
L'AI on-premise per le aziende consiste nel distribuire sistemi di intelligenza artificiale direttamente su hardware di proprietà aziendale o su server privati, anziché accedervi tramite un fornitore cloud. Conferisce alle organizzazioni autorità completa sui propri dati, sul comportamento dell'AI e su ciò a cui si connette.
La maggior parte delle conversazioni sull'AI per le aziende si concentra su quale strumento cloud sottoscrivere successivamente. Questa impostazione tralascia un aspetto importante. Per un numero crescente di organizzazioni, la vera domanda non è a quale piattaforma abbonarsi, ma se internalizzare l'intero stack. La risposta dipende dal Suo settore, dalla sensibilità dei Suoi dati, dalla capacità tecnica del Suo team e dalle Sue aspettative di costo a lungo termine. Questa guida affronta tutti questi aspetti per permetterLe di prendere una decisione informata anziché reattiva.

Cosa significa realmente AI on-premise per le aziende
L'espressione suona tecnica, ma il concetto è semplice. Quando utilizza un servizio come Microsoft Azure OpenAI o Google Vertex AI, i Suoi dati viaggiano verso server esterni, vengono elaborati e tornano indietro. Il fornitore gestisce l'infrastruttura, gli aggiornamenti dei modelli e la sicurezza dalla propria parte della pipeline.
L'on-premise ribalta completamente questo modello. L'AI viene eseguita su server di proprietà esclusiva della Sua azienda o in leasing esclusivo, che si tratti di un rack nel Suo ufficio, di una struttura di colocation o di un ambiente cloud privato a cui nessuna terza parte può accedere. I Suoi dati non lasciano mai il perimetro che Lei definisce.
Questo è enormemente rilevante per i settori in cui la gestione dei dati è regolamentata. Un ospedale che utilizza un sistema AI on-premise per analizzare le cartelle cliniche dei pazienti non deve preoccuparsi se gli accordi di trattamento dati del fornitore rispettano le normative sanitarie. Uno studio legale che esegue l'analisi dei contratti in locale non deve comunicare ai clienti che i loro documenti sono passati attraverso un server di terze parti. I dati restano semplicemente dove devono stare.
Per le aziende al di fuori dei settori regolamentati, l'attrattiva è comunque concreta. Intelligence competitiva, dati finanziari interni, modelli comportamentali dei clienti e roadmap di sviluppo prodotto sono tutti elementi che le aziende preferiscono ragionevolmente mantenere all'interno delle proprie mura.
Perché sempre più aziende si stanno muovendo in questa direzione

L'argomento del controllo dei dati
I fornitori di AI cloud sono affidabili, ma non sono invisibili. Quando invia dati a un modello di terze parti, accetta i loro termini di servizio, la loro postura di sicurezza e le loro decisioni di policy su ciò che viene registrato, conservato o utilizzato per il miglioramento dei modelli. La maggior parte degli accordi enterprise include opzioni di opt-out per i dati di addestramento, ma la dipendenza sottostante dall'infrastruttura di qualcun altro rimane.
L'implementazione on-premise elimina questa dipendenza. Il Suo team di sicurezza stabilisce le regole. La Sua infrastruttura IT gestisce i controlli di accesso. I Suoi responsabili della conformità possono auditare l'intera pipeline senza attendere la collaborazione di un fornitore. Per le organizzazioni che hanno subito violazioni dei dati attraverso servizi di terze parti, quel livello di controllo diretto non è un lusso, è un requisito.
Prevedibilità dei costi a lungo termine
I prezzi dell'AI cloud sono attrattivi su piccola scala, ma diventano imprevedibili man mano che l'utilizzo cresce. Un team che esegue centinaia di migliaia di chiamate di inferenza al mese inizia a sentire il peso dei costi per token accumularsi in modi che non erano evidenti durante la fase pilota. L'hardware è costoso inizialmente, ma non Le invia una fattura ogni volta che un dipendente pone una domanda all'AI.
Per le aziende con un utilizzo AI costante e ad alto volume, il punto di pareggio tra i costi cloud e l'investimento in infrastruttura on-premise si colloca spesso entro due o tre anni. Dopodiché, l'installazione on-premise è di fatto gratuita da gestire al netto di manutenzione ed elettricità.
Comprendere come le funzionalità AI si mappano sui requisiti hardware aiuta i team a pianificare quell'investimento con precisione prima di impegnarsi negli acquisti infrastrutturali.
Personalizzazione senza limiti
Gli strumenti AI cloud Le offrono opzioni di configurazione entro un confine definito. L'on-premise Le fornisce i pesi effettivi del modello e l'intero stack da modificare secondo necessità. Ciò significa poter fare fine-tuning dei modelli sui Suoi dati proprietari, regolare il comportamento del sistema a ogni livello, integrarsi profondamente con database e strumenti interni e versionare l'intero ambiente AI nello stesso modo in cui gestisce qualsiasi altro software interno.
Un'azienda retail, ad esempio, può effettuare il fine-tuning di un language model sul proprio catalogo prodotti specifico e sulla cronologia del servizio clienti in modo che parli con precisione del proprio inventario anziché produrre risposte generiche. Quel livello di personalizzazione semplicemente non è disponibile tramite una API cloud standard.
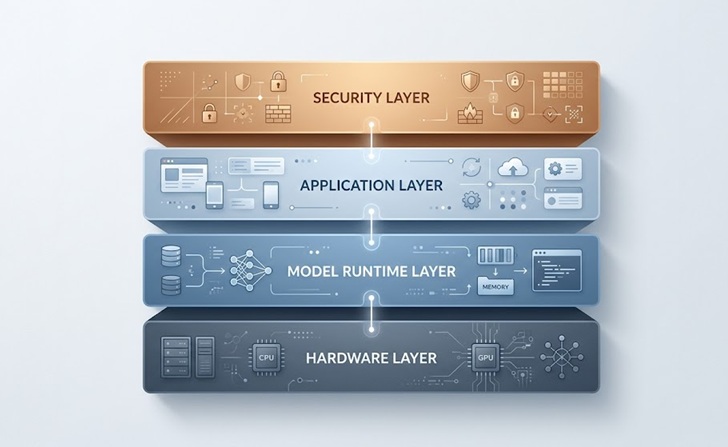
Come sono tipicamente strutturate le implementazioni AI on-premise
L'architettura di base
La maggior parte delle configurazioni AI on-premise per le aziende condivide un modello comune indipendentemente dagli strumenti specifici coinvolti.
La base è il livello hardware, che include i server, le GPU e le apparecchiature di rete che eseguono il modello. Al di sopra si trova il runtime del modello, tipicamente uno strumento di orchestrazione che gestisce il caricamento dei modelli in memoria, gestisce le richieste ed espone un endpoint API che altre applicazioni interne possono chiamare.
Il livello applicativo è dove risiedono gli effettivi strumenti aziendali, che si tratti di un chatbot di assistenza clienti, un assistente per la knowledge base interna, una pipeline di elaborazione documenti o uno strumento di generazione di codice per il Suo team di ingegneri. Ogni applicazione si connette al runtime del modello tramite API controllate.
Infine, il livello di sicurezza e controllo accessi avvolge il tutto, gestendo chi può interrogare il modello, quali dati entrano ed escono e come vengono registrate le risposte ai fini della conformità.
| Livello di implementazione | Cosa include | Strumenti di esempio |
|---|---|---|
| Hardware | Server, GPU, rete | NVIDIA A100, rack server on-site |
| Runtime del modello | Motore di inferenza, gestione dei modelli | Ollama, vLLM, TGI |
| Livello applicativo | Strumenti aziendali, interfacce, integrazioni | App personalizzate, Open WebUI, portali interni |
| Sicurezza e accesso | Autenticazione, logging, cifratura, controlli di rete | VPN, LDAP, API gateway |
Impostare correttamente questa architettura sin dall'inizio risparmia molti problemi in seguito. Esaminare le best practice di architettura AI prima di progettare la Sua implementazione aiuta a evitare errori strutturali comuni che diventano costosi da correggere.
Scegliere il modello giusto per le esigenze del Suo business
Il panorama dei modelli open source è maturato al punto che la maggior parte dei casi d'uso aziendali è ben servita senza un modello proprietario. Ecco una suddivisione pratica di ciò che i diversi tipi di modelli tendono a gestire bene:
| Caso d'uso aziendale | Dimensione del modello consigliata | Note |
|---|---|---|
| FAQ di assistenza clienti, Q&A di base | Da 7B a 13B parametri | Funziona efficientemente su hardware GPU di fascia media |
| Analisi documenti, revisione contratti | Da 13B a 34B parametri | Beneficia di un supporto per finestre di contesto più ampie |
| Generazione di codice e supporto tecnico | Da 7B a 13B (specifici per codice) | Modelli come CodeLlama sono progettati appositamente per questo |
| Ragionamento complesso e attività multi-step | Da 34B a 70B parametri | Richiede un'infrastruttura GPU più consistente |
| Attività multimodali incluse analisi di immagini | Modelli multimodali specializzati | I requisiti hardware variano in modo significativo |
Partire più piccolo e scalare in base ai dati di utilizzo reali è quasi sempre l'approccio più intelligente. Distribuire un modello 70B il primo giorno quando un 13B avrebbe coperto il 90% del Suo carico di lavoro è un modo costoso per imparare quella lezione.
Considerazioni pratiche prima dell'implementazione
A cosa deve prepararsi il Suo team IT
L'AI on-premise non è un prodotto plug-and-play. Il Suo team sarà responsabile degli aggiornamenti dei modelli, del patching di sicurezza, della manutenzione hardware e del monitoraggio delle prestazioni. Sono responsabilità gestibili per la maggior parte dei dipartimenti IT enterprise, ma devono essere considerate nella pianificazione.
Un consiglio pratico: tratti l'implementazione AI come qualsiasi altro servizio interno critico. Ciò significa pianificazione della ridondanza, procedure di backup, dashboard di monitoraggio e un percorso di escalation quando qualcosa va storto. I team che la affrontano come una semplice installazione software spesso incontrano problemi nei momenti peggiori.
La sicurezza merita un'attenzione specifica. Un sistema AI connesso a database interni e archiviazione documentale è un obiettivo di alto valore se mal configurato. Esaminare i protocolli di sicurezza AI prima del go-live, incluse segmentazione della rete, requisiti di autenticazione e logging degli output, non è opzionale, è fondamentale.
Integrazione con i sistemi aziendali esistenti
Il vero valore dell'AI on-premise per le aziende spesso non deriva dall'assistente stesso, ma da quanto profondamente si collega ai sistemi esistenti. Un'AI in grado di interrogare il Suo CRM, attingere dalla Sua knowledge base interna, leggere email nel contesto e scrivere nei Suoi strumenti di gestione progetti è molto più utile di un'interfaccia chat autonoma.
Questo tipo di integrazione è realizzabile on-premise ed è spesso più facile da costruire quando controlla l'intero stack. Può esporre API interne al modello, configurare pipeline di retrieval-augmented generation che attingono dati in tempo reale da fonti interne e costruire workflow di tool-calling personalizzati esattamente in base al modo in cui il Suo team opera.
Un buon esempio è uno studio di consulenza professionale che ha implementato un assistente on-premise addestrato sulla propria documentazione di progetti passati. I consulenti possono ora interrogare anni di case study interni, metodologie e dati dei clienti senza che alcuna di queste informazioni passi per un servizio cloud. L'assistente fa risparmiare ore per ogni incarico e lo studio ha il controllo totale su ciò a cui può e non può accedere.
Cose da sapere
Alcuni dettagli importanti vengono spesso omessi dalla presentazione standard dell'AI on-premise:
La tempistica di configurazione iniziale è più lunga di quanto la maggior parte dei team si aspetti. Un'implementazione enterprise realistica dall'approvvigionamento hardware all'assistente production-ready richiede tipicamente tra sei e dodici settimane, a seconda della complessità dell'integrazione.
La disponibilità delle GPU influisce sulle Sue opzioni di modello. Non tutti i modelli open source funzionano in modo efficiente su hardware solo CPU. Se la Sua infrastruttura non include schede GPU moderne, potrebbe essere limitato a modelli più piccoli e quantizzati fino all'aggiornamento dell'hardware.
Il fine-tuning richiede dati puliti e ben etichettati. Molte aziende vogliono effettuare il fine-tuning dei modelli su dati proprietari ma sottovalutano la preparazione che tali dati richiedono in anticipo. Preveda tempo per la pulizia dei dati prima di prevedere tempo per il fine-tuning.
Le licenze dei modelli si applicano comunque on-premise. Open source non significa sempre uso commerciale senza restrizioni. Verifichi la licenza specifica per qualsiasi modello intenda implementare in un contesto aziendale. LLaMA 3, ad esempio, ha una licenza commerciale personalizzata con condizioni legate alle dimensioni della base utenti.
Il supporto del fornitore è limitato. A differenza dei prodotti AI cloud con team di supporto dedicati, le implementazioni open source on-premise si affidano in gran parte alla documentazione della community e alle competenze interne. Costruire conoscenza interna in anticipo riduce la dipendenza dai service desk esterni.
La velocità di inferenza dipende dal Suo hardware. I fornitori cloud gestiscono cluster ottimizzati con gli acceleratori più recenti. La Sua velocità di inferenza on-premise potrebbe essere più lenta per modelli di grandi dimensioni, il che è importante per le applicazioni in tempo reale rivolte all'utente. Pianifichi di conseguenza.
Fare la scelta giusta per la Sua organizzazione
L'AI on-premise per le aziende non è la risposta giusta per ogni organizzazione. Se il Suo team è piccolo, i Suoi dati non sono particolarmente sensibili e ha bisogno di muoversi rapidamente, un'implementazione AI cloud ben configurata potrebbe essere il punto di partenza migliore. L'overhead operativo della gestione della propria infrastruttura ha un costo reale.
Ma se gestisce dati regolamentati, sta integrando l'AI nelle operazioni aziendali core, prevede volumi di utilizzo elevati o semplicemente non è disposto a lasciare che le decisioni di policy di un fornitore influenzino i Suoi flussi di lavoro, il percorso on-premise offre qualcosa che i servizi cloud non possono eguagliare: un controllo autentico. Il Suo modello, i Suoi dati, le Sue regole.
Gli strumenti per realizzarlo non sono mai stati più accessibili. La community open source ha svolto il duro lavoro di rendere i modelli AI potenti implementabili da team di ingegneri standard senza competenze ML a livello di dottorato. Ciò che un tempo richiedeva un team AI specializzato e un budget massiccio è ora alla portata di aziende di medie dimensioni con una solida funzione IT e un caso d'uso chiaro.
Domande frequenti
L'AI può essere implementata on-premise?
Sì, l'AI può assolutamente essere implementata on-premise utilizzando modelli open source e infrastruttura di inferenza autogestita su hardware di proprietà aziendale o in leasing privato. Aziende nei settori sanitario, finanziario e legale già eseguono sistemi AI in produzione in questo modo per soddisfare i requisiti di conformità e controllo dei dati.
Quale AI è la migliore per gli imprenditori?
La migliore AI per un imprenditore dipende dal caso d'uso, ma i modelli open source come LLaMA 3 o Mistral implementati su infrastruttura privata offrono la combinazione più solida di controllo, personalizzazione ed efficienza dei costi a lungo termine. Strumenti cloud come ChatGPT for Business funzionano bene per casi d'uso più leggeri e meno sensibili dove la flessibilità nella gestione dei dati è accettabile.
Cos'è la regola del 30% nell'AI?
La regola del 30% nell'AI si riferisce alla linea guida generale secondo cui l'automazione AI dovrebbe gestire circa il 30% di un'attività o di un flusso di lavoro, mentre gli esseri umani gestiscono il restante 70% che richiede giudizio e contesto. È un framework pratico per identificare quali processi aziendali sono buoni candidati per l'assistenza AI senza sovra-automatizzare decisioni che necessitano ancora di supervisione umana.
Cos'è l'AI on-premise?
L'AI on-premise è un sistema di intelligenza artificiale implementato su server o hardware che un'azienda possiede e controlla direttamente, anziché accessibile tramite un fornitore cloud di terze parti. Mantiene tutta l'elaborazione dei dati all'interno dell'infrastruttura aziendale, il che è critico per i settori sensibili alla privacy e le organizzazioni che necessitano del controllo totale sul proprio stack AI.
Quali sono i 7 tipi principali di AI?
I sette tipi principali di AI sono narrow AI, general AI, AI superintelligente, macchine reattive, AI a memoria limitata, AI di teoria della mente e AI auto-consapevole. La maggior parte degli strumenti AI aziendali oggi rientra nelle categorie narrow e a memoria limitata, che sono sistemi progettati appositamente per gestire attività specifiche anziché ragionamento generale o pensiero auto-diretto.