
Cos'è RAG AI? Retrieval-Augmented Generation è una tecnica che collega un large language model a una fonte di conoscenza esterna nel momento in cui genera una risposta, permettendo al modello di attingere a informazioni attuali, specifiche e verificabili anziché basarsi unicamente su ciò che ha appreso durante l'addestramento. Il risultato è un sistema AI che risponde alle domande con dati reali invece che con approssimazioni generalizzate.
Se Le è mai capitato di porre a un assistente AI standard una domanda sui processi interni della Sua azienda e di ricevere una risposta che suonava plausibile ma era completamente inventata, ha sperimentato in prima persona la limitazione fondamentale che RAG è stato progettato per risolvere. I modelli linguistici vengono addestrati su dati fino a un punto fisso nel tempo. Non sanno nulla della documentazione proprietaria, dell'inventario corrente, delle ultime policy aziendali o di qualsiasi cosa sia accaduta dopo il cutoff di addestramento. RAG cambia questa limitazione fondamentale fornendo al modello un meccanismo per cercare informazioni prima di rispondere, allo stesso modo in cui un analista ben preparato consulta documenti di riferimento prima di fornire un parere, anziché lavorare interamente a memoria. Per le aziende che impiegano l'AI in contesti dove accuratezza e specificità contano, capire cos'è RAG AI e come funziona non è un dettaglio tecnico. È la differenza tra un'AI che aiuta realmente e una che produce con sicurezza assurdità plausibili.

Perché i modelli linguistici standard hanno un problema di conoscenza fondamentale
La limitazione del cutoff di addestramento
Ogni large language model esistente oggi è stato addestrato su un dataset con una data di fine definita. Tutto ciò che è accaduto dopo quella data — ogni cambiamento di policy, ogni aggiornamento di prodotto, ogni sviluppo normativo, ogni elemento di conoscenza organizzativa creato dopo l'addestramento del modello — è invisibile a esso. Per i compiti di conoscenza generale questa limitazione è gestibile perché la conoscenza fondamentale cambia lentamente. Per le applicazioni aziendali in cui l'accuratezza su informazioni attuali e specifiche è l'intero obiettivo, è un grave problema operativo.
La seconda limitazione è l'ambito. Anche i più grandi modelli linguistici addestrati sui dataset più ampi possibili non hanno conoscenza di informazioni che non erano nei loro dati di addestramento. La base di conoscenza interna della Sua azienda, i contratti con i clienti, la documentazione tecnica, le strutture di prezzo e le procedure operative quasi certamente non sono mai stati in nessun dataset di addestramento pubblico. Un modello che risponde a domande su questi argomenti non sta recuperando informazioni che conosce. Sta generando testo che suona come una risposta basata su pattern nel suo addestramento, un processo che produce risposte fluide e sicure di sé che potrebbero non avere alcuna relazione con i fatti reali.
Questo fenomeno ha un nome nella ricerca sull'AI: hallucination. Descrive la tendenza dei modelli linguistici a generare informazioni factualmente errate presentate con lo stesso tono sicuro delle informazioni accurate. Per casi d'uso casuali, l'hallucination è un inconveniente. Per applicazioni aziendali in contesti legali, medici, finanziari o operativi, è una responsabilità.
Come RAG affronta entrambi i problemi contemporaneamente
Cosa risolve specificamente RAG AI? Affronta sia il problema del cutoff sia il problema dell'ambito con un'unica aggiunta architetturale. Invece di chiedere al modello di rispondere solo dai dati di addestramento, i sistemi RAG recuperano documenti o dati rilevanti da una fonte esterna al momento della query e includono quel contenuto recuperato nel contesto che il modello utilizza per generare la sua risposta.
Il modello non sta tirando a indovinare cosa dice la Sua policy di rimborso. Ha recuperato il documento di policy effettivo prima di rispondere. Non sta stimando i Suoi dati di fatturato del Q3. Ha estratto i numeri reali dal Suo sistema finanziario prima di rispondere. Il ruolo del modello passa da unica fonte di conoscenza a sintetizzatore intelligente di informazioni recuperate, un compito che i modelli linguistici svolgono straordinariamente bene.
Questo cambiamento architetturale ha implicazioni che vanno ben oltre la risoluzione delle hallucination. Significa che i sistemi AI possono essere aggiornati aggiornando le loro fonti di conoscenza anziché riaddestrando i loro modelli. Significa che le risposte possono citare le loro fonti, rendendo la verifica diretta. E significa che le organizzazioni possono costruire sistemi AI con accesso a conoscenze interne genuinamente sensibili senza che quella conoscenza debba mai essere inclusa in un dataset di addestramento.
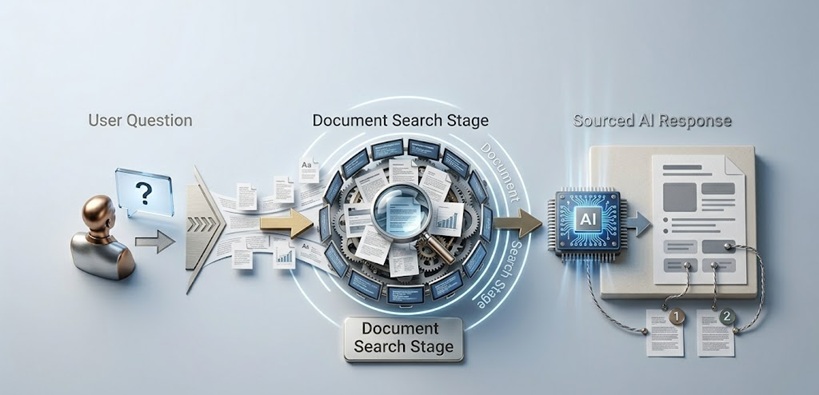
Come funziona davvero RAG AI
La pipeline di retrieval spiegata
Un sistema RAG ha due componenti principali che lavorano in sequenza prima che il modello linguistico generi anche solo una parola della sua risposta.
Il primo componente è la base di conoscenza e la sua infrastruttura di indicizzazione. Documenti, record, pagine web, voci di database o qualsiasi altra informazione a cui l'AI dovrebbe poter attingere vengono elaborati e archiviati in modo da essere ricercabili per significato anziché solo per parola chiave. Questo tipicamente implica la conversione del testo in rappresentazioni numeriche chiamate embeddings, che catturano il significato semantico in una forma che consente il recupero insieme di contenuti matematicamente simili. Una domanda sui processi di rimborso clienti recupera contenuti su resi, sostituzioni e garanzie di soddisfazione anche se quelle esatte parole non appaiono nella query.
Il secondo componente è il meccanismo di retrieval che si attiva quando un utente invia una query. La query viene convertita nello stesso formato embedding dei documenti archiviati, e il sistema identifica il contenuto archiviato semanticamente più simile alla query. Quel contenuto recuperato — i passaggi, documenti o record più pertinenti alla domanda posta — viene assemblato e passato al modello linguistico insieme alla query originale.
Il modello linguistico genera quindi una risposta ancorata in quel contesto recuperato anziché fare affidamento sui suoi dati di addestramento per i fatti specifici richiesti. I dati di addestramento contano ancora per le capacità linguistiche del modello, la sua capacità di ragionamento e la sua conoscenza generale del mondo. Ma il contenuto fattuale specifico della risposta proviene dal materiale recuperato.
| Componente del sistema RAG | Cosa fa | Perché è importante |
|---|---|---|
| Document Ingestion | Elabora e suddivide i documenti sorgente per l'indicizzazione | Determina a quale conoscenza il sistema può accedere |
| Embedding Model | Converte il testo in rappresentazioni vettoriali semantiche | Abilita il retrieval basato sul significato anziché sulla corrispondenza di parole chiave |
| Vector Database | Memorizza gli embeddings per una ricerca di similarità rapida | Rende il retrieval abbastanza veloce per l'uso in tempo reale |
| Meccanismo di Retrieval | Identifica il contenuto più pertinente per ogni query | Determina l'accuratezza del contesto recuperato |
| Language Model | Genera una risposta ancorata al contenuto recuperato | Produce output coerenti e sintetizzati dai fatti recuperati |
| Attribuzione della fonte | Traccia quali documenti hanno informato ogni risposta | Abilita la verifica e costruisce fiducia nell'utente |
Capire come le decisioni di AI architecture nelle pipeline RAG influenzino sia la qualità del retrieval sia l'accuratezza della risposta aiuta le organizzazioni a costruire sistemi che funzionano in modo affidabile anziché bene nelle demo e in modo incoerente in produzione.
RAG vs LLM standard: dove si vede la differenza in pratica
La distinzione tra cos'è RAG AI e cosa fa un LLM standard diventa più visibile negli scenari specifici in cui i modelli standard falliscono e i sistemi RAG hanno successo.
Un LLM standard interrogato sulla policy attuale di conservazione dei dati della Sua organizzazione genera una risposta basata sulle pratiche comuni di conservazione dei dati dai suoi dati di addestramento. Può suonare esattamente giusto. Quasi certamente non sta descrivendo la Sua policy effettiva. Un sistema RAG interrogato sulla stessa domanda recupera il Suo documento di policy reale e genera una risposta ancorata a ciò che il documento dice. Il linguaggio è simile. L'accuratezza è categoricamente diversa.
Un LLM standard interrogato su un reclamo del cliente inviato ieri non ha idea di cosa stia parlando. Il reclamo è successivo al suo addestramento. Un sistema RAG collegato al Suo CRM recupera il record del reclamo e genera una risposta che riflette i dettagli effettivi della situazione specifica di quel cliente.
Un LLM standard a cui viene chiesto di riassumere i risultati chiave di un report di ricerca che ha caricato può produrre un riassunto dal suono plausibile che omette risultati critici, distorce le conclusioni o combina dettagli da diverse parti del documento in modo inaccurato. Un sistema RAG recupera le sezioni specifiche più pertinenti alla richiesta di riassunto e genera output ancorati al testo effettivo.
| Scenario | Risposta di LLM standard | Risposta di RAG AI |
|---|---|---|
| Domanda su policy interna | Genera una risposta generica plausibile non specifica delle Sue policy | Recupera il documento di policy effettivo, risponde dal suo contenuto |
| Domanda su evento recente | Dichiara di non avere informazioni o genera una risposta obsoleta | Recupera informazioni attuali dalla base di conoscenza collegata |
| Richiesta specifica di cliente | Non può accedere ai dati del singolo cliente | Recupera record cliente pertinenti e risponde accuratamente |
| Query di documentazione tecnica | Può hallucinare dettagli tecnici | Recupera sezioni di documentazione specifiche e le cita |
| Intelligence competitiva | Limitata ai dati di addestramento, spesso obsoleta | Recupera informazioni attuali da fonti collegate |
| Domanda di conformità | Risponde dalla conoscenza normativa generale | Recupera regole applicabili e procedure specifiche dell'organizzazione |
Dove le aziende stanno implementando RAG AI più efficacemente
Gestione della conoscenza interna
Il caso d'uso della gestione della conoscenza interna è dove RAG AI offre alcuni dei suoi valori aziendali più chiari. La maggior parte delle organizzazioni ha una considerevole conoscenza istituzionale distribuita tra repository di documentazione, wiki, file di progetti passati, documenti di policy e comunicazioni in cui i dipendenti spendono tempo significativo cercando manualmente. Un sistema RAG su quella base di conoscenza la trasforma in una risorsa conversazionale che il personale può interrogare in linguaggio naturale e da cui ricevere risposte accurate e con fonti citate.
Il valore cumulativo qui è sostanziale. I dipendenti esperti che custodiscono la conoscenza organizzativa nella loro testa alla fine se ne vanno. La documentazione che esiste ma è difficile da trovare è funzionalmente quasi inaccessibile quanto la documentazione che non esiste. I sistemi RAG rendono la conoscenza organizzativa accessibile a tutto il personale indipendentemente dall'anzianità, riducono il tempo speso a cercare informazioni e fanno emergere conoscenza pertinente nel contesto in cui è necessaria anziché richiedere ai dipendenti di sapere dove cercare.
Esaminare come le AI features nelle piattaforme RAG enterprise gestiscano il controllo degli accessi sul contenuto recuperato è essenziale per questo caso d'uso perché non tutta la conoscenza organizzativa dovrebbe essere ugualmente accessibile a tutti i dipendenti. Un sistema RAG ben configurato recupera solo il contenuto a cui l'utente che effettua la query è autorizzato ad accedere, non tutto ciò che è nella base di conoscenza.
Supporto e servizio rivolto al cliente
Le applicazioni di servizio clienti basate su RAG rappresentano una delle implementazioni commercialmente più impattanti di questa tecnologia. Un'AI di servizio clienti supportata da una pipeline RAG sulla Sua documentazione di prodotto, guide alla risoluzione dei problemi, sistema di gestione degli ordini e database di policy può rispondere a domande specifiche e accurate sulla situazione reale di un cliente anziché generare risposte generiche che indirizzano i clienti ad agenti umani per le informazioni specifiche di cui avevano bisogno.
Il business case è semplice. La risoluzione accurata al primo contatto riduce i costi di supporto, riduce le escalation agli agenti umani e produce migliori risultati per il cliente. La base tecnica che rende possibile la risoluzione accurata al primo contatto per i sistemi AI è quasi sempre RAG. Senza retrieval, il modello non può accedere alle informazioni attuali specifiche del cliente che le risposte di supporto accurate richiedono.
Applicazioni di conformità e normative
Servizi finanziari, sanità, settore legale e altre industrie fortemente regolamentate stanno implementando RAG AI su set di documenti normativi per aiutare i team di conformità a navigare insiemi complessi e frequentemente aggiornati di regole in modo più efficiente. Un responsabile della conformità che può interrogare un sistema RAG sull'intero testo delle normative applicabili, documenti di orientamento e framework di policy interna e ricevere risposte accurate e con fonti citate a domande specifiche di conformità lavora in modo più efficiente e con maggiore sicurezza rispetto a chi si affida alla memoria o alla revisione manuale dei documenti.
La capacità di citazione dei sistemi RAG è particolarmente preziosa in contesti di conformità. Una risposta che cita lo specifico paragrafo normativo da cui trae è verificabile e difendibile in un modo in cui una risposta generata dall'AI senza fonte non lo è. Quella differenza conta enormemente quando la risposta informa una decisione con conseguenze normative.
Comprendere come i requisiti di AI security si applichino ai sistemi RAG collegati a dati normativi e di conformità sensibili aiuta le organizzazioni a costruire pipeline di retrieval che mantengono controlli di accesso appropriati sui documenti che indicizzano.

Costruire un sistema RAG che funzioni davvero
Il problema della qualità dei dati che la maggior parte dei progetti sottovaluta
I sistemi RAG sono buoni solo quanto il contenuto da cui recuperano. Le organizzazioni che si affrettano oltre la valutazione della qualità dei dati per arrivare alla parte eccitante della costruzione dell'interfaccia AI scoprono coerentemente che la qualità del retrieval determina la qualità della risposta molto più di quanto faccia la scelta del modello linguistico. Documenti sorgente di scarsa qualità, contenuti obsoleti, informazioni con formattazione incoerente e basi di conoscenza non mantenute producono sistemi RAG che recuperano il contenuto sbagliato e generano risposte ancorate a cattive informazioni anziché a nessuna informazione.
L'implicazione pratica è che la preparazione della base di conoscenza non è un passo preliminare da completare rapidamente prima che inizi il vero lavoro. È una parte centrale del progetto che determina se il sistema implementato è utile. Revisione della qualità dei documenti, valutazione dell'attualità del contenuto, deduplicazione delle versioni in conflitto e mappatura del controllo degli accessi devono avvenire tutti prima che venga costruita l'infrastruttura di indicizzazione.
La strategia di Chunking influenza tutto a valle
Come i documenti sorgente vengono divisi in unità recuperabili prima dell'indicizzazione ha un effetto sulla qualità del retrieval più grande di quanto la maggior parte dei team si renda conto quando inizia a costruire sistemi RAG. I chunk troppo piccoli perdono le informazioni contestuali che rendono significativo il loro contenuto. I chunk troppo grandi recuperano più di quanto sia pertinente e diluiscono il segnale che il modello linguistico utilizza per generare risposte accurate. La strategia di chunking ottimale dipende dai tipi di documento nella base di conoscenza, dalla natura delle query tipiche e dalla finestra di contesto del modello linguistico utilizzato.
Testare la qualità del retrieval con query rappresentative prima del deployment agli utenti fa emergere problemi di chunking quando possono ancora essere affrontati anziché dopo che gli utenti hanno sperimentato qualità di risposta incoerente.
Una AI guide completa sulla metodologia di implementazione RAG aiuta le organizzazioni a strutturare il loro processo di costruzione intorno alle decisioni che influenzano maggiormente la qualità in produzione anziché quelle più tecnicamente interessanti durante lo sviluppo.
Cose da sapere
Diverse realtà importanti su RAG AI che le organizzazioni tipicamente scoprono durante o dopo il loro primo deployment:
La qualità del retrieval e la qualità della generazione sono problemi separati che richiedono valutazioni separate. Un sistema RAG può recuperare il contenuto giusto e generare una risposta mal sintetizzata, oppure recuperare il contenuto sbagliato e generare una risposta fluida che suona accurata ma non lo è. Testare entrambi i componenti indipendentemente prima di valutare le prestazioni end-to-end del sistema identifica dove i problemi vivono realmente.
RAG non elimina l'hallucination, la riduce. Un modello linguistico che genera una risposta da contesto recuperato può comunque produrre contenuto inaccurato interpretando erroneamente il materiale recuperato, combinando informazioni in modo errato o generando dettagli non presenti nel contesto recuperato. Il rischio di hallucination è sostanzialmente più basso con un buon retrieval che senza, ma la revisione umana rimane importante per applicazioni ad alto rischio.
La scelta del modello embedding influisce significativamente sulla qualità del retrieval. Diversi modelli embedding si comportano meglio su diversi tipi di contenuto. Un modello ottimizzato per il retrieval di testo generale può funzionare male su documentazione tecnica, linguaggio legale o terminologia specifica del dominio. Testare la qualità del retrieval con i Suoi tipi di documento effettivi e pattern di query prima di impegnarsi con un modello embedding previene costose riarchitetture successive.
La manutenzione della base di conoscenza è una funzione operativa continua, non un compito di configurazione una tantum. Man mano che i documenti sorgente vengono aggiornati, si aggiungono nuovi contenuti e i contenuti obsoleti diventano fuorvianti, la base di conoscenza RAG deve essere aggiornata di conseguenza. Le organizzazioni che trattano l'indicizzazione iniziale come il completamento del lavoro della base di conoscenza finiscono con sistemi la cui accuratezza si degrada man mano che il divario tra contenuto indicizzato e realtà attuale si allarga.
I controlli di accesso devono essere applicati al momento del retrieval, non solo all'ingestione della base di conoscenza. Un utente che non dovrebbe vedere certi documenti non dovrebbe ricevere risposte ancorate a quei documenti anche se i documenti sono indicizzati nel sistema. L'applicazione dei permessi al momento del retrieval è un requisito di sicurezza, non un miglioramento opzionale.
La regola del 30% si applica utilmente alla pianificazione del deployment RAG. Il retrieval e la sintesi AI dovrebbero gestire circa il 30% del lavoro di conoscenza, la componente di ricerca e sintesi, mentre l'esperienza umana gestisce il giudizio, l'interpretazione e il processo decisionale conseguente che costituiscono il restante 70%. Progettare deployment RAG attorno a questo equilibrio crea sistemi che aumentano genuinamente il lavoro di conoscenza umano anziché tentare di sostituire il giudizio che deve ancora rimanere alle persone.
Perché RAG AI sta diventando l'architettura standard per l'AI aziendale
Cos'è RAG AI nel contesto più ampio dell'adozione dell'AI enterprise? È il pattern architetturale che rende i modelli linguistici praticamente utili per i compiti specifici, attuali, di conoscenza organizzativa che le aziende hanno effettivamente bisogno che l'AI gestisca. La combinazione della capacità di un modello linguistico di ragionare, sintetizzare e comunicare in linguaggio naturale con l'accesso di un sistema di retrieval a informazioni attuali, specifiche, verificabili produce qualcosa che nessuno dei due componenti offre da solo.
Le organizzazioni che hanno implementato modelli linguistici standard e sono state deluse da hallucination, conoscenza obsoleta e incapacità di gestire domande specifiche dell'azienda stanno spesso implementando la tecnologia giusta nell'architettura sbagliata. Gli stessi modelli, collegati a pipeline di retrieval ben costruite su basi di conoscenza ben mantenute, producono risultati drasticamente diversi e drasticamente più utili.
La barriera tecnica per costruire sistemi RAG è scesa significativamente negli ultimi due anni. I framework, vector database e infrastruttura di retrieval ospitata che rendono RAG praticabile sono maturi, ben documentati e accessibili a team di engineering senza background di ricerca AI specializzati. Ciò che separa i deployment RAG di successo da quelli deludenti è meno la sofisticazione tecnica e più la disciplina organizzativa per preparare adeguatamente le basi di conoscenza, valutare rigorosamente la qualità del retrieval e mantenere il sistema come un asset operativo vivente anziché un progetto completato.
Domande frequenti
Qual è la differenza tra GPT e RAG?
GPT è un tipo di large language model che genera risposte interamente basate su pattern appresi durante l'addestramento, mentre RAG è un approccio architetturale che collega qualsiasi modello linguistico, compreso GPT, a fonti di conoscenza esterne che vengono recuperate e incluse nel contesto del modello al momento della risposta. GPT senza retrieval risponde solo dai dati di addestramento, mentre un sistema RAG basato su GPT recupera informazioni attuali rilevanti prima di generare la sua risposta, producendo risposte ancorate a fonti specifiche e verificabili anziché a generalizzazioni dei dati di addestramento.
Qual è la differenza tra RAG e AI generativa?
L'AI generativa è la categoria ampia di sistemi AI che producono nuovi contenuti tra cui testo, immagini e audio, mentre RAG è una tecnica specifica applicata all'AI che genera testo che aumenta la generazione con un passaggio di retrieval che estrae informazioni rilevanti da fonti esterne prima che il modello generi la sua risposta. Tutti i sistemi RAG sono AI generativa, ma la maggior parte dei sistemi di AI generativa non sono sistemi RAG. RAG è un miglioramento architetturale che rende l'AI generativa più accurata e attuale per compiti ad alta intensità di conoscenza.
Cos'è RAG vs LLM?
Un LLM è un modello linguistico che genera testo basato sui dati di addestramento, mentre RAG è un'architettura che accoppia un LLM con un sistema di retrieval in modo che il modello generi risposte ancorate a documenti recuperati anziché solo ai dati di addestramento. L'LLM in un sistema RAG gestisce la comprensione e la generazione del linguaggio mentre il componente di retrieval gestisce la ricerca di informazioni attuali e specifiche pertinenti a ciascuna query. Insieme producono output più accurati, verificabili e rilevanti per l'organizzazione di quanto ciascun componente produca indipendentemente.
Quali problemi risolve RAG?
RAG risolve principalmente tre problemi: la limitazione del cutoff di addestramento che rende gli LLM standard incapaci di rispondere a domande su eventi recenti o informazioni attuali, la limitazione dell'ambito che impedisce ai modelli di conoscere la conoscenza organizzativa proprietaria che non era mai stata nei dati di addestramento pubblici, e il problema dell'hallucination dove i modelli generano risposte plausibili ma inaccurate quando mancano della conoscenza specifica che una domanda richiede. Recuperando contenuti rilevanti prima di generare risposte, RAG ancora gli output AI a fonti verificabili anziché a pattern statistici, producendo risposte che possono essere verificate, citate e affidabili per applicazioni business-critical.
Quali 3 lavori sopravviveranno all'AI?
Le tre categorie di lavoro più resistenti alla sostituzione da parte dell'AI sono ruoli che richiedono interazione con il mondo fisico e destrezza in ambienti non strutturati, ruoli incentrati sul complesso giudizio umano, ragionamento etico e responsabilità per decisioni conseguenti, e ruoli costruiti attorno alla fiducia interpersonale, intelligenza emotiva e gestione delle relazioni. RAG AI e sistemi simili stanno rendendo il recupero e la sintesi della conoscenza altamente automatizzabili, il che rafforza il valore delle capacità distintamente umane da cui dipendono questi ruoli anziché i compiti di elaborazione delle informazioni che l'AI ora gestisce in modo più efficiente.