
ビジネス向けオンプレミスAIとは、人工知能システムをクラウドプロバイダー経由でアクセスするのではなく、自社所有のハードウェアまたはプライベートサーバー上に直接展開することを指します。これにより、組織はデータ、AIの動作、および接続先について完全な権限を持つことができます。
ビジネス向けAIに関する議論の多くは、次にどのクラウドツールを契約するかに焦点を当てています。この枠組みは重要な点を見落としています。増加しつつある多くの組織にとって、本当の問いは「どのプラットフォームに料金を払うか」ではなく、「スタック全体を社内に取り込むかどうか」です。その答えは、業界、データの機密性、チームの技術的能力、および長期的なコスト見通しによって異なります。本ガイドではこれらすべてを順を追って説明し、反応的ではなく、情報に基づいた判断を下せるようにします。

ビジネス向けオンプレミスAIの実際の意味
このフレーズは技術的に聞こえますが、概念は単純です。Microsoft Azure OpenAIやGoogle Vertex AIのようなサービスを使用する場合、データは外部サーバーに送信され、処理され、戻ってきます。プロバイダーは、自社側のインフラストラクチャ、モデルの更新、およびパイプラインのセキュリティを管理します。
オンプレミスはこのモデルを完全に逆転させます。AIは貴社が所有または独占的にリースするサーバー上で実行されます。それがオフィス内のラックであれ、コロケーション施設であれ、第三者がアクセスできないプライベートクラウド環境であれ同様です。データが貴社の定める境界線を越えることは一切ありません。
これは、データ取り扱いが規制されている業界において極めて重要です。患者記録の分析にオンプレミスAIシステムを使用する病院は、ベンダーのデータ処理契約が医療規制に準拠しているかどうかを心配する必要がありません。契約分析をローカルで実行する法律事務所は、クライアントの文書が第三者サーバーを経由したことを開示する必要がありません。データは単に本来あるべき場所に留まります。
規制業界外の企業にとっても、その魅力は依然として現実的です。競合インテリジェンス、社内財務データ、顧客行動パターン、製品開発ロードマップなどはいずれも、企業が自社の壁の中に留めておきたいと合理的に考えるものです。
より多くの企業がこの方向に動いている理由

データ制御の論拠
クラウドAIベンダーは評判が高いですが、不可視ではありません。第三者モデルにデータを送信するということは、そのサービス利用規約、セキュリティ体制、そしてログ記録・保持・モデル改善への利用に関するポリシー決定を受け入れることを意味します。ほとんどのエンタープライズ契約にはトレーニングデータからのオプトアウトが含まれていますが、他者のインフラストラクチャに対する根本的な依存関係は残ります。
オンプレミス展開は、その依存関係を取り除きます。貴社のセキュリティチームがルールを設定します。貴社のITインフラがアクセス制御を扱います。貴社のコンプライアンス担当者は、ベンダーの協力を待つことなくパイプライン全体を監査できます。第三者サービスを通じてデータ侵害を経験したことのある組織にとって、そのレベルの直接制御は贅沢ではなく、要件です。
長期的なコストの予測可能性
クラウドAIの価格設定は小規模では魅力的ですが、使用量が増えるにつれて予測不可能になります。月に数十万件の推論呼び出しを実行するチームは、パイロット段階では明らかではなかった形で、トークン単位のコストが積み重なっていくのを感じ始めます。ハードウェアは初期投資が高額ですが、従業員がAIに質問するたびに請求書が送られてくることはありません。
一貫した大量のAI使用がある企業にとって、クラウドコストとオンプレミスインフラ投資の損益分岐点は多くの場合2〜3年以内に到達します。それ以降、オンプレミスのセットアップは保守と電力以外、事実上無料で運用できます。
AI機能がハードウェア要件にどのようにマッピングされるかを理解することで、チームはインフラ購入を確定する前にその投資を正確に計画できます。
制限のないカスタマイズ
クラウドAIツールは、定義された境界内での設定オプションを提供します。オンプレミスは、実際のモデルウェイトと、必要に応じて変更できるフルスタックを提供します。これは、独自データでモデルをファインチューニングしたり、あらゆる層でシステムの動作を調整したり、社内データベースやツールと深く統合したり、他の社内ソフトウェアと同じ方法でAI環境全体をバージョン管理したりできることを意味します。
例えば小売企業は、language modelを自社固有の製品カタログと顧客サービス履歴でファインチューニングすることで、汎用的な回答を生成するのではなく、自社の在庫について正確に話せるようになります。そのレベルのカスタマイズは、標準のクラウドAPIでは単純に利用できません。
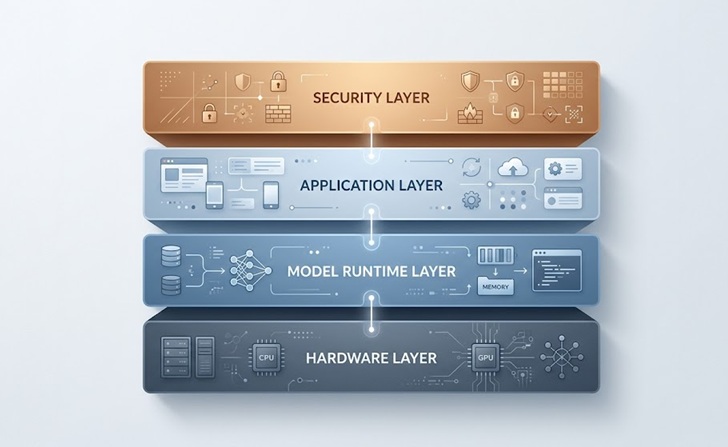
オンプレミスAI展開の一般的な構造
コアアーキテクチャ
ビジネス向けのほとんどのオンプレミスAIセットアップは、関与する特定のツールに関係なく共通のパターンを共有しています。
基盤はハードウェア層であり、モデルを実行するサーバー、GPU、ネットワーク機器を含みます。その上にモデルランタイムがあり、通常はモデルをメモリに読み込み、リクエストを管理し、他の社内アプリケーションが呼び出せるAPIエンドポイントを公開するオーケストレーションツールです。
アプリケーション層は、実際のビジネスツールが存在する場所であり、顧客サービスチャットボット、社内ナレッジベースアシスタント、文書処理パイプライン、またはエンジニアリングチーム向けのコード生成ツールなどが含まれます。各アプリケーションは制御されたAPIを通じてモデルランタイムに接続します。
最後に、セキュリティおよびアクセス制御層が全体を包み込み、誰がモデルにクエリできるか、どのデータが入出力されるか、コンプライアンス目的のためにレスポンスがどのように記録されるかを管理します。
| 展開層 | 含まれるもの | ツールの例 |
|---|---|---|
| ハードウェア | サーバー、GPU、ネットワーク | NVIDIA A100、オンサイトのサーバーラック |
| モデルランタイム | 推論エンジン、モデル管理 | Ollama、vLLM、TGI |
| アプリケーション層 | ビジネスツール、インターフェース、統合 | カスタムアプリ、Open WebUI、社内ポータル |
| セキュリティとアクセス | 認証、ログ記録、暗号化、ネットワーク制御 | VPN、LDAP、APIゲートウェイ |
このアーキテクチャを最初から正しく構築することで、後のかなりの苦労を回避できます。展開を設計する前にAIアーキテクチャのベストプラクティスを確認することで、修正に高額な費用がかかる一般的な構造上のミスを避けることができます。
貴社のビジネスニーズに合ったモデルの選択
オープンソースモデルの状況は成熟しており、ほとんどのビジネスユースケースは独自モデルなしで十分対応できる段階に達しています。以下は、さまざまなモデルタイプが得意とする内容の実用的な分類です。
| ビジネスユースケース | 推奨モデルサイズ | 備考 |
|---|---|---|
| カスタマーサポートFAQ、基本的なQ&A | 7Bから13Bパラメータ | 中位帯GPUハードウェア上で効率的に動作 |
| 文書分析、契約レビュー | 13Bから34Bパラメータ | 長いコンテキストウィンドウのサポートが有効 |
| コード生成と技術サポート | 7Bから13B(コード特化) | CodeLlamaのようなモデルはこの用途専用に設計 |
| 複雑な推論と多段階タスク | 34Bから70Bパラメータ | より充実したGPUインフラが必要 |
| 画像分析を含むマルチモーダルタスク | 専門のマルチモーダルモデル | ハードウェア要件は大きく異なる |
小さく始めて実際の使用データに基づいてスケールアップすることは、ほぼ常により賢明なアプローチです。13Bでワークロードの90%をカバーできたはずなのに初日に70Bモデルを展開するのは、その教訓を学ぶ高価な方法です。
展開前の実用的な考慮事項
貴社のITチームが準備すべきこと
オンプレミスAIはプラグアンドプレイ製品ではありません。貴社のチームは、モデルの更新、セキュリティパッチ適用、ハードウェア保守、およびパフォーマンス監視を担当することになります。これらはほとんどのエンタープライズIT部門にとって管理可能な責任ですが、計画段階で考慮する必要があります。
実用的なアドバイスを一つ。AI展開を他の重要な社内サービスと同様に扱ってください。これは、冗長性計画、バックアップ手順、監視ダッシュボード、および問題発生時のエスカレーションパスを意味します。単なるソフトウェアインストールとしてアプローチするチームは、最悪のタイミングで問題に直面することがよくあります。
セキュリティは特別な注意に値します。社内データベースと文書ストレージに接続されたAIシステムは、誤って設定されると価値の高い標的になります。本番稼働前にAIセキュリティプロトコル(ネットワークセグメンテーション、認証要件、出力ログ記録を含む)を確認することは、オプションではなく、基礎的なものです。
既存のビジネスシステムとの統合
ビジネス向けオンプレミスAIの真の価値は、多くの場合アシスタント自体からではなく、既存システムとの深い接続性から生まれます。CRMにクエリでき、社内ナレッジベースから情報を取得でき、コンテキスト内でメールを読み、プロジェクト管理ツールに書き戻せるAIは、スタンドアロンのチャットインターフェースよりはるかに有用です。
この種の統合はオンプレミスで実現可能であり、フルスタックを制御する場合はしばしば構築が容易です。社内APIをモデルに公開したり、社内ソースからライブデータを取得するretrieval-augmented generationパイプラインを構成したり、チームの運営方法に正確に合わせたカスタムのtool-callingワークフローを構築したりできます。
良い例として、過去のプロジェクト文書でトレーニングしたオンプレミスアシスタントを展開したプロフェッショナルサービス企業があります。コンサルタントは現在、その情報のいずれもクラウドサービスに触れることなく、何年にもわたる社内のケーススタディ、方法論、クライアントデータをクエリできます。アシスタントは案件ごとに数時間を節約し、企業はアクセス可能・不可能な対象を完全に制御しています。
知っておくべきこと
オンプレミスAIの標準的な提案からしばしば省略される重要な詳細がいくつかあります。
初期セットアップのタイムラインは、ほとんどのチームが予想するよりも長いです。ハードウェア調達から本番稼働可能なアシスタントまでの現実的なエンタープライズ展開は、統合の複雑さに応じて通常6〜12週間かかります。
GPUの可用性はモデルの選択肢に影響します。すべてのオープンソースモデルがCPUのみのハードウェアで効率的に動作するわけではありません。インフラストラクチャに最新のGPUカードが含まれていない場合、ハードウェアがアップグレードされるまで、より小さな量子化モデルに制限される可能性があります。
ファインチューニングには、クリーンで適切にラベル付けされたデータが必要です。多くの企業は独自データでモデルをファインチューニングしたいと考えていますが、そのデータが事前にどれだけの準備を必要とするかを過小評価しています。ファインチューニングのための時間を予算化する前に、データクレンジングのための時間を予算化してください。
モデルライセンスはオンプレミスでも適用されます。オープンソースは必ずしも無制限の商用利用を意味しません。ビジネスコンテキストで展開する予定のあらゆるモデルについて、特定のライセンスを確認してください。例えばLLaMA 3には、ユーザーベースの規模に関連する条件を持つカスタム商用ライセンスがあります。
ベンダーサポートは限定的です。専任のサポートチームを持つクラウドAI製品とは異なり、オンプレミスのオープンソース展開は主にコミュニティドキュメントと社内の専門知識に依存します。早期に社内ナレッジを構築することで、外部ヘルプデスクへの依存を減らせます。
推論速度はハードウェアによって異なります。クラウドプロバイダーは、最新のアクセラレータを備えた最適化されたクラスタを運用しています。オンプレミスの推論速度は大規模モデルでは遅くなる可能性があり、これはリアルタイムのユーザー向けアプリケーションにとって重要です。それに応じて計画してください。
貴社の組織にとって正しい判断を下す
ビジネス向けオンプレミスAIは、すべての組織にとって正しい答えではありません。チームが小規模で、データが特に機密ではなく、迅速に動く必要がある場合、適切に構成されたクラウドAI展開がより良い出発点となる可能性があります。自社インフラストラクチャを運用する運用上のオーバーヘッドには、実際のコストがあります。
しかし、規制データを取り扱っている場合、AIをコアビジネス運用に組み込んでいる場合、高い使用量を見込んでいる場合、または単にベンダーのポリシー決定がワークフローに影響するのを許容したくない場合、オンプレミスの道筋はクラウドサービスでは実現できないものを提供します。それは本物の制御です。貴社のモデル、貴社のデータ、貴社のルール。
それを実現するためのツールは、これまでになくアクセスしやすくなっています。オープンソースコミュニティは、博士レベルのML専門知識なしに標準的なエンジニアリングチームが強力なAIモデルを展開可能にするという困難な作業を成し遂げてきました。かつて専門のAIチームと巨額の予算を必要としたものは、堅実なIT機能と明確なユースケースを持つ中規模企業の手の届く範囲になりました。
よくある質問
AIはオンプレミスで展開できますか?
はい、AIはオープンソースモデルと、自社所有または個別にリースされたハードウェア上で自己管理する推論インフラを使用することで、絶対にオンプレミスで展開できます。 医療、金融、法律業界の企業はすでに、コンプライアンスおよびデータ制御要件を満たすためにこの方法で本番AIシステムを運用しています。
ビジネスオーナーにとって最適なAIはどれですか?
ビジネスオーナーにとって最適なAIはユースケースによって異なりますが、プライベートインフラ上に展開されたLLaMA 3やMistralなどのオープンソースモデルは、制御、カスタマイズ、長期的なコスト効率の最も強力な組み合わせを提供します。 ChatGPT for Businessのようなクラウドツールは、データ取り扱いの柔軟性が許容される、より軽量で機密性の低いユースケースで適切に機能します。
AIにおける30%ルールとは何ですか?
AIにおける30%ルールとは、AIの自動化がタスクまたはワークフローの約30%を処理し、判断とコンテキストを必要とする残りの70%を人間が管理するべきという一般的なガイドラインを指します。 これは、依然として人間の監視が必要な決定を過剰に自動化することなく、どのビジネスプロセスがAI支援に適した候補であるかを特定するための実用的なフレームワークです。
オンプレミスAIとは何ですか?
オンプレミスAIとは、第三者のクラウドプロバイダーを通じてアクセスするのではなく、企業が直接所有・制御するサーバーまたはハードウェア上に展開された人工知能システムです。 すべてのデータ処理を自社のインフラストラクチャ内に保持し、これはプライバシーに敏感な業界およびAIスタックの完全な制御を必要とする組織にとって極めて重要です。
AIの主な7つのタイプは何ですか?
AIの主な7つのタイプは、特化型AI、汎用AI、超知能AI、反応機械、限定記憶AI、心の理論AI、自己認識AIです。 今日のほとんどのビジネスAIツールは、特化型および限定記憶のカテゴリーに分類され、これらは汎用的な推論や自己指向的思考ではなく、特定のタスクを処理するために特別に構築されたシステムです。