
La AI local para empresas se refiere a desplegar sistemas de inteligencia artificial directamente en hardware propiedad de la empresa o en servidores privados, en lugar de acceder a ellos a través de un proveedor en la nube. Otorga a las organizaciones autoridad completa sobre sus datos, cómo se comporta la AI y a qué se conecta.
La mayoría de las conversaciones sobre AI para empresas se centran en a qué herramienta en la nube suscribirse a continuación. Ese enfoque pasa por alto algo importante. Para un número creciente de organizaciones, la verdadera pregunta no es a qué plataforma pagar, sino si conviene traer todo el stack a casa. La respuesta depende de vuestro sector, de la sensibilidad de vuestros datos, de la capacidad técnica de vuestro equipo y de vuestras expectativas de coste a largo plazo. Esta guía repasa todo eso para que podáis tomar una decisión informada y no reactiva.

Qué significa realmente la AI local para empresas
La frase suena técnica, pero el concepto es sencillo. Cuando usáis un servicio como Microsoft Azure OpenAI o Google Vertex AI, vuestros datos viajan a servidores externos, se procesan y vuelven. El proveedor gestiona la infraestructura, las actualizaciones del modelo y la seguridad de su lado del flujo.
La AI local invierte ese modelo por completo. La AI se ejecuta en servidores que vuestra empresa posee o alquila en exclusiva, ya sea un rack en vuestra oficina, una instalación de colocation o un entorno de nube privada al que ningún tercero pueda acceder. Vuestros datos nunca abandonan el perímetro que vosotros definís.
Esto importa enormemente en sectores donde la gestión de datos está regulada. Un hospital que usa un sistema de AI local para analizar registros de pacientes no tiene que preocuparse por si los acuerdos de procesamiento de datos del proveedor cumplen con las regulaciones sanitarias. Un despacho de abogados que ejecuta análisis de contratos en local no necesita revelar a sus clientes que sus documentos han pasado por un servidor de terceros. Los datos simplemente permanecen donde corresponden.
Para las empresas fuera de sectores regulados, el atractivo sigue siendo real. La inteligencia competitiva, los datos financieros internos, los patrones de comportamiento de los clientes y las hojas de ruta de desarrollo de productos son cosas que las empresas razonablemente prefieren mantener dentro de sus propias paredes.
Por qué más empresas se están moviendo en esta dirección

El argumento del control de datos
Los proveedores de AI en la nube son reconocidos, pero no son invisibles. Cuando enviáis datos a un modelo de terceros, estáis aceptando sus términos de servicio, su postura de seguridad y sus decisiones políticas sobre qué se registra, retiene o usa para mejorar el modelo. La mayoría de los acuerdos empresariales incluyen exclusiones para datos de entrenamiento, pero la dependencia subyacente de la infraestructura de otra persona permanece.
El despliegue en local elimina esa dependencia. Vuestro equipo de seguridad establece las reglas. Vuestra infraestructura de TI maneja los controles de acceso. Vuestros responsables de cumplimiento pueden auditar todo el pipeline sin esperar la cooperación de un proveedor. Para las organizaciones que han sufrido brechas de datos a través de servicios de terceros, ese nivel de control directo no es un lujo, es un requisito.
Previsibilidad del coste a largo plazo
El precio de la AI en la nube es atractivo a pequeña escala pero se vuelve impredecible a medida que el uso crece. Un equipo que realiza cientos de miles de llamadas de inferencia al mes empieza a sentir cómo se acumulan los costes por token de maneras que no eran obvias durante la fase piloto. El hardware es caro al principio, pero no os envía una factura cada vez que un empleado le hace una pregunta a la AI.
Para empresas con uso de AI consistente y de alto volumen, el punto de equilibrio entre los costes de la nube y la inversión en infraestructura local suele situarse entre dos y tres años. Después de eso, la configuración local es efectivamente gratuita de operar más allá del mantenimiento y la electricidad.
Comprender cómo se mapean las funciones de AI a los requisitos de hardware ayuda a los equipos a planificar esa inversión con precisión antes de comprometerse con compras de infraestructura.
Personalización sin límites
Las herramientas de AI en la nube os dan opciones de configuración dentro de un límite definido. La AI local os entrega los pesos reales del modelo y todo el stack para modificarlo según sea necesario. Eso significa que podéis afinar modelos con vuestros datos propietarios, ajustar el comportamiento del sistema en cada capa, integrar profundamente con bases de datos y herramientas internas, y versionar todo el entorno de AI igual que cualquier otro software interno.
Una empresa de retail, por ejemplo, puede afinar un modelo de lenguaje con su catálogo de productos específico y su historial de atención al cliente para que hable con precisión sobre su inventario en lugar de producir respuestas genéricas. Ese nivel de personalización simplemente no está disponible a través de una API en la nube estándar.
Cómo se estructuran típicamente los despliegues de AI local
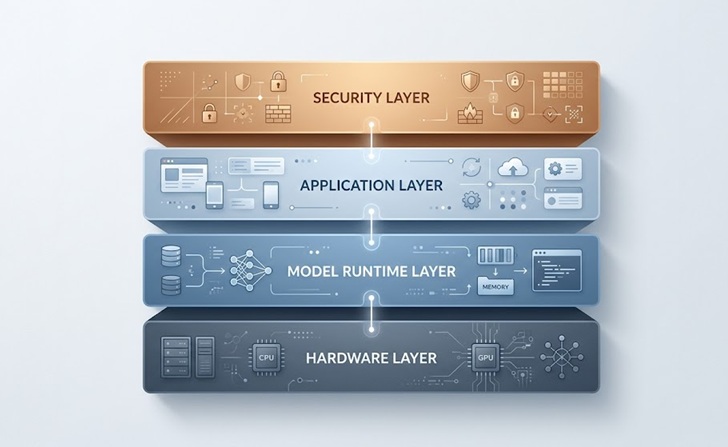
La arquitectura central
La mayoría de las configuraciones de AI local para empresas comparten un patrón común independientemente de las herramientas específicas implicadas.
La base es la capa de hardware, que incluye los servidores, las GPU y el equipo de red que ejecuta el modelo. Encima de eso se sitúa el runtime del modelo, normalmente una herramienta de orquestación que se encarga de cargar modelos en memoria, gestionar peticiones y exponer un endpoint de API que otras aplicaciones internas pueden llamar.
La capa de aplicación es donde viven las herramientas empresariales reales, ya sea un chatbot de atención al cliente, un asistente de base de conocimiento interna, un pipeline de procesamiento de documentos o una herramienta de generación de código para vuestro equipo de ingeniería. Cada aplicación se conecta al runtime del modelo a través de APIs controladas.
Por último, la capa de seguridad y control de acceso envuelve todo, gestionando quién puede consultar el modelo, qué datos entran y salen, y cómo se registran las respuestas para fines de cumplimiento.
| Capa de despliegue | Qué incluye | Herramientas de ejemplo |
|---|---|---|
| Hardware | Servidores, GPU, red | NVIDIA A100, racks de servidores in situ |
| Runtime del modelo | Motor de inferencia, gestión de modelos | Ollama, vLLM, TGI |
| Capa de aplicación | Herramientas empresariales, interfaces, integraciones | Apps personalizadas, Open WebUI, portales internos |
| Seguridad y acceso | Autenticación, registro, cifrado, controles de red | VPN, LDAP, API gateways |
Acertar con esta arquitectura desde el principio ahorra una cantidad significativa de dolor después. Revisar las mejores prácticas de arquitectura de AI antes de diseñar vuestro despliegue ayuda a evitar errores estructurales comunes que se vuelven caros de corregir.
Elegir el modelo adecuado para las necesidades de vuestra empresa
El panorama de los modelos de código abierto ha madurado hasta el punto en que la mayoría de los casos de uso empresariales están bien servidos sin un modelo propietario. Aquí tenéis un desglose práctico de lo que diferentes tipos de modelos suelen manejar bien:
| Caso de uso empresarial | Tamaño de modelo recomendado | Notas |
|---|---|---|
| FAQ de soporte al cliente, Q&A básico | 7B a 13B parámetros | Funciona eficientemente en hardware GPU de gama media |
| Análisis de documentos, revisión de contratos | 13B a 34B parámetros | Se beneficia del soporte de ventanas de contexto más largas |
| Generación de código y soporte técnico | 7B a 13B (específicos para código) | Modelos como CodeLlama están diseñados para esto |
| Razonamiento complejo y tareas multipaso | 34B a 70B parámetros | Requiere infraestructura GPU más robusta |
| Tareas multimodales incluyendo análisis de imágenes | Modelos multimodales especializados | Los requisitos de hardware varían significativamente |
Empezar más pequeño y escalar en función de datos reales de uso es casi siempre el enfoque más inteligente. Desplegar un modelo de 70B desde el primer día cuando uno de 13B habría cubierto el 90% de vuestra carga de trabajo es una manera cara de aprender esa lección.
Consideraciones prácticas antes de desplegar
Para qué necesita prepararse vuestro equipo de TI
La AI local no es un producto plug-and-play. Vuestro equipo será responsable de las actualizaciones del modelo, el parcheo de seguridad, el mantenimiento del hardware y la monitorización del rendimiento. Estas son responsabilidades manejables para la mayoría de los departamentos de TI empresariales, pero deben tenerse en cuenta en la planificación.
Un consejo práctico: tratad el despliegue de AI como cualquier otro servicio interno crítico. Eso significa planificación de redundancia, procedimientos de copia de seguridad, paneles de monitorización y una ruta de escalado cuando algo sale mal. Los equipos que lo abordan como una simple instalación de software a menudo se topan con problemas en los peores momentos.
La seguridad merece atención específica. Un sistema de AI conectado a bases de datos internas y almacenamiento de documentos es un objetivo de alto valor si está mal configurado. Revisar los protocolos de seguridad de AI antes de la puesta en marcha, incluyendo segmentación de red, requisitos de autenticación y registro de salida, no es opcional, es fundamental.
Integración con sistemas empresariales existentes
El valor real de la AI local para empresas a menudo no proviene del asistente en sí, sino de cuán profundamente se conecta a los sistemas existentes. Una AI que puede consultar vuestro CRM, extraer datos de vuestra base de conocimiento interna, leer correos electrónicos en contexto y escribir de vuelta en vuestras herramientas de gestión de proyectos es mucho más útil que una interfaz de chat independiente.
Este tipo de integración es alcanzable en local y a menudo es más fácil de construir cuando controláis todo el stack. Podéis exponer APIs internas al modelo, configurar pipelines de generación aumentada por recuperación que extraigan datos en vivo de fuentes internas y construir flujos de trabajo de llamadas a herramientas personalizadas exactamente a la medida de cómo trabaja vuestro equipo.
Un buen ejemplo es una firma de servicios profesionales que desplegó un asistente local entrenado en su documentación de proyectos pasados. Los consultores ahora pueden consultar años de casos de estudio internos, metodologías y datos de clientes sin que ninguna de esa información toque un servicio en la nube. El asistente ahorra horas por encargo y la firma tiene control total sobre a qué puede acceder y a qué no.
Cosas que conviene saber
Algunos detalles importantes a menudo se omiten en el discurso estándar sobre la AI local:
El calendario de configuración inicial es más largo de lo que la mayoría de los equipos esperan. Un despliegue empresarial realista, desde la adquisición del hardware hasta un asistente listo para producción, típicamente lleva entre seis y doce semanas, dependiendo de la complejidad de la integración.
La disponibilidad de GPU afecta vuestras opciones de modelo. No todos los modelos de código abierto funcionan eficientemente en hardware solo con CPU. Si vuestra infraestructura no incluye tarjetas GPU modernas, podríais estar limitados a modelos más pequeños y cuantizados hasta que se actualice el hardware.
El fine-tuning requiere datos limpios y bien etiquetados. Muchas empresas quieren afinar modelos con datos propietarios pero subestiman cuánta preparación necesitan esos datos de antemano. Presupuestad tiempo para limpieza de datos antes de presupuestar tiempo para fine-tuning.
Las licencias de modelos siguen aplicándose en local. Código abierto no siempre significa uso comercial sin restricciones. Comprobad la licencia específica de cualquier modelo que planeéis desplegar en un contexto empresarial. LLaMA 3, por ejemplo, tiene una licencia comercial personalizada con condiciones ligadas al tamaño de la base de usuarios.
El soporte del proveedor es limitado. A diferencia de los productos de AI en la nube con equipos de soporte dedicados, los despliegues locales de código abierto dependen en gran medida de la documentación de la comunidad y la experiencia interna. Construir conocimiento interno pronto reduce vuestra dependencia de mesas de ayuda externas.
La velocidad de inferencia depende de vuestro hardware. Los proveedores en la nube ejecutan clústeres optimizados con los aceleradores más recientes. Vuestra velocidad de inferencia local puede ser más lenta para modelos grandes, lo cual importa para aplicaciones en tiempo real orientadas al usuario. Planificad en consecuencia.
Tomar la decisión correcta para vuestra organización
La AI local para empresas no es la respuesta correcta para toda organización. Si vuestro equipo es pequeño, vuestros datos no son particularmente sensibles y necesitáis moveros rápido, un despliegue bien configurado de AI en la nube podría ser el mejor punto de partida. La sobrecarga operativa de manejar vuestra propia infraestructura tiene un coste real.
Pero si manejáis datos regulados, integráis AI en operaciones empresariales centrales, proyectáis volúmenes altos de uso o sencillamente no estáis dispuestos a dejar que las decisiones políticas de un proveedor afecten vuestros flujos de trabajo, el camino local entrega algo que los servicios en la nube no pueden igualar: control genuino. Vuestro modelo, vuestros datos, vuestras reglas.
Las herramientas para conseguirlo nunca han sido más accesibles. La comunidad de código abierto ha hecho el trabajo duro de hacer que modelos de AI potentes sean desplegables por equipos de ingeniería estándar sin necesitar experiencia en ML a nivel de doctorado. Lo que antes requería un equipo de AI especializado y un presupuesto enorme ahora está al alcance de empresas medianas con una función de TI sólida y un caso de uso claro.
Preguntas frecuentes
¿La AI se puede desplegar en local?
Sí, la AI se puede desplegar absolutamente en local usando modelos de código abierto e infraestructura de inferencia autogestionada en hardware propiedad de la empresa o alquilado en privado. Empresas en sectores sanitario, financiero y legal ya ejecutan sistemas de AI en producción de esta manera para cumplir con los requisitos de cumplimiento y control de datos.
¿Qué AI es la mejor para dueños de empresas?
La mejor AI para un dueño de empresa depende del caso de uso, pero los modelos de código abierto como LLaMA 3 o Mistral desplegados en infraestructura privada ofrecen la combinación más fuerte de control, personalización y eficiencia de coste a largo plazo. Herramientas en la nube como ChatGPT for Business funcionan bien para casos de uso más ligeros y menos sensibles donde la flexibilidad en la gestión de datos es aceptable.
¿Qué es la regla del 30% en AI?
La regla del 30% en AI se refiere a la directriz general de que la automatización con AI debería manejar aproximadamente el 30% de una tarea o flujo de trabajo, con los humanos gestionando el 70% restante que requiere juicio y contexto. Es un marco práctico para identificar qué procesos empresariales son buenos candidatos para asistencia de AI sin sobreautomatizar decisiones que todavía necesitan supervisión humana.
¿Qué es la AI local?
La AI local es un sistema de inteligencia artificial desplegado en servidores o hardware que una empresa posee y controla directamente, en lugar de acceder a través de un proveedor en la nube de terceros. Mantiene todo el procesamiento de datos dentro de la propia infraestructura de la empresa, lo cual es crítico para sectores sensibles a la privacidad y organizaciones que necesitan control total sobre su stack de AI.
¿Cuáles son los 7 tipos principales de AI?
Los siete tipos principales de AI son AI estrecha, AI general, AI superinteligente, máquinas reactivas, AI de memoria limitada, AI de teoría de la mente y AI autoconsciente. La mayoría de las herramientas de AI empresariales hoy caen en las categorías estrecha y de memoria limitada, que son sistemas diseñados para manejar tareas específicas en lugar de razonamiento general o pensamiento autodirigido.