
On-Premise-AI für Unternehmen bezieht sich auf die Bereitstellung von Systemen der künstlichen Intelligenz direkt auf unternehmenseigener Hardware oder privaten Servern, anstatt sie über einen Cloud-Anbieter zu nutzen. Sie gibt Organisationen vollständige Autorität über ihre Daten, das Verhalten der AI und das, womit sie sich verbindet.
Die meisten Gespräche über AI für Unternehmen drehen sich darum, welches Cloud-Tool als Nächstes abonniert werden soll. Diese Sichtweise übersieht etwas Wichtiges. Für eine wachsende Zahl von Organisationen lautet die eigentliche Frage nicht, für welche Plattform man zahlen soll, sondern ob man den gesamten Stack ins Haus holen sollte. Die Antwort hängt von Ihrer Branche, der Sensibilität Ihrer Daten, der technischen Kapazität Ihres Teams und Ihren langfristigen Kostenerwartungen ab. Dieser Leitfaden führt Sie durch all das, damit Sie eine fundierte statt einer reaktiven Entscheidung treffen können.

Was On-Premise-AI für Unternehmen tatsächlich bedeutet
Die Formulierung klingt technisch, das Konzept ist jedoch unkompliziert. Wenn Sie einen Dienst wie Microsoft Azure OpenAI oder Google Vertex AI verwenden, wandern Ihre Daten zu externen Servern, werden dort verarbeitet und kommen zurück. Der Anbieter verwaltet die Infrastruktur, die Modell-Updates und die Sicherheit auf seiner Seite der Pipeline.
On-Premise dreht dieses Modell vollständig um. Die AI läuft auf Servern, die Ihr Unternehmen ausschließlich besitzt oder anmietet, sei es ein Rack in Ihrem Büro, eine Colocation-Einrichtung oder eine private Cloud-Umgebung, auf die kein Dritter zugreifen kann. Ihre Daten verlassen den von Ihnen definierten Perimeter nie.
Das ist von enormer Bedeutung für Branchen, in denen der Umgang mit Daten reguliert ist. Ein Krankenhaus, das ein On-Premise-AI-System zur Analyse von Patientenakten verwendet, muss sich nicht darum sorgen, ob die Datenverarbeitungsvereinbarungen des Anbieters mit den Gesundheitsvorschriften übereinstimmen. Eine Anwaltskanzlei, die Vertragsanalysen lokal durchführt, muss ihren Mandanten nicht offenlegen, dass ihre Dokumente einen Server eines Dritten passiert haben. Die Daten bleiben einfach dort, wo sie hingehören.
Für Unternehmen außerhalb regulierter Branchen ist der Reiz dennoch real. Wettbewerbsinformationen, interne Finanzdaten, Verhaltensmuster von Kunden und Roadmaps zur Produktentwicklung sind allesamt Dinge, die Unternehmen aus guten Gründen lieber innerhalb der eigenen Mauern halten.
Warum sich mehr Unternehmen in diese Richtung bewegen

Das Argument der Datenkontrolle
Cloud-AI-Anbieter sind seriös, aber nicht unsichtbar. Wenn Sie Daten an ein Modell eines Dritten senden, akzeptieren Sie deren Nutzungsbedingungen, deren Sicherheitsstandards und deren politische Entscheidungen darüber, was protokolliert, aufbewahrt oder für die Modellverbesserung verwendet wird. Die meisten Unternehmensvereinbarungen enthalten Opt-outs für Trainingsdaten, aber die zugrunde liegende Abhängigkeit von der Infrastruktur eines anderen bleibt bestehen.
Die On-Premise-Bereitstellung beseitigt diese Abhängigkeit. Ihr Sicherheitsteam legt die Regeln fest. Ihre IT-Infrastruktur kümmert sich um die Zugriffskontrollen. Ihre Compliance-Verantwortlichen können die gesamte Pipeline auditieren, ohne auf die Mitwirkung eines Anbieters warten zu müssen. Für Organisationen, die Datenpannen durch Drittanbieter-Dienste erlebt haben, ist diese Ebene der direkten Kontrolle kein Luxus, sondern eine Anforderung.
Langfristige Kostenvorhersehbarkeit
Die Preisgestaltung bei Cloud-AI ist im kleinen Maßstab attraktiv, wird aber mit zunehmender Nutzung unvorhersehbar. Ein Team, das Hunderttausende Inferenz-Aufrufe pro Monat ausführt, beginnt zu spüren, wie sich die Kosten pro Token in einer Weise stapeln, die in der Pilotphase nicht offensichtlich war. Hardware ist im Vorfeld teuer, aber sie schickt Ihnen keine Rechnung, jedes Mal wenn ein Mitarbeiter der AI eine Frage stellt.
Für Unternehmen mit konstantem, hochvolumigem AI-Einsatz liegt der Break-even-Punkt zwischen Cloud-Kosten und Investitionen in die On-Premise-Infrastruktur oft innerhalb von zwei bis drei Jahren. Danach ist der On-Premise-Aufbau im Betrieb über Wartung und Strom hinaus praktisch kostenlos.
Zu verstehen, wie sich AI-Funktionen auf Hardware-Anforderungen abbilden, hilft Teams, diese Investition genau zu planen, bevor sie sich auf Infrastrukturkäufe festlegen.
Anpassung ohne Grenzen
Cloud-AI-Tools bieten Ihnen Konfigurationsoptionen innerhalb eines definierten Rahmens. On-Premise gibt Ihnen die tatsächlichen Modellgewichte und den vollständigen Stack zur Modifikation, soweit erforderlich. Das bedeutet, dass Sie Modelle auf Ihren proprietären Daten feinabstimmen, das Systemverhalten auf jeder Ebene anpassen, sich tief mit internen Datenbanken und Tools integrieren und die gesamte AI-Umgebung versionsverwalten können, genau wie jede andere interne Software.
Ein Einzelhandelsunternehmen kann beispielsweise ein Sprachmodell auf seinem spezifischen Produktkatalog und seiner Kundendienstgeschichte feinabstimmen, sodass es präzise über sein Inventar spricht, anstatt generische Antworten zu liefern. Diese Stufe der Anpassung ist über eine Standard-Cloud-API schlicht nicht verfügbar.
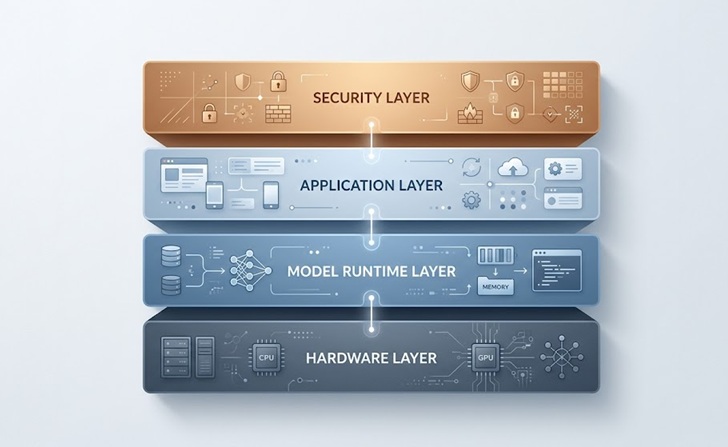
Wie On-Premise-AI-Bereitstellungen typischerweise strukturiert sind
Die Kernarchitektur
Die meisten On-Premise-AI-Setups für Unternehmen teilen ein gemeinsames Muster, unabhängig von den jeweils eingesetzten Tools.
Die Grundlage ist die Hardware-Schicht, die die Server, GPUs und Netzwerkausrüstung umfasst, die das Modell ausführen. Darüber liegt die Modell-Laufzeit, typischerweise ein Orchestrierungstool, das das Laden von Modellen in den Speicher, die Verwaltung von Anfragen und das Bereitstellen eines API-Endpunkts übernimmt, den andere interne Anwendungen aufrufen können.
Die Anwendungsschicht ist der Ort, an dem die eigentlichen Geschäftstools leben, sei es ein Kundenservice-Chatbot, ein interner Wissensdatenbank-Assistent, eine Dokumentenverarbeitungspipeline oder ein Codegenerierungstool für Ihr Engineering-Team. Jede Anwendung verbindet sich über kontrollierte APIs mit der Modell-Laufzeit.
Schließlich umhüllt die Sicherheits- und Zugriffskontrollebene alles, indem sie regelt, wer das Modell abfragen darf, welche Daten ein- und ausfließen und wie Antworten zu Compliance-Zwecken protokolliert werden.
| Bereitstellungsebene | Was sie umfasst | Beispielwerkzeuge |
|---|---|---|
| Hardware | Server, GPUs, Netzwerk | NVIDIA A100, Server-Racks vor Ort |
| Modell-Laufzeit | Inferenz-Engine, Modellverwaltung | Ollama, vLLM, TGI |
| Anwendungsschicht | Geschäftstools, Schnittstellen, Integrationen | Eigene Apps, Open WebUI, interne Portale |
| Sicherheit und Zugriff | Authentifizierung, Protokollierung, Verschlüsselung, Netzwerksteuerung | VPN, LDAP, API gateways |
Diese Architektur von Anfang an richtig hinzubekommen, erspart später erhebliche Mühen. Die Überprüfung bewährter Praktiken der AI-Architektur vor dem Entwurf Ihrer Bereitstellung hilft, häufige strukturelle Fehler zu vermeiden, deren Korrektur teuer wird.
Das richtige Modell für Ihre Geschäftsanforderungen wählen
Die Landschaft der Open-Source-Modelle ist so weit gereift, dass die meisten Geschäftsanwendungsfälle ohne ein proprietäres Modell gut bedient werden. Hier ist eine praktische Aufschlüsselung dessen, was unterschiedliche Modelltypen tendenziell gut bewältigen:
| Geschäftlicher Anwendungsfall | Empfohlene Modellgröße | Hinweise |
|---|---|---|
| FAQ im Kundensupport, einfache Q&A | 7B bis 13B Parameter | Läuft effizient auf GPU-Hardware der Mittelklasse |
| Dokumentenanalyse, Vertragsprüfung | 13B bis 34B Parameter | Profitiert von der Unterstützung längerer Kontextfenster |
| Codegenerierung und technischer Support | 7B bis 13B (codespezifisch) | Modelle wie CodeLlama sind speziell dafür gebaut |
| Komplexes Schlussfolgern und mehrstufige Aufgaben | 34B bis 70B Parameter | Erfordert eine deutlich solidere GPU-Infrastruktur |
| Multimodale Aufgaben einschließlich Bildanalyse | Spezialisierte multimodale Modelle | Hardwareanforderungen variieren erheblich |
Klein anzufangen und basierend auf echten Nutzungsdaten zu skalieren, ist fast immer der klügere Ansatz. Am ersten Tag ein 70B-Modell bereitzustellen, wenn ein 13B-Modell 90 % Ihrer Arbeitslast abgedeckt hätte, ist eine teure Art, diese Lektion zu lernen.
Praktische Überlegungen vor der Bereitstellung
Worauf sich Ihr IT-Team vorbereiten muss
On-Premise-AI ist kein Plug-and-Play-Produkt. Ihr Team wird für Modell-Updates, Sicherheits-Patches, Hardware-Wartung und Performance-Überwachung verantwortlich sein. Für die meisten Unternehmens-IT-Abteilungen sind das beherrschbare Verantwortlichkeiten, aber sie müssen in der Planung berücksichtigt werden.
Ein praktischer Tipp: Behandeln Sie die AI-Bereitstellung wie jeden anderen kritischen internen Dienst. Das bedeutet Redundanzplanung, Backup-Verfahren, Monitoring-Dashboards und einen Eskalationspfad, wenn etwas schiefläuft. Teams, die das Ganze nur als reine Softwareinstallation angehen, stoßen oft zu den schlechtesten möglichen Zeitpunkten auf Probleme.
Sicherheit verdient besondere Aufmerksamkeit. Ein AI-System, das mit internen Datenbanken und Dokumentenspeichern verbunden ist, ist bei Fehlkonfiguration ein hochwertiges Ziel. Die Überprüfung der AI-Sicherheits-Protokolle vor dem Go-Live, einschließlich Netzwerksegmentierung, Authentifizierungsanforderungen und Ausgabe-Logging, ist nicht optional, sondern grundlegend.
Integration mit bestehenden Geschäftssystemen
Der eigentliche Wert von On-Premise-AI für Unternehmen kommt oft nicht vom Assistenten selbst, sondern davon, wie tief er sich in bestehende Systeme integriert. Eine AI, die Ihr CRM abfragen, aus Ihrer internen Wissensdatenbank schöpfen, E-Mails im Kontext lesen und in Ihre Projektmanagement-Tools zurückschreiben kann, ist weitaus nützlicher als eine eigenständige Chat-Oberfläche.
Eine solche Integration ist On-Premise erreichbar und oft einfacher zu bauen, wenn Sie den gesamten Stack kontrollieren. Sie können dem Modell interne APIs zur Verfügung stellen, Retrieval-Augmented-Generation-Pipelines konfigurieren, die Live-Daten aus internen Quellen abrufen, und benutzerdefinierte Tool-Calling-Workflows bauen, die exakt auf die Arbeitsweise Ihres Teams zugeschnitten sind.
Ein gutes Beispiel ist eine professionelle Dienstleistungsfirma, die einen On-Premise-Assistenten bereitgestellt hat, der auf ihrer Dokumentation vergangener Projekte trainiert wurde. Berater können nun Jahre interner Fallstudien, Methodologien und Mandantendaten abfragen, ohne dass auch nur eine dieser Informationen einen Cloud-Dienst berührt. Der Assistent spart Stunden pro Engagement, und die Firma hat die volle Kontrolle darüber, worauf er zugreifen kann und worauf nicht.
Dinge, die Sie wissen sollten
Einige wichtige Details werden im Standard-Pitch für On-Premise-AI oft ausgelassen:
Der initiale Einrichtungszeitplan ist länger, als die meisten Teams erwarten. Eine realistische Unternehmensbereitstellung von der Hardwarebeschaffung bis zum produktionsbereiten Assistenten dauert typischerweise zwischen sechs und zwölf Wochen, je nach Integrationskomplexität.
Die GPU-Verfügbarkeit beeinflusst Ihre Modelloptionen. Nicht alle Open-Source-Modelle laufen effizient auf reiner CPU-Hardware. Wenn Ihre Infrastruktur keine modernen GPU-Karten umfasst, sind Sie möglicherweise auf kleinere, quantisierte Modelle beschränkt, bis die Hardware aufgerüstet ist.
Fine-Tuning erfordert saubere, gut gelabelte Daten. Viele Unternehmen wollen Modelle auf proprietären Daten feinabstimmen, unterschätzen aber, wie viel Vorbereitung diese Daten vorab benötigen. Planen Sie Zeit für die Datenbereinigung ein, bevor Sie Zeit für das Fine-Tuning einplanen.
Modellbestimmungen für die Lizenzierung gelten auch On-Premise. Open Source bedeutet nicht immer uneingeschränkte kommerzielle Nutzung. Prüfen Sie die spezifische Lizenz eines jeden Modells, das Sie in einem Geschäftskontext bereitstellen wollen. LLaMA 3 hat beispielsweise eine angepasste kommerzielle Lizenz mit Bedingungen, die an die Größe der Nutzerbasis gebunden sind.
Der Hersteller-Support ist begrenzt. Anders als bei Cloud-AI-Produkten mit dedizierten Support-Teams stützen sich On-Premise-Open-Source-Bereitstellungen weitgehend auf Community-Dokumentation und internes Know-how. Internes Wissen frühzeitig aufzubauen, reduziert Ihre Abhängigkeit von externen Helpdesks.
Die Inferenzgeschwindigkeit hängt von Ihrer Hardware ab. Cloud-Anbieter betreiben optimierte Cluster mit den neuesten Beschleunigern. Ihre On-Premise-Inferenzgeschwindigkeit ist für große Modelle möglicherweise langsamer, was für Echtzeit-Anwendungen im Kundenkontakt relevant ist. Planen Sie entsprechend.
Die richtige Entscheidung für Ihre Organisation treffen
On-Premise-AI für Unternehmen ist nicht für jede Organisation die richtige Antwort. Wenn Ihr Team klein ist, Ihre Daten nicht besonders sensibel sind und Sie sich schnell bewegen müssen, ist eine gut konfigurierte Cloud-AI-Bereitstellung möglicherweise der bessere Ausgangspunkt. Der operative Aufwand, eine eigene Infrastruktur zu betreiben, hat reale Kosten.
Aber wenn Sie regulierte Daten handhaben, AI in zentrale Geschäftsabläufe integrieren, hohe Nutzungsvolumina prognostizieren oder schlicht nicht bereit sind, die politischen Entscheidungen eines Anbieters Ihre Arbeitsabläufe beeinflussen zu lassen, liefert der On-Premise-Weg etwas, das Cloud-Dienste nicht bieten können: echte Kontrolle. Ihr Modell, Ihre Daten, Ihre Regeln.
Die Werkzeuge, um das umzusetzen, waren nie zugänglicher. Die Open-Source-Community hat die harte Arbeit geleistet, leistungsstarke AI-Modelle so bereitzustellen, dass sie auch von Standard-Engineering-Teams ohne ML-Expertise auf Promotionsniveau betrieben werden können. Was einst ein spezialisiertes AI-Team und ein massives Budget erforderte, ist nun für mittelständische Unternehmen mit einer soliden IT-Funktion und einem klaren Anwendungsfall in Reichweite.
Häufig gestellte Fragen
Kann AI On-Premise bereitgestellt werden?
Ja, AI kann durchaus On-Premise bereitgestellt werden, indem Open-Source-Modelle und selbstverwaltete Inferenz-Infrastruktur auf unternehmenseigener oder privat gemieteter Hardware verwendet werden. Unternehmen in den Bereichen Gesundheitswesen, Finanzen und Recht betreiben bereits produktive AI-Systeme auf diese Weise, um Anforderungen an Compliance und Datenkontrolle zu erfüllen.
Welche AI ist am besten für Unternehmer geeignet?
Die beste AI für einen Unternehmer hängt vom Anwendungsfall ab, aber Open-Source-Modelle wie LLaMA 3 oder Mistral, die auf privater Infrastruktur bereitgestellt werden, bieten die stärkste Kombination aus Kontrolle, Anpassung und langfristiger Kosteneffizienz. Cloud-Tools wie ChatGPT for Business funktionieren gut für leichtere, weniger sensible Anwendungsfälle, bei denen Flexibilität in der Datenhandhabung akzeptabel ist.
Was ist die 30-%-Regel in der AI?
Die 30-%-Regel in der AI bezieht sich auf die allgemeine Faustregel, dass AI-Automatisierung etwa 30 % einer Aufgabe oder eines Workflows übernehmen sollte, während Menschen die verbleibenden 70 %, die Urteilsvermögen und Kontext erfordern, managen. Sie ist ein praktischer Rahmen, um zu erkennen, welche Geschäftsprozesse gute Kandidaten für AI-Unterstützung sind, ohne Entscheidungen zu sehr zu automatisieren, die weiterhin menschliche Aufsicht benötigen.
Was ist On-Premise-AI?
On-Premise-AI ist ein System der künstlichen Intelligenz, das auf Servern oder Hardware bereitgestellt wird, die ein Unternehmen direkt besitzt und kontrolliert, anstatt auf sie über einen Cloud-Anbieter eines Dritten zuzugreifen. Sie hält die gesamte Datenverarbeitung innerhalb der unternehmenseigenen Infrastruktur, was für datenschutzsensible Branchen und Organisationen, die volle Kontrolle über ihren AI-Stack benötigen, entscheidend ist.
Welche sind die 7 Haupttypen der AI?
Die sieben Haupttypen der AI sind schwache AI, allgemeine AI, superintelligente AI, reaktive Maschinen, AI mit begrenztem Gedächtnis, AI mit Theory of Mind und selbstbewusste AI. Die meisten Geschäfts-AI-Tools von heute fallen in die Kategorien schwach und mit begrenztem Gedächtnis und sind zweckgebundene Systeme, die für bestimmte Aufgaben entworfen wurden, anstatt für allgemeines Schlussfolgern oder selbstgesteuertes Denken.