
企業地端 AI 指的是將人工智慧系統直接部署在公司自有硬體或私有伺服器上,而非透過雲端服務供應商存取。它賦予組織對其資料、AI 行為以及連接對象的完全控制權。
大多數關於企業 AI 的討論都集中在下一個要訂閱哪個雲端工具。這種思路忽略了一些重要的東西。對於越來越多的組織來說,真正的問題不是要為哪個平台付費,而是要不要把整個技術堆疊搬進內部。答案取決於你的產業、資料敏感度、團隊的技術能力以及長期成本預期。本指南將逐一梳理這些內容,讓你做出明智的決策,而不是被動的反應。

企業地端 AI 真正的意義
這個詞聽起來很技術化,但概念其實很直接。當你使用像 Microsoft Azure OpenAI 或 Google Vertex AI 這類服務時,你的資料會傳輸到外部伺服器,經過處理,再返回給你。供應商負責管理基礎設施、模型更新以及他們那一端管道的安全。
地端部署完全顛覆了這種模式。AI 在你公司獨家擁有或租用的伺服器上執行,無論是辦公室裡的機架、託管設施,還是任何第三方都無法存取的私有雲環境。你的資料永遠不會離開你所定義的界線。
這對於資料處理受監管的產業極為重要。一家使用地端 AI 系統分析病患記錄的醫院,無需擔心供應商的資料處理協議是否符合醫療法規。一家在本地執行合約分析的律師事務所,也無需向客戶揭露他們的文件經過了第三方伺服器。資料就留在它該在的地方。
對於非受監管產業的企業而言,吸引力同樣真實。競爭情報、內部財務資料、客戶行為模式以及產品開發路線圖,都是企業合理偏好保留在自家圍牆之內的東西。
為什麼越來越多的企業朝這個方向發展

資料控制的論點
雲端 AI 供應商聲譽良好,但他們並非看不見。當你向第三方模型傳送資料時,你就接受了他們的服務條款、安全姿態,以及他們關於哪些內容被記錄、保留或用於模型改進的政策決定。大多數企業協議都包含訓練資料的退出選項,但底層對他人基礎設施的依賴仍然存在。
地端部署消除了這種依賴。你的安全團隊制定規則。你的 IT 基礎設施處理存取控制。你的合規長可以稽核整個管道,無需等待供應商的配合。對於曾經透過第三方服務遭遇資料外洩的組織而言,這種程度的直接控制不是奢侈品,而是必需品。
長期成本的可預測性
雲端 AI 定價在小規模下很有吸引力,但隨著使用量的成長會變得不可預測。一個每月執行數十萬次推論呼叫的團隊,會開始感受到每個 token 的成本以試行階段未曾意識到的方式累積。硬體前期投入昂貴,但它不會在員工每次向 AI 提問時寄帳單給你。
對於有持續高量 AI 使用需求的企業,雲端成本和地端基礎設施投資之間的損益平衡點通常落在兩到三年之內。在那之後,地端部署的營運成本除了維護和電力之外幾乎為零。
了解 AI 功能如何對應到硬體需求,能協助團隊在承諾購買基礎設施之前準確規劃這項投資。
無限制的客製化
雲端 AI 工具在既定界線內提供配置選項。地端則給你實際的模型權重和整個技術堆疊,以便依需要修改。這意味著你可以使用專有資料對模型進行微調,在每一層調整系統行為,與內部資料庫和工具深度整合,並像管理任何其他內部軟體一樣對整個 AI 環境進行版本控制。
例如,一家零售公司可以使用其特定的產品目錄和客戶服務歷史對語言模型進行微調,使其準確談論其庫存,而不是產生通用答案。這種程度的客製化是標準雲端 API 根本無法提供的。
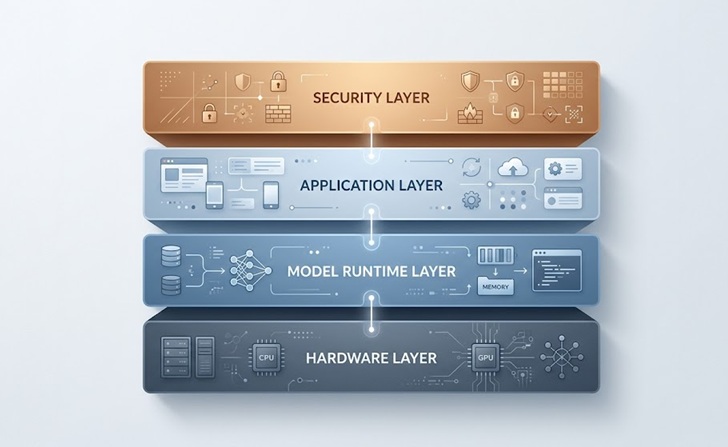
企業地端 AI 部署的典型結構
核心架構
大多數企業地端 AI 部署,無論涉及的具體工具為何,都共享一種共同模式。
基礎是硬體層,包含執行模型的伺服器、GPU 和網路設備。在其之上是模型執行階段,通常是一種編排工具,負責將模型載入記憶體、處理請求,並暴露其他內部應用程式可以呼叫的 API 端點。
應用層是實際業務工具所在之處,無論是客戶服務聊天機器人、內部知識庫助手、文件處理管道,或是為工程團隊提供的程式碼生成工具。每個應用程式都透過受控的 API 連接到模型執行階段。
最後,安全和存取控制層包覆著一切,管理誰可以查詢模型、哪些資料進出,以及如何為合規目的記錄回應。
| 部署層 | 包含內容 | 範例工具 |
|---|---|---|
| 硬體 | 伺服器、GPU、網路 | NVIDIA A100、現場伺服器機架 |
| 模型執行階段 | 推論引擎、模型管理 | Ollama、vLLM、TGI |
| 應用層 | 業務工具、介面、整合 | 客製應用、Open WebUI、內部入口網站 |
| 安全與存取 | 認證、記錄、加密、網路控制 | VPN、LDAP、API gateways |
一開始就把這個架構做對,能在以後省去大量的痛苦。在設計部署之前回顧 AI 架構最佳實務,有助於避免那些後期修復成本高昂的常見結構性錯誤。
為業務需求選擇正確的模型
開源模型生態已經成熟到一定程度,大多數業務使用案例無需專有模型即可獲得良好支援。以下是不同類型模型擅長處理什麼的實用分類:
| 業務使用案例 | 建議模型規模 | 備註 |
|---|---|---|
| 客戶支援 FAQ、基本問答 | 7B 到 13B 參數 | 在中階 GPU 硬體上高效運作 |
| 文件分析、合約審查 | 13B 到 34B 參數 | 受益於更長上下文視窗的支援 |
| 程式碼生成和技術支援 | 7B 到 13B(程式碼專用) | CodeLlama 等模型專為此而設計 |
| 複雜推理和多步任務 | 34B 到 70B 參數 | 需要更強大的 GPU 基礎設施 |
| 包含影像分析的多模態任務 | 專門的多模態模型 | 硬體需求差異很大 |
從較小規模開始,並依據真實使用資料擴展,幾乎總是較聰明的做法。在 13B 模型本可以涵蓋 90% 工作負載的情況下,第一天就部署 70B 模型,是一種以昂貴代價學到這個教訓的方式。
部署前的實際考量
你的 IT 團隊需要為什麼做準備
地端 AI 不是隨插即用的產品。你的團隊將負責模型更新、安全修補、硬體維護和效能監控。對於大多數企業 IT 部門而言,這些都是可管理的職責,但在規劃時需要納入考量。
一個實用建議:像對待其他任何關鍵內部服務一樣對待 AI 部署。這意味著冗餘規劃、備份程序、監控儀表板,以及在出現問題時的升級路徑。把它當作普通軟體安裝的團隊,往往會在最糟糕的時刻遇到問題。
安全應獲得特別關注。一個連接到內部資料庫和文件儲存的 AI 系統,如果設定不當,就是高價值的攻擊目標。在上線前回顧 AI 安全協定,包含網路分段、認證需求和輸出記錄,並非可選項,而是基礎。
與現有業務系統的整合
企業地端 AI 的真正價值,往往不在於助手本身,而在於它與現有系統的深度連接。一個能夠查詢你的 CRM、從內部知識庫中擷取資料、在脈絡中閱讀電子郵件,並將資料寫回專案管理工具的 AI,遠比一個獨立的聊天介面有用得多。
這種整合在地端環境中是可實現的,而且當你掌控整個技術堆疊時,通常更容易建構。你可以向模型暴露內部 API,設定從內部來源擷取即時資料的檢索增強生成管道,並建構完全符合團隊工作方式的客製工具呼叫工作流程。
一個好例子是一家專業服務公司部署了一個以過往專案文件訓練的地端助手。顧問現在可以查詢多年的內部案例研究、方法論和客戶資料,而這些資訊都不會接觸到任何雲端服務。該助手為每次業務節省數小時,公司對其可存取和不可存取的內容擁有完全控制權。
需要了解的事項
在地端 AI 的標準宣傳中,一些重要細節常常被忽略:
初始設定時間比大多數團隊預期的還要久。從硬體採購到生產就緒助手的現實企業部署,通常需要六到十二週,具體取決於整合複雜度。
GPU 可用性會影響你的模型選擇。並非所有開源模型都能在僅 CPU 硬體上高效運作。如果你的基礎設施不包含現代 GPU 卡,在硬體升級之前,你可能僅限於較小的、量化後的模型。
微調需要乾淨且標註良好的資料。許多企業想在專有資料上微調模型,但低估了這些資料事先所需的準備量。在為微調預留時間之前,先為資料清理預留時間。
模型授權在地端環境中依然適用。開源並不總是意味著不受限制的商業用途。檢查你計畫在業務環境中部署的任何模型的具體授權。例如,LLaMA 3 有一個自訂的商業授權,其條件與使用者基數規模掛鉤。
供應商支援有限。與擁有專屬支援團隊的雲端 AI 產品不同,地端開源部署在很大程度上依賴社群文件和內部專業知識。盡早建立內部知識可以降低你對外部服務台的依賴。
推論速度取決於你的硬體。雲端供應商運作的是配備最新加速器的最佳化叢集。對於大型模型,你的地端推論速度可能較慢,這對面向使用者的即時應用很重要。要據此進行規劃。
為你的組織做出正確的決定
企業地端 AI 並非每個組織的正確答案。如果你的團隊規模較小、資料不是特別敏感,並且需要快速行動,那麼一個設定良好的雲端 AI 部署可能是更好的起點。執行自己基礎設施的營運負擔有真實的成本。
但是,如果你處理受監管的資料、將 AI 建構到核心業務營運中、預計有高使用量,或者根本不願讓供應商的政策決定影響你的工作流,地端路徑將提供雲端服務無法匹敵的東西:真正的控制。你的模型、你的資料、你的規則。
實現這些的工具從未如此容易取得。開源社群已經完成了艱困的工作,使得強大的 AI 模型可以由標準工程團隊部署,而無需博士級別的 ML 專業知識。曾經需要專門 AI 團隊和巨額預算的事情,如今對於擁有紮實 IT 職能和明確使用案例的中型公司而言已觸手可及。
常見問題
AI 可以地端部署嗎?
是的,AI 完全可以使用開源模型和自管理推論基礎設施,在公司自有或私下租用的硬體上進行地端部署。 醫療、金融和法律產業的企業已經以這種方式運行生產級 AI 系統,以滿足合規和資料控制需求。
哪種 AI 最適合企業主?
最適合企業主的 AI 取決於使用案例,但部署在私有基礎設施上的開源模型如 LLaMA 3 或 Mistral,在控制、客製化和長期成本效益方面提供了最強的組合。 像 ChatGPT for Business 這樣的雲端工具對於較輕、不太敏感的使用案例效果不錯,前提是資料處理彈性是可接受的。
AI 中的 30% 規則是什麼?
AI 中的 30% 規則指的是一個通用指導原則:AI 自動化應該處理任務或工作流的大約 30%,而人類則管理剩餘的 70%,這部分需要判斷和脈絡。 這是一個實用框架,用於辨識哪些業務流程是 AI 輔助的好候選,而不會過度自動化那些仍然需要人工監督的決定。
什麼是地端 AI?
地端 AI 是一種部署在企業自己擁有並直接控制的伺服器或硬體上的人工智慧系統,而不是透過第三方雲端供應商存取。 它將所有資料處理保留在公司自己的基礎設施內,這對於隱私敏感的產業以及需要對其 AI 技術堆疊擁有完全控制權的組織至關重要。
AI 的 7 種主要類型是什麼?
AI 的七種主要類型是窄 AI、通用 AI、超級智慧 AI、反應型機器、有限記憶 AI、心智理論 AI 和自我意識 AI。 當今大多數業務 AI 工具屬於窄 AI 和有限記憶類別,它們是為處理特定任務而專門建構的系統,而不是用於通用推理或自我導向的思考。