
On-premise AI för företag innebär att distribuera artificiell intelligens-system direkt på företagsägd hårdvara eller privata servrar i stället för att komma åt dem via en molnleverantör. Det ger organisationer full kontroll över sin data, hur AI:n beter sig och vad den ansluter till.
De flesta samtalen om AI för företag fokuserar på vilket molnverktyg man ska prenumerera på härnäst. Den inramningen missar något viktigt. För ett växande antal organisationer är den verkliga frågan inte vilken plattform man ska betala för, utan om man ska föra hela stacken in i huset. Svaret beror på din bransch, din datasäkerhetskänslighet, ditt teams tekniska kapacitet och dina långsiktiga kostnadsförväntningar. Denna guide går igenom allt detta så att du kan fatta ett välgrundat beslut i stället för ett reaktivt.

Vad on-premise AI för företag faktiskt innebär
Frasen låter teknisk, men konceptet är enkelt. När du använder en tjänst som Microsoft Azure OpenAI eller Google Vertex AI färdas din data till externa servrar, bearbetas och kommer tillbaka. Leverantören hanterar infrastrukturen, modelluppdateringarna och säkerheten i sin ände av pipelinen.
On-premise vänder helt på den modellen. AI:n körs på servrar som ditt företag äger eller hyr exklusivt, vare sig det är ett rack på ditt kontor, en samlokaliseringsanläggning eller en privat molnmiljö som ingen tredje part kan komma åt. Din data lämnar aldrig den perimeter du definierar.
Detta är enormt viktigt för branscher där datahantering är reglerad. Ett sjukhus som använder ett on-premise AI-system för att analysera patientjournaler behöver inte oroa sig för om leverantörens databehandlingsavtal följer hälso- och sjukvårdsregler. En advokatbyrå som kör kontraktsanalys lokalt behöver inte avslöja för klienter att deras dokument har passerat genom en tredjepartsserver. Datan stannar helt enkelt där den hör hemma.
För företag utanför reglerade branscher är dragningskraften fortfarande verklig. Konkurrensanalys, intern finansiell data, beteendemönster hos kunder och färdplaner för produktutveckling är alla saker som företag rimligen föredrar att hålla inom sina egna väggar.
Varför fler företag rör sig i denna riktning

Argumentet om datakontroll
Moln-AI-leverantörer är ansedda, men de är inte osynliga. När du skickar data till en tredjepartsmodell accepterar du deras användarvillkor, deras säkerhetsställning och deras policybeslut om vad som loggas, behålls eller används för modellförbättring. De flesta företagsavtal inkluderar opt-outs för träningsdata, men det underliggande beroendet av någon annans infrastruktur kvarstår.
On-premise-distribution tar bort det beroendet. Ditt säkerhetsteam sätter reglerna. Din IT-infrastruktur hanterar åtkomstkontrollerna. Dina efterlevnadsansvariga kan revidera hela pipelinen utan att vänta på en leverantörs samarbete. För organisationer som har upplevt dataintrång genom tredjepartstjänster är den nivån av direkt kontroll inte en lyx, det är ett krav.
Långsiktig kostnadsförutsägbarhet
Moln-AI-priser är attraktiva i liten skala men blir oförutsägbara när användningen växer. Ett team som kör hundratusentals inferensanrop per månad börjar känna att kostnaderna per token staplas på sätt som inte var uppenbara under pilotfasen. Hårdvara är dyr i förskott, men skickar inte en räkning varje gång en anställd ställer en fråga till AI:n.
För företag med konsekvent, hög volym av AI-användning landar break-even-punkten mellan molnkostnader och on-premise-infrastrukturinvesteringar ofta inom två till tre år. Efter det är on-premise-uppställningen i praktiken gratis att köra utöver underhåll och el.
Att förstå hur AI-funktioner mappas mot hårdvarukrav hjälper team att planera den investeringen exakt innan de förbinder sig till infrastrukturköp.
Anpassning utan gränser
Moln-AI-verktyg ger dig konfigurationsalternativ inom en definierad gräns. On-premise ger dig de faktiska modellvikterna och hela stacken att modifiera efter behov. Det betyder att du kan finjustera modeller på din proprietära data, justera systembeteendet på varje lager, integrera djupt med interna databaser och verktyg och versionskontrollera hela AI-miljön på samma sätt som du hanterar all annan intern programvara.
Ett detaljhandelsföretag kan till exempel finjustera en language model på sin specifika produktkatalog och kundtjänsthistorik så att den talar exakt om sitt eget lager i stället för att producera generiska svar. Den nivån av anpassning är helt enkelt inte tillgänglig genom ett standard-moln-API.
Hur on-premise AI-distributioner typiskt är strukturerade
Kärnarkitekturen
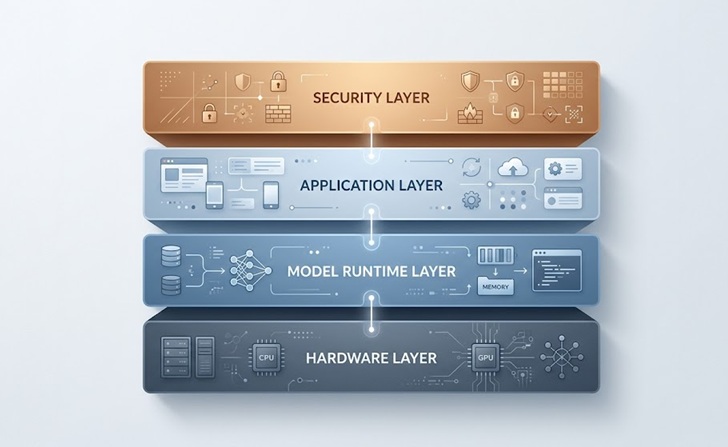
De flesta on-premise AI-uppställningar för företag delar ett gemensamt mönster oavsett de specifika verktyg som är inblandade.
Grunden är hårdvarulagret, som inkluderar servrarna, GPU:erna och nätverksutrustningen som kör modellen. Ovanför det sitter modellkörtiden, vanligtvis ett orkestreringsverktyg som hanterar inläsning av modeller i minnet, hanterar förfrågningar och exponerar en API-slutpunkt som andra interna applikationer kan anropa.
Applikationslagret är där de faktiska affärsverktygen lever, vare sig det är en kundtjänstchatbot, en intern kunskapsbasassistent, en dokumentbearbetningspipeline eller ett kodgenereringsverktyg för ditt ingenjörsteam. Varje applikation ansluter till modellkörtiden genom kontrollerade API:er.
Slutligen omsluter säkerhets- och åtkomstkontrolllagret allt och hanterar vem som kan fråga modellen, vilken data som flödar in och ut och hur svar loggas för efterlevnadsändamål.
| Distributionslager | Vad det inkluderar | Exempelverktyg |
|---|---|---|
| Hårdvara | Servrar, GPU:er, nätverk | NVIDIA A100, serverrack på plats |
| Modellkörtid | Inferensmotor, modellhantering | Ollama, vLLM, TGI |
| Applikationslager | Affärsverktyg, gränssnitt, integrationer | Anpassade appar, Open WebUI, interna portaler |
| Säkerhet och åtkomst | Autentisering, loggning, kryptering, nätverkskontroller | VPN, LDAP, API-gateways |
Att få denna arkitektur rätt från start sparar en betydande mängd smärta senare. Att gå igenom bästa praxis för AI-arkitektur innan du designar din distribution hjälper till att undvika vanliga strukturella misstag som blir dyra att åtgärda.
Välja rätt modell för dina affärsbehov
Landskapet av open source-modeller har mognat till en punkt där de flesta affärsanvändningsfall är välbetjänta utan en proprietär modell. Här är en praktisk uppdelning av vad olika modelltyper tenderar att hantera väl:
| Affärsanvändningsfall | Rekommenderad modellstorlek | Anteckningar |
|---|---|---|
| Kundsupport-FAQ, grundläggande Q&A | 7B till 13B parametrar | Körs effektivt på GPU-hårdvara i mellanklass |
| Dokumentanalys, kontraktsgranskning | 13B till 34B parametrar | Drar nytta av stöd för längre kontextfönster |
| Kodgenerering och teknisk support | 7B till 13B (kodspecifik) | Modeller som CodeLlama är byggda specifikt för detta |
| Komplext resonemang och flerstegsuppgifter | 34B till 70B parametrar | Kräver mer omfattande GPU-infrastruktur |
| Multimodala uppgifter inklusive bildanalys | Specialiserade multimodala modeller | Hårdvarukraven varierar avsevärt |
Att börja mindre och skala upp baserat på verklig användningsdata är nästan alltid den smartare metoden. Att distribuera en 70B-modell dag ett när en 13B skulle ha täckt 90 % av din arbetsbelastning är ett dyrt sätt att lära sig den läxan.
Praktiska överväganden innan du distribuerar
Vad ditt IT-team behöver förbereda sig för
On-premise AI är inte en plug-and-play-produkt. Ditt team kommer att ansvara för modelluppdateringar, säkerhetspatchning, hårdvaruunderhåll och prestandaövervakning. Detta är hanterbara ansvarsområden för de flesta företags-IT-avdelningar, men de behöver beaktas i planeringen.
Ett praktiskt tips: behandla AI-distributionen som vilken annan kritisk intern tjänst som helst. Det betyder redundansplanering, säkerhetskopieringsrutiner, övervakningsdashboards och en eskaleringsväg när något går fel. Team som närmar sig det bara som mjukvaruinstallation stöter ofta på problem i sämsta möjliga ögonblick.
Säkerhet förtjänar specifik uppmärksamhet. Ett AI-system anslutet till interna databaser och dokumentlagring är ett högvärdesmål om det är felkonfigurerat. Att gå igenom protokoll för AI-säkerhet före driftsättning, inklusive nätverkssegmentering, autentiseringskrav och utdataloggning, är inte valfritt utan grundläggande.
Integration med befintliga affärssystem
Det verkliga värdet av on-premise AI för företag kommer ofta inte från själva assistenten utan från hur djupt den ansluter till befintliga system. En AI som kan fråga ditt CRM, hämta från din interna kunskapsbas, läsa e-post i sitt sammanhang och skriva tillbaka till dina projekthanteringsverktyg är betydligt mer användbar än ett fristående chattgränssnitt.
Den här typen av integration är genomförbar on-premise och är ofta lättare att bygga när du kontrollerar hela stacken. Du kan exponera interna API:er för modellen, konfigurera retrieval-augmented generation-pipelines som hämtar realtidsdata från interna källor och bygga anpassade tool-calling-arbetsflöden som är skräddarsydda exakt efter hur ditt team arbetar.
Ett bra exempel är ett professionellt tjänsteföretag som distribuerade en on-premise-assistent som tränats på deras tidigare projektdokumentation. Konsulter kan nu fråga år av interna fallstudier, metoder och kunddata utan att någon av den informationen rör en molntjänst. Assistenten sparar timmar per uppdrag och företaget har full kontroll över vad den kan och inte kan komma åt.
Saker att veta
Några viktiga detaljer utelämnas ofta från standardpresentationen för on-premise AI:
Tidsplanen för den första uppställningen är längre än de flesta team förväntar sig. En realistisk företagsdistribution från hårdvaruinköp till produktionsklar assistent tar typiskt mellan sex och tolv veckor, beroende på integrationskomplexiteten.
GPU-tillgänglighet påverkar dina modellalternativ. Inte alla open source-modeller körs effektivt på hårdvara med enbart CPU. Om din infrastruktur inte inkluderar moderna GPU-kort kan du vara begränsad till mindre, kvantiserade modeller tills hårdvaran uppgraderas.
Finjustering kräver ren, välmärkt data. Många företag vill finjustera modeller på proprietär data men underskattar hur mycket förberedelse den datan behöver i förväg. Budgetera tid för datarensning innan du budgeterar tid för finjustering.
Modelllicenser gäller fortfarande on-premise. Open source betyder inte alltid obegränsad kommersiell användning. Kontrollera den specifika licensen för varje modell du planerar att distribuera i ett affärssammanhang. LLaMA 3 har till exempel en anpassad kommersiell licens med villkor knutna till användarbasens storlek.
Leverantörssupport är begränsad. Till skillnad från moln-AI-produkter med dedikerade supportteam förlitar sig on-premise open source-distributioner till stor del på communitydokumentation och intern expertis. Att bygga intern kunskap tidigt minskar ditt beroende av externa helpdesks.
Inferenshastigheten beror på din hårdvara. Molnleverantörer kör optimerade kluster med de senaste acceleratorerna. Din on-premise inferenshastighet kan vara långsammare för stora modeller, vilket är viktigt för realtidsapplikationer som vänder sig mot användare. Planera därefter.
Att fatta rätt beslut för din organisation
On-premise AI för företag är inte det rätta svaret för varje organisation. Om ditt team är litet, din data inte är särskilt känslig och du behöver röra dig snabbt, kan en välkonfigurerad moln-AI-distribution vara den bättre utgångspunkten. Den operativa overheaden av att köra din egen infrastruktur har en verklig kostnad.
Men om du hanterar reglerad data, bygger in AI i kärnverksamheten, projekterar höga användningsvolymer eller helt enkelt inte är villig att låta en leverantörs policybeslut påverka dina arbetsflöden, levererar on-premise-vägen något som molntjänster inte kan matcha: genuin kontroll. Din modell, din data, dina regler.
Verktygen för att få det att hända har aldrig varit mer tillgängliga. Open source-communityn har gjort det hårda arbetet med att göra kraftfulla AI-modeller distribuerbara av vanliga ingenjörsteam utan ML-expertis på doktorandnivå. Det som tidigare krävde ett specialiserat AI-team och en stor budget är nu inom räckhåll för medelstora företag med en solid IT-funktion och ett tydligt användningsfall.
Vanliga frågor
Kan AI distribueras on-premise?
Ja, AI kan absolut distribueras on-premise med hjälp av open source-modeller och självhanterad inferensinfrastruktur på företagsägd eller privat hyrd hårdvara. Företag inom hälso- och sjukvård, finans och juridik kör redan produktions-AI-system på detta sätt för att uppfylla krav på efterlevnad och datakontroll.
Vilken AI är bäst för företagsägare?
Den bästa AI:n för en företagsägare beror på användningsfallet, men open source-modeller som LLaMA 3 eller Mistral distribuerade på privat infrastruktur erbjuder den starkaste kombinationen av kontroll, anpassning och långsiktig kostnadseffektivitet. Molnverktyg som ChatGPT for Business fungerar bra för lättare, mindre känsliga användningsfall där flexibilitet i datahantering är acceptabel.
Vad är 30 %-regeln inom AI?
30 %-regeln inom AI hänvisar till den allmänna riktlinjen att AI-automatisering bör hantera ungefär 30 % av en uppgift eller ett arbetsflöde, medan människor hanterar de återstående 70 % som kräver omdöme och sammanhang. Det är ett praktiskt ramverk för att identifiera vilka affärsprocesser som är bra kandidater för AI-stöd utan att överautomatisera beslut som fortfarande behöver mänsklig översyn.
Vad är on-premise AI?
On-premise AI är ett artificiellt intelligenssystem som distribueras på servrar eller hårdvara som ett företag äger och kontrollerar direkt, snarare än att nås via en tredjepartsmolnleverantör. Det håller all databehandling inom företagets egen infrastruktur, vilket är kritiskt för integritetskänsliga branscher och organisationer som behöver full kontroll över sin AI-stack.
Vilka är de 7 huvudtyperna av AI?
De sju huvudtyperna av AI är smal AI, generell AI, superintelligent AI, reaktiva maskiner, AI med begränsat minne, AI med teori om sinnet och självmedveten AI. De flesta affärs-AI-verktyg i dag faller in i kategorierna smal och begränsat minne, vilka är specialbyggda system designade för att hantera specifika uppgifter snarare än generellt resonemang eller självstyrt tänkande.