
AI on-premise para empresas refere-se à implantação de sistemas de inteligência artificial diretamente em hardware próprio da empresa ou em servidores privados, em vez de acessá-los por meio de um provedor de nuvem. Ela dá às organizações autoridade completa sobre seus dados, sobre como a AI se comporta e sobre a que ela se conecta.
A maioria das conversas sobre AI para empresas se concentra em qual ferramenta de nuvem assinar em seguida. Essa abordagem deixa de lado algo importante. Para um número crescente de organizações, a verdadeira questão não é qual plataforma pagar, mas sim se vale a pena trazer toda a stack para dentro da empresa. A resposta depende do seu setor, da sensibilidade dos seus dados, da capacidade técnica da sua equipe e das suas expectativas de custo a longo prazo. Este guia percorre tudo isso para que você possa tomar uma decisão informada em vez de reativa.

O que a AI on-premise para empresas realmente significa
A frase parece técnica, mas o conceito é direto. Quando você usa um serviço como Microsoft Azure OpenAI ou Google Vertex AI, seus dados viajam até servidores externos, são processados e voltam. O provedor gerencia a infraestrutura, as atualizações do modelo e a segurança do lado dele do pipeline.
On-premise inverte esse modelo por completo. A AI roda em servidores que sua empresa possui ou aluga com exclusividade, seja um rack no seu escritório, uma instalação de colocation ou um ambiente de nuvem privada ao qual nenhum terceiro tem acesso. Seus dados nunca saem do perímetro que você definiu.
Isso importa enormemente para setores em que o tratamento de dados é regulamentado. Um hospital que usa um sistema de AI on-premise para analisar prontuários de pacientes não precisa se preocupar se os acordos de processamento de dados do fornecedor cumprem as regulamentações de saúde. Um escritório de advocacia que executa análise de contratos localmente não precisa divulgar aos clientes que seus documentos passaram por um servidor de terceiros. Os dados simplesmente permanecem onde devem estar.
Para empresas fora de setores regulamentados, o atrativo ainda é real. Inteligência competitiva, dados financeiros internos, padrões de comportamento de clientes e roadmaps de desenvolvimento de produtos são todas coisas que as empresas razoavelmente preferem manter dentro de suas próprias paredes.
Por que mais empresas estão se movendo nessa direção

O argumento do controle de dados
Fornecedores de AI em nuvem são reputados, mas não são invisíveis. Quando você envia dados a um modelo de terceiros, você está aceitando seus termos de serviço, sua postura de segurança e suas decisões de política sobre o que é registrado, retido ou usado para melhoria do modelo. A maioria dos acordos empresariais inclui opt-outs para dados de treinamento, mas a dependência subjacente da infraestrutura de outra pessoa permanece.
A implantação on-premise remove essa dependência. Sua equipe de segurança define as regras. Sua infraestrutura de TI lida com os controles de acesso. Seus responsáveis pela conformidade podem auditar todo o pipeline sem esperar a cooperação do fornecedor. Para organizações que sofreram violações de dados por meio de serviços de terceiros, esse nível de controle direto não é luxo, é requisito.
Previsibilidade de custos a longo prazo
A precificação de AI em nuvem é atraente em pequena escala, mas se torna imprevisível à medida que o uso cresce. Uma equipe que faz centenas de milhares de chamadas de inferência por mês começa a sentir os custos por token se acumulando de maneiras que não eram óbvias durante a fase piloto. Hardware é caro de início, mas não envia uma conta toda vez que um funcionário faz uma pergunta para a AI.
Para empresas com uso de AI consistente e de alto volume, o ponto de equilíbrio entre custos de nuvem e investimento em infraestrutura on-premise costuma cair em dois a três anos. Depois disso, a configuração on-premise é efetivamente gratuita para operar além de manutenção e eletricidade.
Entender como recursos de AI mapeiam para requisitos de hardware ajuda as equipes a planejar esse investimento com precisão antes de se comprometerem com compras de infraestrutura.
Personalização sem limites
Ferramentas de AI em nuvem oferecem opções de configuração dentro de um limite definido. On-premise dá a você os pesos reais do modelo e a stack completa para modificar conforme necessário. Isso significa que você pode fazer fine-tuning de modelos com seus dados proprietários, ajustar o comportamento do sistema em cada camada, integrar profundamente com bancos de dados e ferramentas internas e versionar todo o ambiente de AI da mesma forma que gerencia qualquer outro software interno.
Uma empresa de varejo, por exemplo, pode fazer fine-tuning de um modelo de linguagem com seu catálogo de produtos específico e histórico de atendimento ao cliente para que ele fale com precisão sobre seu estoque em vez de produzir respostas genéricas. Esse nível de personalização simplesmente não está disponível por meio de uma API de nuvem padrão.
Como as implantações de AI on-premise são tipicamente estruturadas
A arquitetura central
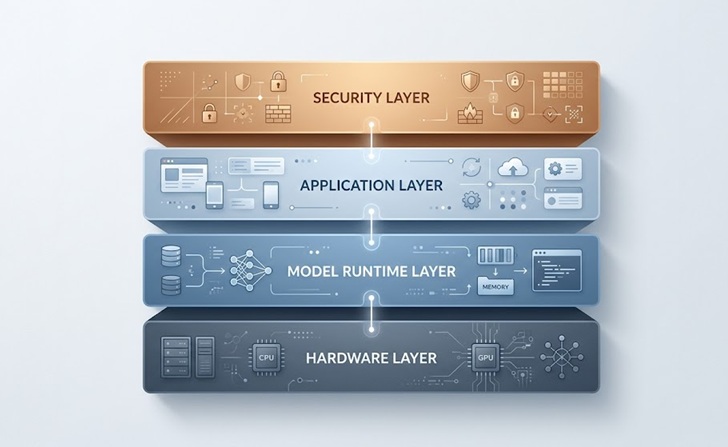
A maioria das configurações de AI on-premise para empresas compartilha um padrão comum, independentemente das ferramentas específicas envolvidas.
A base é a camada de hardware, que inclui os servidores, GPUs e equipamentos de rede que executam o modelo. Acima disso fica o runtime do modelo, normalmente uma ferramenta de orquestração que cuida de carregar os modelos na memória, gerenciar requisições e expor um endpoint de API que outras aplicações internas podem chamar.
A camada de aplicação é onde vivem as ferramentas de negócio reais, seja um chatbot de atendimento ao cliente, um assistente de base de conhecimento interna, um pipeline de processamento de documentos ou uma ferramenta de geração de código para sua equipe de engenharia. Cada aplicação se conecta ao runtime do modelo por meio de APIs controladas.
Por fim, a camada de segurança e controle de acesso envolve tudo, gerenciando quem pode consultar o modelo, quais dados fluem para dentro e para fora e como as respostas são registradas para fins de conformidade.
| Camada de implantação | O que inclui | Exemplos de ferramentas |
|---|---|---|
| Hardware | Servidores, GPUs, rede | NVIDIA A100, racks de servidor no local |
| Runtime do modelo | Motor de inferência, gerenciamento de modelos | Ollama, vLLM, TGI |
| Camada de aplicação | Ferramentas de negócio, interfaces, integrações | Aplicativos personalizados, Open WebUI, portais internos |
| Segurança e acesso | Autenticação, registro, criptografia, controles de rede | VPN, LDAP, API gateways |
Acertar essa arquitetura desde o início poupa uma quantidade significativa de dor depois. Revisar as boas práticas de arquitetura de AI antes de projetar sua implantação ajuda a evitar erros estruturais comuns que se tornam caros para corrigir.
Escolhendo o modelo certo para as necessidades do seu negócio
O cenário de modelos open source amadureceu a ponto de a maioria dos casos de uso de negócio ser bem atendida sem um modelo proprietário. Aqui está uma divisão prática do que diferentes tipos de modelo tendem a lidar bem:
| Caso de uso de negócio | Tamanho de modelo recomendado | Notas |
|---|---|---|
| FAQ de atendimento ao cliente, Q&A básico | 7B a 13B parâmetros | Roda com eficiência em hardware GPU de médio porte |
| Análise de documentos, revisão de contratos | 13B a 34B parâmetros | Se beneficia de suporte a janelas de contexto mais longas |
| Geração de código e suporte técnico | 7B a 13B (específicos para código) | Modelos como CodeLlama são construídos para isso |
| Raciocínio complexo e tarefas multietapas | 34B a 70B parâmetros | Requer infraestrutura GPU mais robusta |
| Tarefas multimodais incluindo análise de imagens | Modelos multimodais especializados | Requisitos de hardware variam significativamente |
Começar menor e escalar com base em dados de uso reais é quase sempre a abordagem mais inteligente. Implantar um modelo 70B no dia um quando um 13B teria coberto 90% da sua carga de trabalho é uma forma cara de aprender essa lição.
Considerações práticas antes de implantar
Para o que sua equipe de TI precisa se preparar
AI on-premise não é um produto plug-and-play. Sua equipe será responsável por atualizações de modelo, aplicação de patches de segurança, manutenção de hardware e monitoramento de desempenho. Essas são responsabilidades gerenciáveis para a maioria dos departamentos de TI empresariais, mas precisam ser levadas em conta no planejamento.
Uma dica prática: trate a implantação de AI como qualquer outro serviço interno crítico. Isso significa planejamento de redundância, procedimentos de backup, dashboards de monitoramento e um caminho de escalonamento para quando algo der errado. Equipes que abordam isso apenas como instalação de software costumam esbarrar em problemas nos piores momentos possíveis.
A segurança merece atenção específica. Um sistema de AI conectado a bancos de dados internos e armazenamento de documentos é um alvo de alto valor se configurado incorretamente. Revisar protocolos de segurança de AI antes da entrada em produção, incluindo segmentação de rede, requisitos de autenticação e registro de saídas, não é opcional, é fundamental.
Integração com sistemas de negócio existentes
O valor real da AI on-premise para empresas frequentemente vem não do assistente em si, mas de quão profundamente ele se conecta a sistemas existentes. Uma AI que consegue consultar seu CRM, extrair dados da sua base de conhecimento interna, ler e-mails em contexto e escrever de volta em suas ferramentas de gerenciamento de projetos é muito mais útil do que uma interface de chat independente.
Esse tipo de integração é alcançável on-premise e costuma ser mais fácil de construir quando você controla a stack completa. Você pode expor APIs internas ao modelo, configurar pipelines de geração aumentada por recuperação que extraem dados ao vivo de fontes internas e construir fluxos de trabalho personalizados de chamada de ferramentas, sob medida para exatamente como sua equipe opera.
Um bom exemplo é uma firma de serviços profissionais que implantou um assistente on-premise treinado em sua documentação de projetos passados. Consultores agora podem consultar anos de estudos de caso internos, metodologias e dados de clientes sem que nenhuma dessas informações toque um serviço de nuvem. O assistente economiza horas por trabalho e a firma tem controle total sobre o que ele pode e o que não pode acessar.
Coisas que você deve saber
Alguns detalhes importantes costumam ficar de fora do discurso padrão sobre AI on-premise:
O cronograma inicial de configuração é mais longo do que a maioria das equipes espera. Uma implantação empresarial realista, da aquisição de hardware até um assistente pronto para produção, leva normalmente entre seis e doze semanas, dependendo da complexidade da integração.
A disponibilidade de GPU afeta suas opções de modelo. Nem todos os modelos open source rodam de forma eficiente em hardware apenas com CPU. Se sua infraestrutura não inclui placas GPU modernas, você pode estar limitado a modelos menores e quantizados até que o hardware seja atualizado.
Fine-tuning exige dados limpos e bem rotulados. Muitas empresas querem fazer fine-tuning de modelos com dados proprietários, mas subestimam quanto preparo esses dados precisam antes. Reserve tempo para limpeza de dados antes de reservar tempo para fine-tuning.
O licenciamento de modelos continua valendo no on-premise. Open source nem sempre significa uso comercial irrestrito. Verifique a licença específica de qualquer modelo que você planeje implantar em um contexto de negócio. O LLaMA 3, por exemplo, tem uma licença comercial personalizada com condições atreladas ao tamanho da base de usuários.
O suporte do fornecedor é limitado. Diferentemente de produtos de AI em nuvem com equipes de suporte dedicadas, implantações on-premise open source dependem em grande parte de documentação da comunidade e expertise interna. Construir conhecimento interno cedo reduz sua dependência de help desks externos.
A velocidade de inferência depende do seu hardware. Provedores de nuvem rodam clusters otimizados com os aceleradores mais recentes. Sua velocidade de inferência on-premise pode ser mais lenta para modelos grandes, o que importa para aplicações em tempo real voltadas ao usuário. Planeje de acordo.
Tomando a decisão certa para sua organização
AI on-premise para empresas não é a resposta certa para toda organização. Se sua equipe é pequena, seus dados não são particularmente sensíveis e você precisa se mover rápido, uma implantação de AI em nuvem bem configurada pode ser um ponto de partida melhor. O overhead operacional de rodar sua própria infraestrutura tem um custo real.
Mas se você lida com dados regulamentados, está construindo AI dentro de operações de negócio centrais, projeta altos volumes de uso ou simplesmente não está disposto a deixar que as decisões de política de um fornecedor afetem seus fluxos de trabalho, o caminho on-premise entrega algo que serviços de nuvem não conseguem igualar: controle genuíno. Seu modelo, seus dados, suas regras.
As ferramentas para fazer isso acontecer nunca foram tão acessíveis. A comunidade open source fez o trabalho duro de tornar modelos de AI poderosos implantáveis por equipes de engenharia padrão, sem precisar de expertise em ML em nível de doutorado. O que antes exigia uma equipe de AI especializada e um orçamento enorme agora está ao alcance de empresas de médio porte com uma função de TI sólida e um caso de uso claro.
Perguntas frequentes
A AI pode ser implantada on-premise?
Sim, a AI pode absolutamente ser implantada on-premise usando modelos open source e infraestrutura de inferência autogerenciada em hardware próprio da empresa ou alugado de forma privada. Empresas dos setores de saúde, financeiro e jurídico já rodam sistemas de AI em produção dessa forma para atender a requisitos de conformidade e controle de dados.
Qual AI é a melhor para donos de empresa?
A melhor AI para um dono de empresa depende do caso de uso, mas modelos open source como LLaMA 3 ou Mistral implantados em infraestrutura privada oferecem a combinação mais forte de controle, personalização e eficiência de custo a longo prazo. Ferramentas de nuvem como ChatGPT for Business funcionam bem para casos de uso mais leves e menos sensíveis, em que a flexibilidade no tratamento de dados é aceitável.
O que é a regra dos 30% em AI?
A regra dos 30% em AI refere-se à diretriz geral de que a automação por AI deve lidar com aproximadamente 30% de uma tarefa ou fluxo de trabalho, com os humanos gerenciando os 70% restantes, que exigem julgamento e contexto. É um framework prático para identificar quais processos de negócio são bons candidatos a assistência por AI sem automatizar em excesso decisões que ainda precisam de supervisão humana.
O que é AI on-premise?
AI on-premise é um sistema de inteligência artificial implantado em servidores ou hardware que uma empresa possui e controla diretamente, em vez de ser acessado por meio de um provedor de nuvem terceirizado. Mantém todo o processamento de dados dentro da própria infraestrutura da empresa, o que é crítico para setores sensíveis à privacidade e organizações que precisam de controle total sobre sua stack de AI.
Quais são os 7 principais tipos de AI?
Os sete principais tipos de AI são AI estreita, AI geral, AI superinteligente, máquinas reativas, AI de memória limitada, AI de teoria da mente e AI autoconsciente. A maioria das ferramentas de AI de negócio hoje se enquadra nas categorias estreita e de memória limitada, que são sistemas construídos com propósito específico para lidar com tarefas determinadas em vez de raciocínio geral ou pensamento autodirigido.