
Privacyrisico's van AI-gegevens zijn directer en persoonlijker dan de meeste mensen beseffen, en omvatten alles van de prompts die u typt tot de bestanden die u uploadt, waarvan allemaal kunnen worden opgeslagen, geanalyseerd en in sommige gevallen worden gebruikt om het model te trainen waarmee u spreekt. Als u regelmatig AI-tools gebruikt zonder veel na te denken over wat er gebeurt met de informatie die u deelt, is deze gids het lezen waard voor uw volgende sessie.
Het gesprek rondom AI en privacy schiet vaak heen en weer tussen twee uitersten. Mensen wuiven de zorg ofwel volledig weg omdat er nog niets ergs is gebeurd, ofwel raken ze in een mate van alarm die de technologie onbruikbaar doet klinken. Geen van beide reacties is behulpzaam. Wat u werkelijk dient, is een helder, geaard begrip van waar de echte risico's liggen, wat u kunt doen om ze te verminderen en welke gewoonten u kunt opbouwen voordat er iets misgaat in plaats van erna. Dat is precies wat deze gids levert.
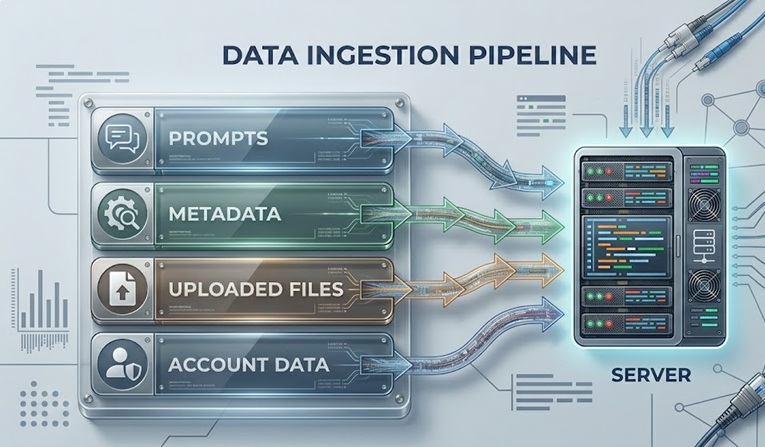
Waar privacyrisico's van AI-gegevens daadwerkelijk vandaan komen
Om het risico te begrijpen, moet u de pijplijn begrijpen. Wanneer u iets in een AI-tool typt, reist die invoer van uw apparaat naar een externe server waar het model draait. Het wordt verwerkt, er wordt een antwoord gegenereerd, en afhankelijk van het platform en uw instellingen, kan dat gesprek worden gelogd, opgeslagen, beoordeeld door menselijke trainers en gebruikt om toekomstige modelversies te verbeteren.
Die keten klinkt eenvoudig, maar elke stap erin vertegenwoordigt een potentieel blootstellingspunt. De gegevens verlaten uw apparaat. Ze staan op andermans servers. Ze kunnen maandenlang of langer worden bewaard. Ze kunnen worden gezien door mensen buiten het AI-model zelf. En als het bedrijf dat het platform exploiteert een inbreuk ondervindt, maken uw gegevens deel uit van wat wordt blootgesteld.
Dit is geen hypothetische zorg. In 2023 bevestigde OpenAI een bug die sommige gebruikers tijdelijk in staat stelde titels te zien van chatgeschiedenissen van andere gebruikers. Werknemers van Samsung haalden de krantenkoppen nadat interne broncode en vergadernotities in ChatGPT waren geplakt en vervolgens op de servers van OpenAI werden opgeslagen. Deze incidenten maakten de technologie niet onbruikbaar, maar maakten wel duidelijk dat privacyrisico's van AI-gegevens geen theoretische randgevallen zijn. Het zijn gebeurtenissen die echte organisaties overkomen wanneer er geen waarborgen zijn.
Het risicobeeld valt uiteen in drie hoofdcategorieën. Wat wordt verzameld, hoe het wordt gebruikt en wie er toegang toe heeft. Alle drie begrijpen is wat geïnformeerde gebruikers onderscheidt van blootgestelde gebruikers.
Wat AI-tools verzamelen en waarom dit van belang is
De meeste mensen denken bij hun AI-interacties aan gesprekken die verdwijnen nadat de sessie eindigt. In werkelijkheid is de gegevenslevenscyclus voor de meeste consumenten-AI-tools aanzienlijk langer en complexer dan dat.
Promptgegevens. Alles wat u in een AI-tool typt, wordt op zijn minst verzameld om uw antwoord te genereren. Daarbuiten, afhankelijk van platforminstellingen, kan het worden bewaard voor veiligheidscontrole, kwaliteitsverbetering en modeltraining. De standaard op de meeste consumentenplatforms is bewaren en mogelijk gebruik voor training, tenzij u zich actief afmeldt.
Gebruiksmetadata. Naast de inhoud van uw prompts verzamelen platforms doorgaans informatie over hoe u de tool gebruikt, sessietiming, frequentie, apparaattype, locatiegegevens en patronen in functiegebruik. Deze metadata bouwen een gedragsprofiel op, zelfs wanneer de inhoud zelf onschuldig lijkt.
Geüploade bestanden en documenten. Veel AI-tools accepteren tegenwoordig bestandsuploads, afbeeldingen, spreadsheets en pdf's. Inhoud uit deze uploads komt in dezelfde gegevenspijplijn terecht als getypte prompts en draagt dezelfde bewaar- en gebruiksoverwegingen, vaak met gebruikers die ten onrechte aannemen dat geüploade bestanden anders worden behandeld.
Account- en identiteitsgegevens. Uw e-mailadres, betalingsinformatie, organisatiegegevens en alle profielgegevens die u verstrekt, bevinden zich in hetzelfde systeem als uw gespreksgegevens en zijn onderhevig aan hetzelfde inbreukrisico als elke andere online account.
De reden dat dit van belang is, is niet dat AI-bedrijven kwaadwillig handelen. De meeste doen dat niet. De reden dat het van belang is, is dat bewaarde gegevens gegevens in risico zijn, en hoe gevoeliger de informatie die u deelt, hoe ingrijpender de gevolgen als dat risico zich materialiseert.
Dingen die u nooit met een AI-tool zou moeten delen
Dit is het gedeelte dat de meeste mensen het meest nodig hebben en het minst zorgvuldig lezen. Specifiek zijn over wat u uit AI-tools moet houden, is nuttiger dan algemene waarschuwingen om voorzichtig te zijn.
Wachtwoorden en authenticatiegegevens. Dit zou voor de hand moeten liggen, maar het komt vaker voor dan u zou verwachten, met name wanneer mensen AI-tools vragen om te helpen bij het debuggen van inlogsystemen of het oplossen van problemen met accounttoegang. Neem nooit echte inloggegevens op in welke prompt dan ook, ongeacht hoe veilig het platform beweert te zijn.
Burgerservicenummers, fiscale identificaties en overheidsidentificatoren. Dit zijn de bouwstenen van identiteitsdiefstal en horen nergens in de buurt van een AI-systeem van een derde partij.
Persoonlijke gegevens van klanten en cliënten. Namen, e-mailadressen, telefoonnummers, financiële gegevens, gezondheidsinformatie en alle andere persoonlijk identificeerbare informatie die toebehoort aan anderen dan uzelf, brengt juridische en ethische verplichtingen met zich mee over hoe deze gedeeld mag worden. Een klantenlijst in een chatvenster plakken schendt deze verplichtingen vrijwel zeker.
Bedrijfsgevoelige informatie. Interne prijsstrategie, niet-uitgebrachte productdetails, fusie- en overnamebesprekingen, juridische strategie en concurrentie-intelligence zijn het soort informatie waar bedrijven aanzienlijke middelen aan besteden om te beschermen. Deze via een consumenten-AI-tool versturen omzeilt die bescherming onmiddellijk.
Medische en gezondheidsinformatie. Uw eigen gezondheidsgegevens of die van iemand anders horen in dezelfde beschermde categorie als klantgegevens. De gevoeligheid is hoog en de regelgevingskaders rond gezondheidsinformatie in veel jurisdicties zijn streng.
Financiële accountgegevens. Bankrekeningnummers, kaartgegevens, beleggingsposities en soortgelijke informatie moeten geheel buiten AI-workflows blijven, ongeacht de taak.
De beveiligingsarchitectuur van uw AI-tools is hier van belang, omdat zelfs met de beste persoonlijke gewoonten het platform dat u gebruikt zijn deel van de beschermingsvergelijking moet ophouden opdat uw gegevens werkelijk veilig blijven.

Hoe veilig zijn uw gegevens werkelijk bij AI?
Een eerlijk antwoord geven op deze vraag betekent erkennen dat dit aanzienlijk varieert afhankelijk van het platform, het abonnementsniveau en uw eigen praktijken. Het is geen eenvoudige ja of nee.
| Platformtype | Gegevens gebruikt voor training | Versleuteling | Menselijke beoordeling mogelijk | Inbreukrisico |
|---|---|---|---|---|
| Gratis consumenten-AI | Standaard ja | Basis | Ja | Aanwezig |
| Betaalde consumenten-AI | Vaak afmelden mogelijk | Standaard | Verminderd | Aanwezig |
| Zakelijke AI-abonnementen | Nee, doorgaans contractueel | Geavanceerd | Nee, doorgaans contractueel | Lager, maar niet nul |
| Zelf-gehoste AI-modellen | Nee, blijft op uw servers | Uw verantwoordelijkheid | Nee | Laagst |
De zakelijke en zelf-gehoste niveaus vertegenwoordigen betekenisvol betere gegevensbescherming dan consumentenproducten, maar ze brengen hogere kosten en een grotere installatiecomplexiteit met zich mee. Voor de meeste individuen die AI gebruiken voor persoonlijke productiviteit, is het consumentenproduct met afmelding voor trainingsgegevens ingeschakeld en zorgvuldige gewoonten rondom gevoelige invoer een redelijke basis. Voor bedrijven is het zakelijke niveau het verantwoordelijke startpunt.
Inzicht krijgen in de beveiligingsfuncties van elk AI-platform voordat u zich eraan committeert voor regelmatig gebruik, is het soort gedegen onderzoek dat u beschermt voordat een probleem ontstaat in plaats van erna.
Eén eerlijke opmerking is het waard om te maken: geen enkel digitaal systeem is volledig immuun voor inbreuken. De vraag is niet of een platform perfect veilig is, maar of het gegevensbescherming serieus genoeg neemt om het risico evenredig te maken aan de waarde die u krijgt van het gebruik ervan.
Privacyrisico's van AI-gegevens specifiek voor bedrijven
De inzet rondom privacyrisico's van AI-gegevens is hoger voor organisaties dan voor individuen, omdat de betrokken gegevens vaak toebehoren aan andere mensen, cliënten, werknemers en partners die er niet mee hebben ingestemd dat hun informatie wordt verwerkt door een AI-systeem van een derde partij.
Drie categorieën van zakelijke risico's springen er bovenuit.
Regelgevende blootstelling. Afhankelijk van uw branche en de regio's waarin u opereert, kan het delen van bepaalde soorten gegevens met AI-tools zonder de juiste verwerkersovereenkomsten u in overtreding brengen van de AVG, HIPAA, CCPA of andere toepasselijke regelgeving. Onwetendheid over de regelgeving is geen verdediging en de boetes in sommige jurisdicties zijn substantieel.
Cliënt- en contractuele verplichtingen. Veel zakelijke dienstverleningskantoren, advocatenkantoren, financiële adviseurs en adviesbureaus opereren onder geheimhoudingsovereenkomsten die het delen van cliëntinformatie met derden verbieden. Een AI-platform kwalificeert vrijwel zeker als een derde partij onder die overeenkomsten, en de meeste werknemers die AI-tools terloops gebruiken, controleren hun cliëntcontracten niet voordat zij dit doen.
Reputatierisico. Naast juridische blootstelling is er de eenvoudige reputatieschade die voortkomt uit het feit dat een cliënt ontdekt dat zijn gegevens zijn verwerkt via een AI-tool waar hij niet mee instemde. Dat gesprek is achteraf veel moeilijker te voeren dan het beleidsgesprek dat voorkomt dat het in de eerste plaats gebeurt.
Verantwoord AI-gebruik vanaf het begin in uw zakelijke workflow en functies inbouwen is aanzienlijk goedkoper dan het beheren van de gevolgen van een privacy-incident dat had kunnen worden vermeden met een duidelijk beleid en de juiste platformkeuze.

Waarom, hoe en welke: Betere gewoonten opbouwen rondom AI en privacy
Waarom verdienen privacyrisico's van AI-gegevens meer aandacht dan ze doorgaans krijgen? Omdat de adoptiecurve van AI-tools binnen organisaties veel sneller is verlopen dan de bestuurs- en beleidskaders die zijn ontworpen om ze te beheren. De meeste teams gebruiken dagelijks AI-tools die hun juridische en beveiligingsafdelingen nooit formeel hebben geëvalueerd.
Hoe bouwt u een praktische aanpak op zonder verlamd te raken? Begin met een eenvoudige persoonlijke regel: als u zich niet op uw gemak zou voelen bij het idee dat die informatie zichtbaar is voor een vreemde bij het AI-bedrijf, zet het dan niet in de prompt. Die regel elimineert de meeste invoer met hoog risico zonder dat u de volledige technische architectuur van elk platform dat u gebruikt hoeft te begrijpen.
Voor organisaties werkt een drie-niveaukader goed. Het groene niveau dekt taken die alleen openbaar beschikbare of niet-gevoelige informatie gebruiken, volledige toegang tot AI-tools toegestaan. Het gele niveau dekt interne, maar niet vertrouwelijke informatie, tools op enterprise-niveau vereist. Het rode niveau dekt gereguleerde, vertrouwelijke of door cliënten bezeten gegevens, AI-tools verboden of onderworpen aan speciale beoordeling vóór gebruik.
Welke praktijken maken het grootste verschil? Drie gewoonten springen boven alle andere uit. Ten eerste, meld u af voor het gebruik van trainingsgegevens op elk platform dat die optie biedt. Ten tweede, plak nooit ruwe gevoelige gegevens in een prompt wanneer u de situatie kunt beschrijven zonder de daadwerkelijke gegevens. Ten derde, behandel door AI gegenereerde resultaten als concepten die menselijke verificatie vereisen voordat er een consequente beslissing op wordt gebaseerd.
De gids voor verantwoorde AI-implementatie behandelt hoe u deze praktijken op organisatieniveau implementeert op een manier die daadwerkelijk gedrag verandert, in plaats van alleen maar in een beleidsdocument te staan dat niemand leest.

Het eindoordeel over privacyrisico's van AI-gegevens
Na te hebben doorlopen wat er wordt verzameld, wat u nooit moet delen, hoe platforms zich verhouden op het gebied van gegevensbescherming en hoe organisaties praktisch bestuur rondom deze tools kunnen opbouwen, is het volledige beeld van privacyrisico's van AI-gegevens er een dat serieus, maar beheersbaar is.
De technologie gaat niet weg en de productiviteitswaarde is reëel. Het antwoord is niet om AI-tools te vermijden, maar om ze te gebruiken met dezelfde intentionaliteit die u zou meebrengen naar elk systeem dat gevoelige informatie raakt. Weet wat het platform met uw gegevens doet. Meld u waar mogelijk af voor training. Houd werkelijk gevoelige informatie buiten tools op consumentenniveau. Bouw organisatorisch beleid op voordat incidenten dit noodzakelijk maken.
Privacyrisico's van AI-gegevens zijn geen reden om afstand te nemen van tools die uw werk aanzienlijk beter kunnen maken. Het is een reden om bedachtzaam vooruit te stappen, met uw ogen open en de juiste waarborgen op hun plaats.
Veelgestelde vragen
Wat is de 30%-regel voor AI?
De 30%-regel is een informele richtlijn die suggereert dat door AI gegenereerde inhoud niet meer dan 30% van elk eindresultaat zou mogen uitmaken, waarbij de resterende 70% afkomstig is van menselijke input, beoordeling en oordeel.
Het is geen officiële norm, maar het heeft aan kracht gewonnen als een praktische manier om overmatige afhankelijkheid van AI te voorkomen en tegelijkertijd efficiëntiewinsten te realiseren.
Waar waarschuwde Stephen Hawking voor met betrekking tot AI?
Stephen Hawking waarschuwde dat de ontwikkeling van volledige kunstmatige intelligentie het einde van het menselijk ras zou kunnen betekenen als de doelen niet zorgvuldig zijn afgestemd op menselijke waarden en als de groei niet goed wordt gecontroleerd.
Hij uitte specifiek zorg over de mogelijkheid dat AI zich autonoom zou ontwikkelen op manieren die het vermogen van de mensheid om te beheren of te begrijpen wat het doet overtreffen.
Wat zou u nooit aan ChatGPT moeten vertellen?
U zou nooit wachtwoorden, overheidsidentificatienummers, persoonlijke cliëntgegevens, bedrijfsgevoelige informatie, medische dossiers of financiële accountgegevens moeten delen met ChatGPT of welke consumenten-AI-tool dan ook.
De kernregel is eenvoudig: als de informatie toebehoort aan iemand anders of schade zou kunnen veroorzaken indien blootgesteld, houd het dan volledig buiten de prompt.
Hoe veilig zijn mijn gegevens bij AI?
De veiligheid van uw gegevens hangt af van welk platform u gebruikt, op welk abonnementsniveau u zit en welke privacy-instellingen u heeft ingeschakeld. Zakelijke abonnementen bieden over het algemeen sterkere bescherming dan gratis consumentenaccounts.
Geen enkel platform is volledig immuun voor inbreuken, maar het verschil tussen een consumentenaccount met standaardinstellingen en een zakelijk account met de juiste controles is groot genoeg om voor zakelijk gebruik van belang te zijn.
Kan AI uw informatie lekken?
Ja, AI-platforms kunnen gebruikersgegevens blootstellen door beveiligingsinbreuken, onbedoelde gegevensbewaring, menselijke beoordelingsprocessen of in zeldzame gevallen door resultaten die onbedoeld informatie van invoer van andere gebruikers naar boven brengen.
Het risico is niet gegarandeerd, maar het is reëel, en de beste bescherming is een combinatie van het kiezen van gerenommeerde platforms, het afmelden voor het gebruik van trainingsgegevens en het volledig buiten AI-tools houden van werkelijk gevoelige informatie.