikan sebahagian nilai perniagaannya yang paling jelas. Kebanyakan organisasi mempunyai pengetahuan institusi yang besar yang diedarkan merentas repositori dokumentasi, wiki, fail projek terdahulu, dokumen dasar dan komunikasi yang pekerja luangkan masa signifikan mencari secara manual. Satu sistem RAG di atas pangkalan pengetahuan tersebut mengubahnya menjadi sumber perbualan yang kakitangan boleh menanya dalam bahasa semula jadi dan menerima jawapan yang tepat dan bersumber dari.
Nilai kumulatif di sini adalah substantial. Pekerja berpengalaman yang memegang pengetahuan organisasi di kepala mereka akhirnya pergi. Dokumentasi yang wujud tetapi sukar dicari adalah secara fungsional hampir tidak boleh diakses seperti dokumentasi yang tidak wujud. Sistem RAG menjadikan pengetahuan organisasi boleh diakses oleh semua kakitangan tanpa mengira tempoh perkhidmatan, mengurangkan masa yang dihabiskan mencari maklumat dan mengeluarkan pengetahuan yang berkaitan dalam konteks di mana ia diperlukan berbanding meminta pekerja untuk tahu di mana untuk mencari.
Menyemak bagaimana AI features dalam platform RAG perusahaan mengendalikan kawalan akses pada kandungan yang diperolehi adalah penting untuk kes penggunaan ini kerana tidak semua pengetahuan organisasi patut sama-sama boleh diakses oleh semua pekerja. Sistem RAG yang dikonfigurasi dengan baik hanya mendapatkan kandungan yang pengguna yang menanya dibenarkan untuk mengakses, bukan segala-galanya dalam pangkalan pengetahuan.
Sokongan dan Perkhidmatan Berhadapan Pelanggan
Aplikasi perkhidmatan pelanggan dikuasai RAG mewakili salah satu penggunaan paling berimpak secara komersial bagi teknologi ini. AI perkhidmatan pelanggan disokong oleh saluran paip RAG di atas dokumentasi produk anda, panduan penyelesaian masalah, sistem pengurusan pesanan dan pangkalan data dasar boleh menjawab soalan khusus dan tepat tentang situasi sebenar pelanggan berbanding menjana respons umum yang menghantar pelanggan kepada ejen manusia untuk maklumat khusus yang mereka perlukan.
Kes perniagaan adalah jelas. Resolusi sentuhan pertama yang tepat mengurangkan kos sokongan, mengurangkan eskalasi kepada ejen manusia dan menghasilkan hasil pelanggan yang lebih baik. Asas teknikal yang menjadikan resolusi sentuhan pertama yang tepat mungkin untuk sistem AI hampir selalu RAG. Tanpa retrieval, model tidak boleh mengakses maklumat semasa khusus pelanggan yang respons sokongan yang tepat memerlukan.
Aplikasi Pematuhan dan Kawal Selia
Perkhidmatan kewangan, penjagaan kesihatan, undang-undang dan industri lain yang dikawal selia berat sedang menggunakan RAG AI di atas set dokumen kawal selia untuk membantu pasukan pematuhan menavigasi set peraturan yang kompleks dan kerap dikemas kini dengan lebih cekap. Pegawai pematuhan yang boleh menanya sistem RAG di atas teks penuh peraturan yang berkenaan, dokumen panduan dan rangka kerja dasar dalaman dan menerima jawapan tepat bersumber kepada soalan pematuhan khusus bekerja dengan lebih cekap dan lebih yakin daripada seseorang yang bergantung kepada ingatan atau semakan dokumen manual.
Keupayaan petikan sistem RAG amat berharga dalam konteks pematuhan. Jawapan yang memetik perenggan kawal selia khusus yang ia ambil dari adalah boleh disahkan dan boleh dipertahankan dengan cara yang jawapan dijana AI tanpa sumber tidak. Perbezaan itu penting secara mendalam apabila jawapan memaklumkan keputusan dengan akibat kawal selia.
Memahami bagaimana keperluan AI security dikenakan kepada sistem RAG yang dihubungkan kepada data kawal selia dan pematuhan sensitif membantu organisasi membina saluran paip retrieval yang mengekalkan kawalan akses yang sesuai merentas dokumen yang mereka indeks.

Membina Sistem RAG yang Benar-benar Berfungsi
Masalah Kualiti Data Yang Kebanyakan Projek Pandang Rendah
Sistem RAG hanya sebagus kandungan yang mereka peroleh dari. Organisasi yang tergesa-gesa melepasi penilaian kualiti data untuk sampai kepada bahagian menarik membina antara muka AI secara konsisten menemui bahawa kualiti retrieval menentukan kualiti respons jauh lebih daripada pilihan model bahasa. Dokumen sumber yang lemah, kandungan lapuk, maklumat yang diformat tidak konsisten dan pangkalan pengetahuan yang tidak diselenggara menghasilkan sistem RAG yang mendapatkan kandungan yang salah dan menjana respons yang berasaskan maklumat yang buruk berbanding tiada maklumat.
Implikasi praktikal ialah penyediaan pangkalan pengetahuan bukan langkah awalan untuk diselesaikan dengan cepat sebelum kerja sebenar bermula. Ia adalah bahagian teras projek yang menentukan sama ada sistem yang digunakan adalah berguna. Semakan kualiti dokumen, penilaian kekinian kandungan, deduplikasi versi yang bercanggah dan pemetaan kawalan akses semuanya perlu berlaku sebelum infrastruktur pengindeksan dibina.
Strategi Chunking Mempengaruhi Semua di Hiliran
Bagaimana dokumen sumber dibahagikan kepada unit yang boleh diperolehi sebelum pengindeksan mempunyai kesan yang lebih besar pada kualiti retrieval berbanding apa yang kebanyakan pasukan sedari apabila mereka mula membina sistem RAG. Chunks yang terlalu kecil kehilangan maklumat kontekstual yang menjadikan kandungan mereka bermakna. Chunks yang terlalu besar mendapatkan lebih daripada yang berkaitan dan mencairkan isyarat yang model bahasa gunakan untuk menjana respons yang tepat. Strategi chunking optimum bergantung pada jenis dokumen dalam pangkalan pengetahuan, sifat pertanyaan biasa dan tetingkap konteks model bahasa yang digunakan.
Menguji kualiti retrieval dengan pertanyaan perwakilan sebelum digunakan kepada pengguna mengeluarkan masalah chunking apabila ia masih boleh ditangani berbanding selepas pengguna mengalami kualiti respons yang tidak konsisten.
Satu AI guide komprehensif tentang metodologi pelaksanaan RAG membantu organisasi menstruktur proses pembinaan mereka di sekitar keputusan yang paling banyak mempengaruhi kualiti pengeluaran berbanding yang paling menarik secara teknikal semasa pembangunan.
Perkara Yang Perlu Diketahui
Beberapa realiti penting tentang RAG AI yang organisasi biasanya temui semasa atau selepas penggunaan pertama mereka:
Kualiti retrieval dan kualiti penjanaan adalah masalah berasingan yang memerlukan penilaian berasingan. Sistem RAG boleh mendapatkan kandungan yang betul dan menjana respons yang disintesis dengan teruk, atau mendapatkan kandungan yang salah dan menjana respons fasih yang kedengaran tepat tetapi tidak. Menguji kedua-dua komponen secara bebas sebelum menilai prestasi sistem hujung-ke-hujung mengenal pasti di mana masalah sebenarnya tinggal.
RAG tidak menghapuskan hallucination, ia mengurangkannya. Model bahasa yang menjana respons dari konteks yang diperolehi masih boleh menghasilkan kandungan yang tidak tepat dengan mentafsirkan bahan yang diperolehi dengan salah, menggabungkan maklumat secara tidak betul atau menjana butiran yang tidak hadir dalam konteks yang diperolehi. Risiko hallucination adalah secara substantial lebih rendah dengan retrieval yang baik berbanding tanpanya, tetapi semakan manusia kekal penting untuk aplikasi risiko tinggi.
Pilihan model embedding mempengaruhi kualiti retrieval dengan ketara. Model embedding berbeza memberi prestasi lebih baik pada jenis kandungan berbeza. Model yang dioptimumkan untuk retrieval teks umum mungkin memberi prestasi buruk pada dokumentasi teknikal, bahasa undang-undang atau terminologi khusus domain. Menguji kualiti retrieval dengan jenis dokumen sebenar anda dan corak pertanyaan sebelum komit kepada model embedding menghalang penyusunan semula seni bina yang mahal kemudian.
Penyelenggaraan pangkalan pengetahuan adalah fungsi operasi berterusan, bukan tugas persediaan sekali sahaja. Apabila dokumen sumber dikemas kini, kandungan baru ditambah dan kandungan lapuk menjadi mengelirukan, pangkalan pengetahuan RAG perlu dikemas kini secara sepadan. Organisasi yang menganggap pengindeksan awal sebagai penyelesaian kerja pangkalan pengetahuan berakhir dengan sistem yang ketepatannya merosot apabila jurang antara kandungan diindeks dan realiti semasa melebar.
Kawalan akses perlu dikuatkuasakan pada masa retrieval, bukan hanya pada penyerapan pangkalan pengetahuan. Pengguna yang tidak sepatutnya melihat dokumen tertentu tidak sepatutnya menerima respons yang berasaskan dokumen tersebut walaupun dokumen tersebut diindeks dalam sistem. Penguatkuasaan kebenaran masa retrieval adalah keperluan keselamatan, bukan peningkatan pilihan.
Peraturan 30% digunakan secara berguna untuk perancangan penggunaan RAG. Retrieval dan sintesis AI patut mengendalikan kira-kira 30% kerja pengetahuan, komponen pencarian dan sintesis, manakala kepakaran manusia mengendalikan penilaian, tafsiran dan pembuatan keputusan berkesan yang membentuk 70% baki. Mereka bentuk penggunaan RAG di sekitar keseimbangan ini mencipta sistem yang benar-benar menambah kerja pengetahuan manusia berbanding cuba menggantikan penilaian yang masih perlu tinggal dengan orang.
Mengapa RAG AI Menjadi Seni Bina Standard untuk AI Perniagaan
Apakah RAG AI dalam konteks lebih luas penerimaan AI perusahaan? Ia adalah corak seni bina yang menjadikan model bahasa berguna secara praktikal untuk tugas pengetahuan organisasi khusus dan semasa yang perniagaan sebenarnya perlukan AI untuk mengendalikan. Gabungan keupayaan model bahasa untuk berfikir, mensintesis dan berkomunikasi dalam bahasa semula jadi dengan akses sistem retrieval kepada maklumat semasa, khusus dan boleh disahkan menghasilkan sesuatu yang tiada komponen sampaikan secara berasingan.
Organisasi yang telah menggunakan model bahasa standard dan dikecewakan oleh hallucinations, pengetahuan lapuk dan ketidakupayaan untuk mengendalikan soalan khusus syarikat sering menggunakan teknologi yang betul dalam seni bina yang salah. Model yang sama, dihubungkan kepada saluran paip retrieval yang dibina dengan baik di atas pangkalan pengetahuan yang diselenggara dengan baik, menghasilkan keputusan yang sangat berbeza dan sangat lebih berguna.
Halangan teknikal untuk membina sistem RAG telah menurun dengan ketara dalam dua tahun yang lalu. Rangka kerja, vector database dan infrastruktur retrieval yang dihoskan yang menjadikan RAG praktikal adalah matang, didokumenkan dengan baik dan boleh diakses kepada pasukan kejuruteraan tanpa latar belakang penyelidikan AI khusus. Apa yang memisahkan penggunaan RAG yang berjaya dari yang mengecewakan adalah kurang tentang kecanggihan teknikal dan lebih tentang disiplin organisasi untuk menyediakan pangkalan pengetahuan dengan betul, menilai kualiti retrieval dengan ketat dan mengekalkan sistem sebagai aset operasi hidup berbanding projek yang siap.
Soalan Lazim
Apakah perbezaan antara GPT dan RAG?
GPT adalah satu jenis large language model yang menjana respons sepenuhnya berdasarkan corak yang dipelajari semasa latihan, manakala RAG adalah pendekatan seni bina yang menghubungkan mana-mana model bahasa, termasuk GPT, kepada sumber pengetahuan luaran yang diperolehi dan disertakan dalam konteks model pada masa respons. GPT tanpa retrieval menjawab dari data latihan sahaja, manakala sistem RAG berasaskan GPT mendapatkan maklumat semasa yang berkaitan sebelum menjana responsnya, menghasilkan jawapan yang berasaskan sumber khusus dan boleh disahkan berbanding generalisasi data latihan.
Apakah perbezaan antara RAG dan AI generatif?
AI generatif adalah kategori luas sistem AI yang menghasilkan kandungan baru termasuk teks, imej dan audio, manakala RAG adalah teknik khusus yang dikenakan kepada AI penjana teks yang menambah penjanaan dengan langkah retrieval menarik maklumat berkaitan dari sumber luaran sebelum model menjana responsnya. Semua sistem RAG adalah AI generatif, tetapi kebanyakan sistem AI generatif bukan sistem RAG. RAG adalah peningkatan seni bina yang menjadikan AI generatif lebih tepat dan semasa untuk tugas intensif pengetahuan.
Apakah RAG vs LLM?
LLM adalah model bahasa yang menjana teks berdasarkan data latihan, manakala RAG adalah seni bina yang memasangkan LLM dengan sistem retrieval supaya model menjana respons yang berasaskan dokumen yang diperolehi berbanding data latihan sahaja. LLM dalam sistem RAG mengendalikan pemahaman dan penjanaan bahasa manakala komponen retrieval mengendalikan mencari maklumat semasa dan khusus yang berkaitan dengan setiap pertanyaan. Bersama mereka menghasilkan output yang lebih tepat, boleh disahkan dan berkaitan secara organisasi berbanding mana-mana komponen menghasilkan secara bebas.
Apakah masalah yang RAG selesaikan?
RAG terutamanya menyelesaikan tiga masalah: batasan tarikh akhir latihan yang menjadikan LLM standard tidak boleh menjawab soalan tentang peristiwa terkini atau maklumat semasa, batasan skop yang menghalang model dari mengetahui tentang pengetahuan organisasi milik yang tidak pernah berada dalam data latihan awam dan masalah hallucination di mana model menjana respons munasabah tetapi tidak tepat apabila mereka kekurangan pengetahuan khusus yang soalan memerlukan. Dengan mendapatkan kandungan berkaitan sebelum menjana respons, RAG memasangkan output AI dalam sumber boleh disahkan berbanding corak statistik, menghasilkan jawapan yang boleh disemak, dipetik dan dipercayai untuk aplikasi kritikal perniagaan.
3 pekerjaan manakah yang akan terselamat dari AI?
Tiga kategori kerja yang paling tahan kepada penggantian AI adalah peranan yang memerlukan interaksi dunia fizikal dan ketangkasan dalam persekitaran tidak berstruktur, peranan yang berpusat pada pertimbangan manusia kompleks, penaakulan etika dan akauntabiliti untuk keputusan berkesan dan peranan yang dibina di sekitar kepercayaan antara perorangan, kecerdasan emosi dan pengurusan hubungan. RAG AI dan sistem serupa sedang menjadikan retrieval dan sintesis pengetahuan sangat boleh diautomasikan, yang menguatkan nilai keupayaan manusia yang jelas yang peranan-peranan ini bergantung berbanding tugas pemprosesan maklumat yang AI kini kendalikan dengan lebih cekap.