
Was ist RAG AI? Retrieval-Augmented Generation ist eine Technik, die ein Large Language Model im Moment der Antwortgenerierung mit einer externen Wissensquelle verbindet. So kann das Modell aktuelle, spezifische und überprüfbare Informationen heranziehen, anstatt sich ausschließlich auf das zu verlassen, was es während des Trainings gelernt hat. Das Ergebnis ist ein AI-System, das Fragen mit echten Daten beantwortet, statt mit verallgemeinerten Näherungen.
Wenn Sie jemals einen Standard-AI-Assistenten zu den internen Prozessen Ihres Unternehmens befragt und eine vernünftig klingende, aber komplett erfundene Antwort erhalten haben, dann haben Sie die zentrale Einschränkung erlebt, die RAG lösen soll. Sprachmodelle werden mit Daten bis zu einem festgelegten Zeitpunkt trainiert. Sie wissen nichts über Ihre proprietäre Dokumentation, Ihren aktuellen Lagerbestand, Ihre neuesten Richtlinien oder alles, was nach ihrem Trainings-Cutoff geschehen ist. RAG verändert diese grundlegende Einschränkung, indem es dem Modell einen Mechanismus gibt, vor der Antwort Informationen nachzuschlagen – so wie ein gut vorbereiteter Analyst Quelldokumente konsultiert, bevor er Ratschläge gibt, statt vollständig aus dem Gedächtnis zu arbeiten. Für Unternehmen, die AI in Kontexten einsetzen, in denen Genauigkeit und Spezifität zählen, ist das Verständnis, was RAG AI ist und wie es funktioniert, keine technische Nebensächlichkeit. Es ist der Unterschied zwischen einer AI, die wirklich hilft, und einer, die selbstbewusst plausiblen Unsinn produziert.

Warum Standard-Sprachmodelle ein grundsätzliches Wissensproblem haben
Die Einschränkung durch den Trainings-Cutoff
Jedes heute existierende Large Language Model wurde mit einem Datensatz trainiert, der ein festgelegtes Enddatum hat. Alles, was nach diesem Datum geschah – jede Richtlinienänderung, jedes Produktupdate, jede regulatorische Entwicklung, jedes Stück organisatorisches Wissen, das seit dem Training des Modells entstanden ist – ist für es unsichtbar. Für allgemeine Wissensaufgaben ist diese Einschränkung beherrschbar, weil sich Grundlagenwissen langsam ändert. Für Geschäftsanwendungen, bei denen es ausschließlich um Genauigkeit bei aktuellen, spezifischen Informationen geht, ist es ein ernstes operatives Problem.
Die zweite Einschränkung ist der Umfang. Selbst die größten Sprachmodelle, die mit den umfassendsten möglichen Datensätzen trainiert wurden, haben keine Kenntnis von Informationen, die nie in ihren Trainingsdaten waren. Die interne Wissensbasis Ihres Unternehmens, Ihre Kundenverträge, Ihre technische Dokumentation, Ihre Preisstrukturen und Ihre Betriebsabläufe waren mit ziemlicher Sicherheit nie in einem öffentlichen Trainingsdatensatz. Ein Modell, das Fragen zu diesen Themen beantwortet, ruft keine Informationen ab, die es kennt. Es generiert Text, der nach einer Antwort klingt, basierend auf Mustern in seinem Training – ein Prozess, der flüssige, selbstbewusste Antworten erzeugt, die möglicherweise keinerlei Bezug zu den tatsächlichen Fakten haben.
Dieses Phänomen hat einen Namen in der AI-Forschung: Halluzination. Es beschreibt die Tendenz von Sprachmodellen, faktisch falsche Informationen zu erzeugen, die im gleichen selbstbewussten Ton präsentiert werden wie korrekte Informationen. Für gelegentliche Anwendungsfälle ist Halluzination eine Unannehmlichkeit. Für Geschäftsanwendungen in juristischen, medizinischen, finanziellen oder operativen Kontexten ist es eine Haftungsfrage.
Wie RAG beide Probleme gleichzeitig adressiert
Was löst RAG AI konkret? Es adressiert sowohl das Cutoff-Problem als auch das Scope-Problem mit einer einzigen architektonischen Ergänzung. Anstatt das Modell zu bitten, allein aus Trainingsdaten zu antworten, rufen RAG-Systeme zur Abfragezeit relevante Dokumente oder Daten aus einer externen Quelle ab und beziehen diesen abgerufenen Inhalt in den Kontext ein, den das Modell zur Generierung seiner Antwort nutzt.
Das Modell rät nicht, was Ihre Rückerstattungsrichtlinie besagt. Es hat das tatsächliche Richtliniendokument vor der Antwort abgerufen. Es schätzt nicht, wie hoch Ihre Q3-Umsätze waren. Es hat die tatsächlichen Zahlen aus Ihrem Finanzsystem abgerufen, bevor es antwortete. Die Rolle des Modells verschiebt sich von der alleinigen Wissensquelle zum intelligenten Synthetisierer abgerufener Informationen – eine Aufgabe, die Sprachmodelle außerordentlich gut beherrschen.
Diese architektonische Verschiebung hat Implikationen, die weit über die Behebung von Halluzinationen hinausgehen. Sie bedeutet, dass AI-Systeme aktualisiert werden können, indem ihre Wissensquellen aktualisiert werden, statt ihre Modelle neu zu trainieren. Sie bedeutet, dass Antworten ihre Quellen zitieren können, was die Überprüfung unkompliziert macht. Und sie bedeutet, dass Organisationen AI-Systeme mit Zugriff auf wirklich sensibles internes Wissen bauen können, ohne dass dieses Wissen je in einen Trainingsdatensatz aufgenommen werden muss.
Wie RAG AI tatsächlich funktioniert
Die Retrieval-Pipeline erklärt
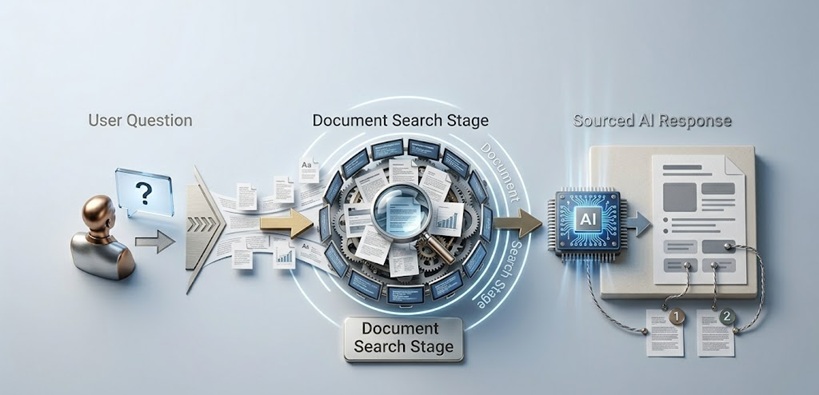
Ein RAG-System hat zwei Hauptkomponenten, die in Folge arbeiten, bevor das Sprachmodell auch nur ein Wort seiner Antwort generiert.
Die erste Komponente ist die Wissensbasis und ihre Indizierungsinfrastruktur. Dokumente, Datensätze, Webseiten, Datenbankeinträge oder jegliche anderen Informationen, auf die die AI zurückgreifen können soll, werden verarbeitet und so gespeichert, dass sie nach Bedeutung und nicht nur nach Schlüsselwörtern durchsuchbar sind. Dies beinhaltet typischerweise die Umwandlung von Text in numerische Darstellungen, sogenannte Embeddings, die semantische Bedeutung in einer Form erfassen, die das gemeinsame Abrufen mathematisch ähnlicher Inhalte ermöglicht. Eine Frage zu Kundenrückerstattungsprozessen ruft Inhalte zu Rücksendungen, Umtausch und Zufriedenheitsgarantien ab, selbst wenn diese genauen Wörter nicht in der Abfrage erscheinen.
Die zweite Komponente ist der Retrieval-Mechanismus, der aktiviert wird, wenn ein Benutzer eine Abfrage sendet. Die Abfrage wird in dasselbe Embedding-Format wie die gespeicherten Dokumente umgewandelt, und das System identifiziert die gespeicherten Inhalte, die der Abfrage semantisch am ähnlichsten sind. Dieser abgerufene Inhalt – die Passagen, Dokumente oder Datensätze, die für die gestellte Frage am relevantesten sind – wird zusammengestellt und zusammen mit der ursprünglichen Abfrage an das Sprachmodell übergeben.
Das Sprachmodell generiert dann eine Antwort, die in diesem abgerufenen Kontext verankert ist, statt sich für die spezifischen erforderlichen Fakten auf seine Trainingsdaten zu verlassen. Die Trainingsdaten sind weiterhin wichtig für die Sprachfähigkeit des Modells, seine Denkfähigkeit und sein allgemeines Weltwissen. Aber der spezifische inhaltliche Faktenbestand der Antwort kommt aus dem abgerufenen Material.
| RAG-Systemkomponente | Was sie tut | Warum sie wichtig ist |
|---|---|---|
| Document Ingestion | Verarbeitet und zerteilt Quelldokumente für die Indizierung | Bestimmt, auf welches Wissen das System zugreifen kann |
| Embedding Model | Wandelt Text in semantische Vektordarstellungen um | Ermöglicht bedeutungsbasiertes Retrieval statt Keyword-Matching |
| Vector Database | Speichert Embeddings für schnelle Ähnlichkeitssuche | Macht Retrieval schnell genug für Echtzeitnutzung |
| Retrieval-Mechanismus | Identifiziert den relevantesten Inhalt für jede Abfrage | Bestimmt die Genauigkeit des abgerufenen Kontexts |
| Language Model | Generiert Antworten basierend auf abgerufenen Inhalten | Erzeugt kohärente, synthetisierte Ausgaben aus abgerufenen Fakten |
| Quellenangabe | Verfolgt, welche Dokumente jede Antwort beeinflusst haben | Ermöglicht Verifizierung und schafft Nutzervertrauen |
Zu verstehen, wie AI-Architektur-Entscheidungen in RAG-Pipelines sowohl Retrieval-Qualität als auch Antwortgenauigkeit beeinflussen, hilft Organisationen, Systeme zu bauen, die zuverlässig funktionieren – statt in Demonstrationen gut und in der Produktion inkonsistent.
RAG vs. Standard-LLM: Wo sich der Unterschied in der Praxis zeigt
Die Unterscheidung zwischen dem, was RAG AI ist, und dem, was ein Standard-LLM tut, wird in den spezifischen Szenarien am sichtbarsten, in denen Standardmodelle versagen und RAG-Systeme erfolgreich sind.
Ein Standard-LLM, das nach der aktuellen Datenaufbewahrungsrichtlinie Ihrer Organisation gefragt wird, generiert eine Antwort basierend auf gängigen Datenaufbewahrungspraktiken aus seinen Trainingsdaten. Sie mag genau richtig klingen. Sie beschreibt mit ziemlicher Sicherheit nicht Ihre tatsächliche Richtlinie. Ein RAG-System, dem dieselbe Frage gestellt wird, ruft Ihr tatsächliches Richtliniendokument ab und generiert eine Antwort, die im Inhalt dieses Dokuments verankert ist. Die Sprache ist ähnlich. Die Genauigkeit ist kategorisch anders.
Ein Standard-LLM, das nach einer gestern eingereichten Kundenbeschwerde gefragt wird, hat keine Ahnung, wovon Sie sprechen. Die Beschwerde liegt zeitlich nach seinem Training. Ein RAG-System, das mit Ihrem CRM verbunden ist, ruft den Beschwerdedatensatz ab und generiert eine Antwort, die die tatsächlichen Details der spezifischen Situation dieses Kunden widerspiegelt.
Ein Standard-LLM, das aufgefordert wird, die wichtigsten Erkenntnisse aus einem von Ihnen hochgeladenen Forschungsbericht zusammenzufassen, kann eine plausibel klingende Zusammenfassung produzieren, die kritische Erkenntnisse auslässt, Schlussfolgerungen falsch darstellt oder Details aus verschiedenen Teilen des Dokuments ungenau kombiniert. Ein RAG-System ruft die spezifischen Abschnitte ab, die für die Zusammenfassungsanforderung am relevantesten sind, und generiert Ausgaben, die im tatsächlichen Text verankert sind.
| Szenario | Antwort eines Standard-LLM | Antwort von RAG AI |
|---|---|---|
| Frage zu internen Richtlinien | Generiert plausible generische Antwort, nicht spezifisch für Ihre Richtlinien | Ruft tatsächliches Richtliniendokument ab, antwortet aus seinem Inhalt |
| Frage zu einem aktuellen Ereignis | Gibt an, keine Informationen zu haben, oder generiert veraltete Antwort | Ruft aktuelle Informationen aus verbundener Wissensbasis ab |
| Kundenspezifische Anfrage | Kann nicht auf individuelle Kundendaten zugreifen | Ruft relevante Kundendatensätze ab und antwortet präzise |
| Technische Dokumentationsabfrage | Kann technische Details halluzinieren | Ruft spezifische Dokumentationsabschnitte ab und zitiert sie |
| Wettbewerbsanalyse | Auf Trainingsdaten begrenzt, oft veraltet | Ruft aktuelle Informationen aus verbundenen Quellen ab |
| Compliance-Frage | Antwortet aus allgemeinem regulatorischem Wissen | Ruft anwendbare Regeln und organisationsspezifische Verfahren ab |
Wo Unternehmen RAG AI am effektivsten einsetzen
Internes Wissensmanagement
Der Anwendungsfall des internen Wissensmanagements ist dort, wo RAG AI einen der klarsten Geschäftsmehrwerte liefert. Die meisten Organisationen verfügen über umfangreiches institutionelles Wissen, das über Dokumentationsspeicher, Wikis, vergangene Projektdateien, Richtliniendokumente und Kommunikation verteilt ist, die Mitarbeiter manuell zeitaufwendig durchsuchen müssen. Ein RAG-System über dieser Wissensbasis verwandelt sie in eine konversationelle Ressource, die Mitarbeiter in natürlicher Sprache abfragen können und aus der sie präzise, mit Quellen versehene Antworten erhalten.
Der sich verstärkende Wert ist hier erheblich. Erfahrene Mitarbeiter, die organisatorisches Wissen im Kopf tragen, verlassen das Unternehmen irgendwann. Dokumentation, die existiert, aber schwer zu finden ist, ist funktional fast so unzugänglich wie Dokumentation, die nicht existiert. RAG-Systeme machen organisatorisches Wissen für alle Mitarbeiter unabhängig von der Betriebszugehörigkeit zugänglich, reduzieren die Zeit, die für die Informationssuche aufgewendet wird, und bringen relevantes Wissen in den Kontext zum Vorschein, in dem es benötigt wird, statt von Mitarbeitern zu verlangen, dass sie wissen, wo sie suchen müssen.
Zu prüfen, wie AI-Features in Enterprise-RAG-Plattformen die Zugriffskontrolle auf abgerufene Inhalte handhaben, ist für diesen Anwendungsfall entscheidend, denn nicht alles organisatorische Wissen sollte allen Mitarbeitern gleichermaßen zugänglich sein. Ein gut konfiguriertes RAG-System ruft nur die Inhalte ab, auf die der abfragende Nutzer zugreifen darf, nicht alles in der Wissensbasis.
Kundenorientierte Support- und Serviceanwendungen
RAG-gestützte Kundenservice-Anwendungen stellen eine der kommerziell wirkungsvollsten Bereitstellungen dieser Technologie dar. Eine Kundenservice-AI, die durch eine RAG-Pipeline über Ihre Produktdokumentation, Fehlerbehebungsleitfäden, Ihr Order-Management-System und Ihre Richtliniendatenbank unterstützt wird, kann spezifische, präzise Fragen zur tatsächlichen Situation eines Kunden beantworten – statt generische Antworten zu generieren, die Kunden für die spezifischen benötigten Informationen an menschliche Mitarbeiter weiterleiten.
Der Business Case ist eindeutig. Präzise Erstkontaktlösung reduziert Supportkosten, reduziert Eskalationen an menschliche Mitarbeiter und führt zu besseren Kundenergebnissen. Die technische Grundlage, die präzise Erstkontaktlösung für AI-Systeme möglich macht, ist fast immer RAG. Ohne Retrieval kann das Modell nicht auf die aktuellen, kundenspezifischen Informationen zugreifen, die präzise Support-Antworten erfordern.
Compliance- und Regulierungsanwendungen
Finanzdienstleister, Gesundheitswesen, Rechtsbranche und andere stark regulierte Industrien setzen RAG AI über regulatorischen Dokumentensätzen ein, um Compliance-Teams zu helfen, komplexe, häufig aktualisierte Regelwerke effizienter zu navigieren. Ein Compliance-Beauftragter, der ein RAG-System über den vollständigen Text anwendbarer Vorschriften, Leitliniendokumente und interner Richtlinienrahmen abfragen und präzise, mit Quellen versehene Antworten auf spezifische Compliance-Fragen erhalten kann, arbeitet effizienter und mit mehr Vertrauen als jemand, der sich auf das Gedächtnis oder manuelle Dokumentenprüfung verlässt.
Die Zitierfähigkeit von RAG-Systemen ist im Compliance-Kontext besonders wertvoll. Eine Antwort, die den spezifischen regulatorischen Absatz zitiert, aus dem sie schöpft, ist überprüfbar und verteidigbar in einer Weise, in der eine AI-generierte Antwort ohne Quellenangabe es nicht ist. Dieser Unterschied zählt enorm, wenn die Antwort eine Entscheidung mit regulatorischen Konsequenzen informiert.
Zu verstehen, wie AI-Sicherheits-Anforderungen auf RAG-Systeme angewendet werden, die mit sensiblen regulatorischen und Compliance-Daten verbunden sind, hilft Organisationen, Retrieval-Pipelines zu bauen, die angemessene Zugriffskontrollen über die von ihnen indizierten Dokumente hinweg aufrechterhalten.

Ein RAG-System bauen, das tatsächlich funktioniert
Das Datenqualitätsproblem, das die meisten Projekte unterschätzen
RAG-Systeme sind nur so gut wie der Inhalt, aus dem sie abrufen. Organisationen, die die Datenqualitätsbewertung überspringen, um zum aufregenden Teil des Aufbaus der AI-Schnittstelle zu gelangen, entdecken durchgängig, dass die Retrieval-Qualität die Antwortqualität weit mehr bestimmt als die Wahl des Sprachmodells. Schlechte Quelldokumente, veraltete Inhalte, inkonsistent formatierte Informationen und nicht gepflegte Wissensbasen produzieren RAG-Systeme, die die falschen Inhalte abrufen und Antworten generieren, die in schlechten Informationen statt in keinen Informationen verankert sind.
Die praktische Implikation ist, dass die Vorbereitung der Wissensbasis kein Vorbereitungsschritt ist, der schnell abgeschlossen wird, bevor die eigentliche Arbeit beginnt. Sie ist ein Kernbestandteil des Projekts, der bestimmt, ob das bereitgestellte System nützlich ist. Dokumentenqualitätsprüfung, Aktualitätsbewertung der Inhalte, Deduplizierung widersprüchlicher Versionen und Zugriffskontrollabbildung müssen alle stattfinden, bevor die Indizierungsinfrastruktur aufgebaut wird.
Chunking-Strategie beeinflusst alles Nachgelagerte
Wie Quelldokumente vor der Indizierung in abrufbare Einheiten unterteilt werden, hat einen größeren Effekt auf die Retrieval-Qualität, als die meisten Teams beim Aufbau von RAG-Systemen erkennen. Chunks, die zu klein sind, verlieren die Kontextinformationen, die ihren Inhalt bedeutungsvoll machen. Chunks, die zu groß sind, rufen mehr ab, als relevant ist, und verdünnen das Signal, das das Sprachmodell zur Generierung präziser Antworten nutzt. Die optimale Chunking-Strategie hängt von den Dokumenttypen in der Wissensbasis, der Art typischer Abfragen und dem Kontextfenster des verwendeten Sprachmodells ab.
Das Testen der Retrieval-Qualität mit repräsentativen Abfragen vor der Bereitstellung für Nutzer bringt Chunking-Probleme zum Vorschein, wenn sie noch behoben werden können – statt nachdem Nutzer inkonsistente Antwortqualität erlebt haben.
Ein umfassender AI-Leitfaden zur RAG-Implementierungsmethodik hilft Organisationen, ihren Bauprozess um die Entscheidungen herum zu strukturieren, die die Produktionsqualität am meisten beeinflussen, statt um diejenigen, die während der Entwicklung am technisch interessantesten sind.
Wichtige Erkenntnisse
Mehrere wichtige Realitäten über RAG AI, die Organisationen typischerweise während oder nach ihrer ersten Bereitstellung entdecken:
Retrieval-Qualität und Generierungsqualität sind separate Probleme, die separate Evaluierung erfordern. Ein RAG-System kann den richtigen Inhalt abrufen und eine schlecht synthetisierte Antwort generieren – oder den falschen Inhalt abrufen und eine flüssige Antwort generieren, die präzise klingt, es aber nicht ist. Das unabhängige Testen beider Komponenten vor der Bewertung der End-to-End-Systemleistung identifiziert, wo Probleme tatsächlich liegen.
RAG eliminiert Halluzination nicht, es reduziert sie. Ein Sprachmodell, das eine Antwort aus abgerufenem Kontext generiert, kann immer noch ungenaue Inhalte produzieren, indem es abgerufenes Material falsch interpretiert, Informationen falsch kombiniert oder Details generiert, die im abgerufenen Kontext nicht vorhanden sind. Das Halluzinationsrisiko ist mit gutem Retrieval erheblich geringer als ohne, aber menschliche Überprüfung bleibt für risikoreiche Anwendungen wichtig.
Die Wahl des Embedding-Modells beeinflusst die Retrieval-Qualität erheblich. Verschiedene Embedding-Modelle schneiden bei verschiedenen Inhaltstypen besser ab. Ein für allgemeines Text-Retrieval optimiertes Modell kann bei technischer Dokumentation, juristischer Sprache oder fachspezifischer Terminologie schlecht abschneiden. Das Testen der Retrieval-Qualität mit Ihren tatsächlichen Dokumenttypen und Abfragemustern, bevor Sie sich auf ein Embedding-Modell festlegen, verhindert teures späteres Umarchitekturieren.
Wissensbasispflege ist eine fortlaufende operative Funktion, keine einmalige Einrichtungsaufgabe. Da Quelldokumente aktualisiert werden, neue Inhalte hinzukommen und veraltete Inhalte irreführend werden, muss die RAG-Wissensbasis entsprechend aktualisiert werden. Organisationen, die die anfängliche Indizierung als Abschluss der Wissensbasisarbeit behandeln, enden mit Systemen, deren Genauigkeit abnimmt, je größer die Lücke zwischen indizierten Inhalten und der aktuellen Realität wird.
Zugriffskontrollen müssen zur Retrieval-Zeit durchgesetzt werden, nicht nur bei der Aufnahme in die Wissensbasis. Ein Nutzer, der bestimmte Dokumente nicht sehen sollte, sollte auch keine Antworten erhalten, die in diesen Dokumenten verankert sind, selbst wenn die Dokumente im System indiziert sind. Berechtigungsdurchsetzung zur Retrieval-Zeit ist eine Sicherheitsanforderung, keine optionale Erweiterung.
Die 30%-Regel lässt sich nützlich auf RAG-Bereitstellungsplanung anwenden. AI-Retrieval und -Synthese sollten etwa 30% der Wissensarbeit übernehmen – die Nachschlage- und Synthesekomponente –, während menschliche Expertise das Urteilsvermögen, die Interpretation und die folgenreiche Entscheidungsfindung übernimmt, die die verbleibenden 70% ausmachen. RAG-Bereitstellungen um dieses Gleichgewicht herum zu gestalten, schafft Systeme, die menschliche Wissensarbeit wirklich erweitern, statt das Urteilsvermögen ersetzen zu wollen, das weiterhin bei den Menschen bleiben muss.
Warum RAG AI zur Standardarchitektur für Business AI wird
Was ist RAG AI im breiteren Kontext der Enterprise-AI-Einführung? Es ist das architektonische Muster, das Sprachmodelle für die spezifischen, aktuellen, organisatorischen Wissensaufgaben praktisch nutzbar macht, die Unternehmen tatsächlich von AI bewältigen lassen wollen. Die Kombination aus der Fähigkeit eines Sprachmodells zu argumentieren, zu synthetisieren und in natürlicher Sprache zu kommunizieren mit dem Zugriff eines Retrieval-Systems auf aktuelle, spezifische, überprüfbare Informationen produziert etwas, das keine der Komponenten allein liefert.
Organisationen, die Standard-Sprachmodelle bereitgestellt haben und von Halluzinationen, veraltetem Wissen und der Unfähigkeit, unternehmensspezifische Fragen zu bewältigen, enttäuscht waren, setzen oft die richtige Technologie in der falschen Architektur ein. Dieselben Modelle, verbunden mit gut aufgebauten Retrieval-Pipelines über gut gepflegten Wissensbasen, produzieren drastisch unterschiedliche und drastisch nützlichere Ergebnisse.
Die technische Hürde beim Aufbau von RAG-Systemen ist in den letzten zwei Jahren erheblich gesunken. Die Frameworks, Vector Databases und gehostete Retrieval-Infrastruktur, die RAG praktikabel machen, sind ausgereift, gut dokumentiert und für Engineering-Teams ohne spezialisierten AI-Forschungshintergrund zugänglich. Was erfolgreiche RAG-Bereitstellungen von enttäuschenden trennt, ist weniger technische Raffinesse als vielmehr die organisatorische Disziplin, Wissensbasen ordentlich vorzubereiten, Retrieval-Qualität rigoros zu evaluieren und das System als lebendigen operativen Vermögenswert zu pflegen, statt als abgeschlossenes Projekt.
Häufig gestellte Fragen
Was ist der Unterschied zwischen GPT und RAG?
GPT ist eine Art Large Language Model, das Antworten ausschließlich basierend auf während des Trainings gelernten Mustern generiert, während RAG ein architektonischer Ansatz ist, der jedes Sprachmodell – einschließlich GPT – mit externen Wissensquellen verbindet, die zur Antwortzeit abgerufen und in den Modellkontext aufgenommen werden. GPT ohne Retrieval antwortet allein aus Trainingsdaten, während ein GPT-basiertes RAG-System relevante aktuelle Informationen abruft, bevor es seine Antwort generiert, und so Antworten produziert, die in spezifischen, überprüfbaren Quellen verankert sind statt in Trainingsdaten-Verallgemeinerungen.
Was ist der Unterschied zwischen RAG und generativer AI?
Generative AI ist die breite Kategorie von AI-Systemen, die neuen Inhalt produzieren, einschließlich Text, Bildern und Audio, während RAG eine spezifische Technik ist, die auf textgenerierende AI angewendet wird und die Generierung mit einem Retrieval-Schritt erweitert, der relevante Informationen aus externen Quellen abruft, bevor das Modell seine Antwort generiert. Alle RAG-Systeme sind generative AI, aber die meisten generativen AI-Systeme sind keine RAG-Systeme. RAG ist eine architektonische Erweiterung, die generative AI für wissensintensive Aufgaben präziser und aktueller macht.
Was ist RAG vs. LLM?
Ein LLM ist ein Sprachmodell, das Text basierend auf Trainingsdaten generiert, während RAG eine Architektur ist, die ein LLM mit einem Retrieval-System koppelt, sodass das Modell Antworten generiert, die in abgerufenen Dokumenten verankert sind, statt allein in Trainingsdaten. Das LLM in einem RAG-System übernimmt Sprachverständnis und -generierung, während die Retrieval-Komponente das Finden aktueller, spezifischer Informationen übernimmt, die für jede Abfrage relevant sind. Zusammen produzieren sie Ausgaben, die präziser, überprüfbarer und organisatorisch relevanter sind, als jede Komponente unabhängig produziert.
Welche Probleme löst RAG?
RAG löst primär drei Probleme: die Trainings-Cutoff-Einschränkung, die Standard-LLMs daran hindert, Fragen zu aktuellen Ereignissen oder aktuellen Informationen zu beantworten; die Scope-Einschränkung, die Modelle daran hindert, etwas über proprietäres organisatorisches Wissen zu wissen, das nie in öffentlichen Trainingsdaten war; und das Halluzinationsproblem, bei dem Modelle plausible, aber ungenaue Antworten generieren, wenn ihnen das spezifische Wissen fehlt, das eine Frage erfordert. Indem es vor der Generierung von Antworten relevante Inhalte abruft, verankert RAG AI-Ausgaben in überprüfbaren Quellen statt in statistischen Mustern und produziert Antworten, die für geschäftskritische Anwendungen geprüft, zitiert und vertraut werden können.
Welche 3 Jobs werden AI überleben?
Die drei Arbeitskategorien, die am widerstandsfähigsten gegen AI-Verdrängung sind, sind Rollen, die physische Welt-Interaktion und Geschicklichkeit in unstrukturierten Umgebungen erfordern; Rollen, die sich auf komplexes menschliches Urteilsvermögen, ethisches Denken und Verantwortlichkeit für folgenreiche Entscheidungen konzentrieren; und Rollen, die auf zwischenmenschlichem Vertrauen, emotionaler Intelligenz und Beziehungsmanagement basieren. RAG AI und ähnliche Systeme machen Wissensabruf und -synthese hochautomatisierbar, was den Wert der eindeutig menschlichen Fähigkeiten verstärkt, von denen diese Rollen abhängen, statt der Informationsverarbeitungsaufgaben, die AI nun effizienter bewältigt.